
Zindeksowany, choć zablokowany przez Robots.txt: wszystko, co musisz wiedzieć
Opublikowany: 2021-07-01Jeśli masz w swojej witrynie strony zindeksowane przez Google, ale nie możesz ich zaindeksować, w Google Search Console (GSC) pojawi się komunikat „Zaindeksowany, choć zablokowany przez plik Robots.txt”.
Chociaż Google może wyświetlać te strony, nie wyświetla ich jako części stron wyników wyszukiwania dla ich docelowych słów kluczowych.
W takim przypadku stracisz możliwość uzyskania ruchu organicznego na tych stronach.
Jest to szczególnie ważne w przypadku stron generujących tysiące odwiedzających miesięcznie, tylko po to, by napotkać ten problem.
W tym momencie prawdopodobnie masz wiele pytań dotyczących tego komunikatu o błędzie. Dlaczego to otrzymałeś? Jak to się stało? I, co ważniejsze, jak to naprawić i odzyskać ruch, jeśli zdarzyło się to stronie, która miała już dobrą pozycję w rankingu.
Ten post odpowie na wszystkie te pytania i pokaże Ci, jak uniknąć ponownego wystąpienia tego problemu w Twojej witrynie.
Jak się dowiedzieć, czy w Twojej witrynie występuje ten problem?
Zwykle powinieneś otrzymać wiadomość e-mail od Google informującą o „problemie z pokryciem indeksu” w Twojej witrynie. Oto jak wygląda e-mail:
Wiadomość e-mail nie będzie określać dokładnych stron ani adresów URL, których dotyczy problem. Aby się dowiedzieć, musisz zalogować się do Google Search Console.
Jeśli nie otrzymałeś wiadomości e-mail, najlepiej jest zobaczyć ją na własne oczy, aby upewnić się, że Twoja witryna jest w doskonałym stanie.
Po zalogowaniu się do GSC przejdź do Raportu pokrycia indeksu, klikając opcję Pokrycie pod indeksem. Następnie na następnej stronie przewiń w dół, aby zobaczyć problemy zgłaszane przez GSC.
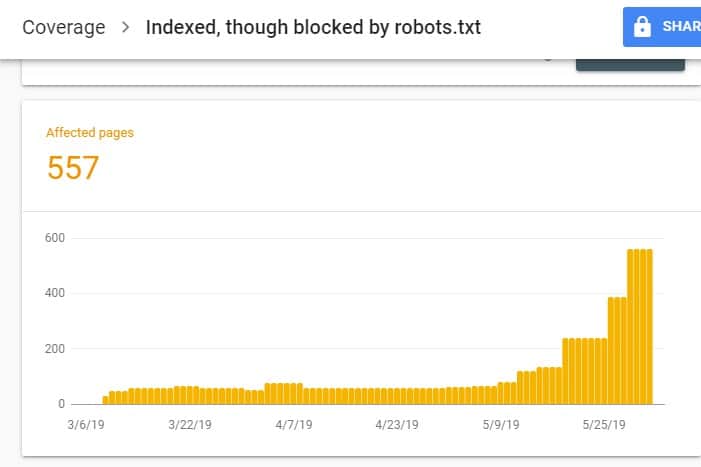
Plik „Zindeksowany, chociaż zablokowany przez plik robots.txt” jest oznaczony jako „Ważne z ostrzeżeniem”. Oznacza to, że nie ma nic złego w samym adresie URL, ale wyszukiwarki nie będą wyświetlać stron w wynikach wyszukiwania.
Dlaczego w Twojej witrynie występuje ten problem (i jak go naprawić)?
Zanim zaczniesz myśleć o rozwiązaniu, musisz najpierw wiedzieć, które strony wymagają indeksowania i muszą pojawiać się w wynikach wyszukiwania.
Możliwe, że adresy URL, które widzisz w GSC z problemem „Zindeksowany, choć zablokowany przez plik robots.txt”, nie mają na celu przyciągnięcia organicznego ruchu do Twojej witryny. Na przykład strony docelowe dla płatnych kampanii reklamowych. Dlatego naprawa stron może nie być warta twojego czasu i wysiłku.
Poniżej podajemy powody, dla których niektóre z Twoich stron mają ten problem i czy należy je naprawić:
Nie zezwalaj na regułę w pliku Robots.txt i metatagu Noindex w kodzie HTML strony
Najczęstszym powodem wystąpienia tego problemu jest włączenie przez Ciebie lub osobę zarządzającą Twoją witryną reguły Disallow dla tego konkretnego adresu URL w pliku robots.txt Twojej witryny i dodanie metatagu noindex do tego samego adresu URL.
Po pierwsze, właściciele witryn używają pliku robots.txt do informowania robotów wyszukiwarek o sposobie traktowania adresów URL witryn. W tym przypadku dodano regułę zakazu na stronach i folderach witryny w pliku robots.txt witryny.
Oto, co możesz zobaczyć po otwarciu pliku robots.txt swojej witryny:
Klient użytkownika: * Nie zezwalaj: /
W powyższym przykładzie ten wiersz kodu uniemożliwia wszystkim robotom indeksującym (*) indeksowanie stron Twojej witryny (Disallow) zawierającej Twoją stronę główną (/). W rezultacie wszystkie wyszukiwarki nie będą indeksować ani indeksować stron Twojej witryny.
Możesz edytować plik robots.txt, aby wyróżnić roboty internetowe (Googlebot, msnbot, magpie-crawler itp.) i określić, której strony lub stron mają one nie dotykać (/page1, /page2, /page3 itp.). ).
Jeśli jednak nie masz uprawnień administratora do swojego serwera, możesz uniemożliwić robotom wyszukiwarek indeksowanie stron witryny za pomocą tagu noindex.
Ta metoda ma taki sam efekt jak reguła zakazu w pliku robots.txt. Jednak zamiast wymieniać różne strony i foldery w Twojej witrynie w pliku robots.txt, których nie chcesz wyświetlać w SERP, musisz wprowadzić metatag noindex na każdej stronie witryny, której nie chcesz pojawiać się w wynikach wyszukiwania.
Jest to znacznie bardziej czasochłonny proces niż poprzednia metoda, ale zapewnia bardziej szczegółową kontrolę nad tym, który adres URL ma zostać zablokowany. Oznacza to również, że z Twojej strony istnieje mniejszy margines błędu.
Poprawka: ponownie problem w GSC pojawia się, gdy strony w Twojej witrynie mają regułę zakazu w pliku robots.txt i tag noindex.
Aby wyszukiwarki wiedziały, czy indeksować stronę, czy nie, powinny być w stanie zaindeksować ją z Twojej witryny. Ale jeśli uniemożliwisz wyszukiwarkom robienie tego za pomocą pliku robots.txt, nie będzie wiedziała, co zrobić z tą stroną.
Używając pliku robots.txt i tagu noindex do uzupełniania się i niekonkurowania ze sobą, Twoja witryna będzie miała znacznie jaśniejsze i bardziej bezpośrednie zasady, których muszą przestrzegać boty wyszukiwarek podczas obsługi swoich stron.
Aby to zrobić, musisz edytować plik robots.txt. Dla właścicieli witryn WordPress korzystanie z wtyczek SEO z edytorem robots.txt, takim jak Yoast SEO lub Rank Math, jest najwygodniejsze.
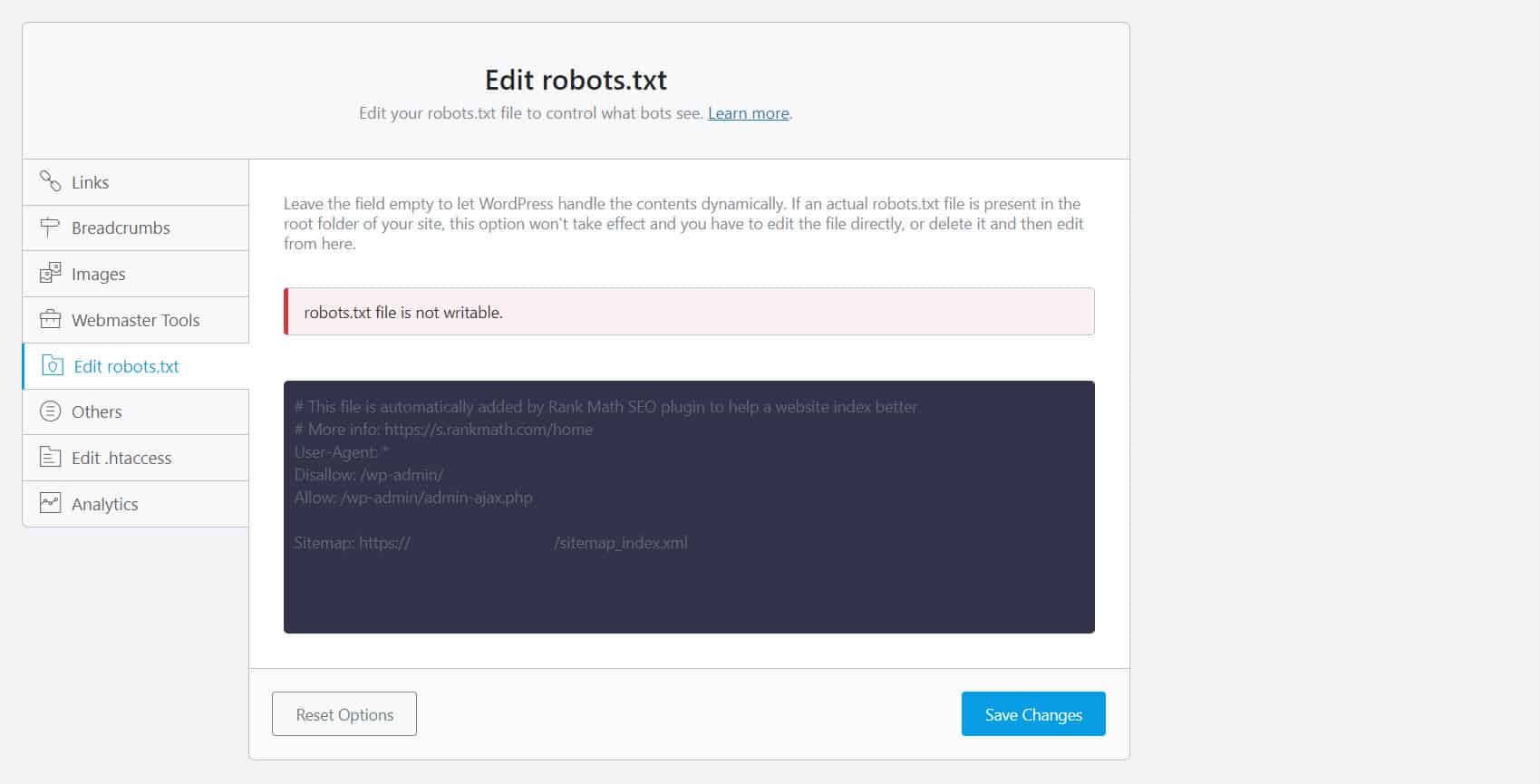

Jeśli plik robots.txt nie jest zapisywalny po Twojej stronie, musisz skontaktować się z dostawcą usług hostingowych, aby wprowadzić zmiany uprawnień do plików i folderów.
Innym sposobem jest zalogowanie się do klienta FTP lub menedżera plików dostawcy hostingu. Jest to preferowana metoda wśród programistów, ponieważ mają oni pełną kontrolę między innymi nad edycją pliku.
Nieprawidłowy format adresu URL
Adresy URL w Twojej witrynie, które w rzeczywistości nie są „stronami” w ścisłym tego słowa znaczeniu, mogą otrzymać komunikat „Zaindeksowany, choć zablokowany przez plik robots.txt”.
Na przykład https://example.com?s=what+is+seo to strona w witrynie, która wyświetla wyniki wyszukiwania zapytania „co to jest SEO”. Ten adres URL jest powszechny wśród witryn WordPress, w których funkcja wyszukiwania jest włączona w całej witrynie.
Poprawka: Zwykle nie ma potrzeby rozwiązywania tego problemu, zakładając, że adres URL jest nieszkodliwy i nie wpływa znacząco na ruch w sieci wyszukiwania.
Strony, których nie chcesz indeksować, mają wewnętrzne linki
Nawet jeśli na stronie, której nie chcesz indeksować, masz tag noindex, Google może potraktować je jako sugestie, a nie reguły. Jest to widoczne, gdy łączysz się ze stronami z dyrektywą noindex lub regułą zakazu na stronach w Twojej witrynie, które wyszukiwarki przemierzają i indeksują.
Dlatego możesz zobaczyć te strony pojawiające się w SERPach, nawet jeśli nie chcesz.
Poprawka : Musisz usunąć linki prowadzące do tej konkretnej strony i zamiast tego prowadzić je do podobnej strony.
Aby to zrobić, musisz zidentyfikować jego wewnętrzne linki, przeprowadzając audyt SEO za pomocą narzędzia takiego jak Screaming Frog (bezpłatny dla witryn z 500 adresami URL) lub Ahrefs Webmaster Tools (dużo lepsza bezpłatna alternatywa), aby zidentyfikować strony, które prowadzą do zablokowanych stron.
Korzystając z Ahrefs, po uruchomieniu audytu przejdź do Raporty > Strony wewnętrzne. Znajdź strony, które zostały zablokowane dla robotów indeksujących i nie zindeksowane, i zobacz, które strony prowadzą do nich w kolumnie Liczba linków.
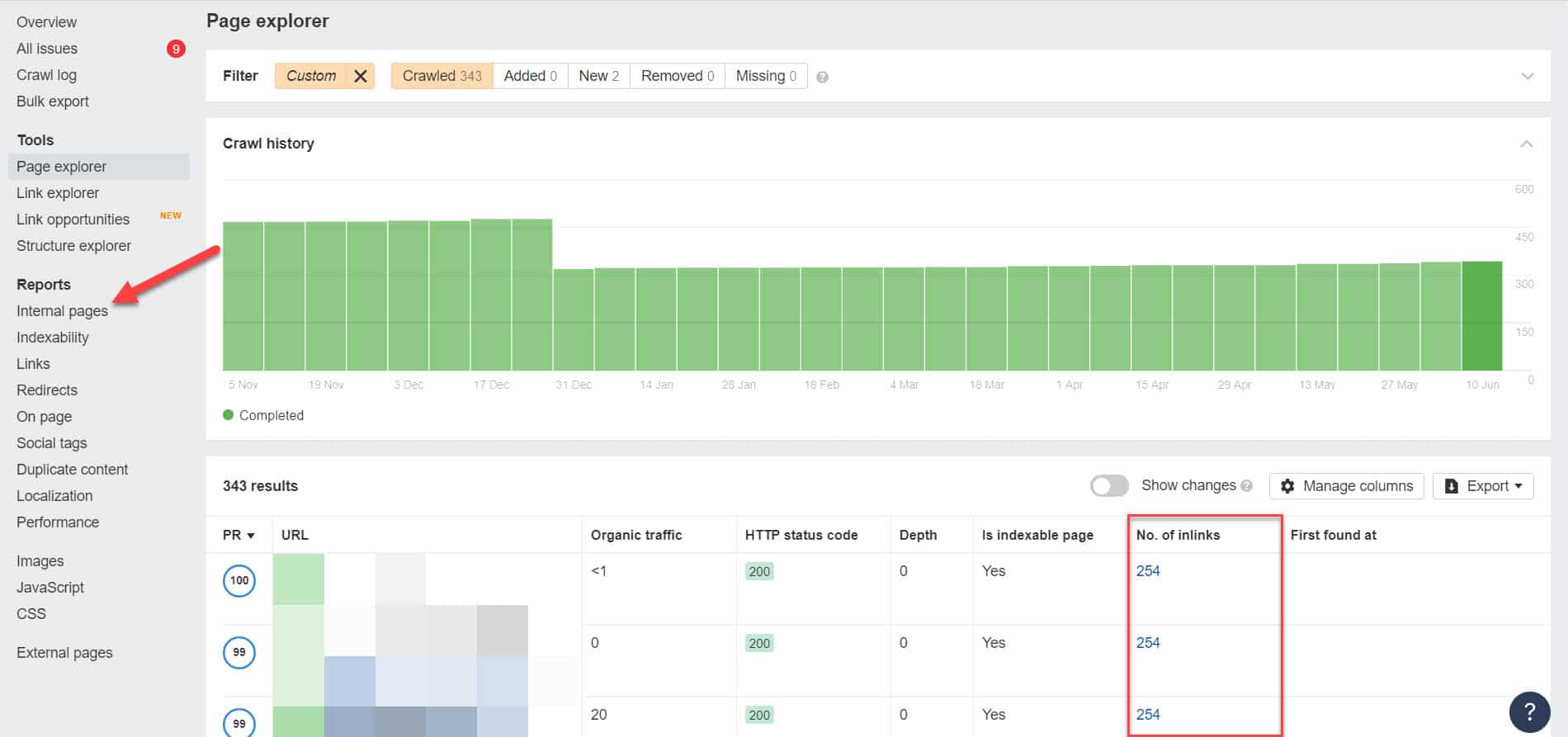
W tym miejscu edytuj linki z tych stron pojedynczo. Możesz też zastąpić je linkiem do Twojej strony z tagiem noindex.
Wskazywanie na łańcuch przekierowań
Jeśli link w Twojej witrynie wskazuje na niekończący się strumień przekierowań, Googlebot przestanie przechodzić przez każdy link, zanim znajdzie rzeczywisty adres URL strony.
Te łańcuchy przekierowań mogą również powodować problemy z powielonymi treściami, które mogą powodować większe problemy z SEO w dalszej kolejności. Jedynym sposobem rozwiązania tego problemu jest zidentyfikowanie preferowanej i kanonicznej strony za pomocą tagu kanonicznego, aby firma Google wiedziała, którą z wielu stron należy zaindeksować i zaindeksować.
Weź również pod uwagę, że linkowanie do przekierowania zamiast strony kanonicznej powoduje zużycie budżetu indeksowania. Jeśli link przekierowujący wskazuje na wiele przekierowań, nie możesz wykorzystać budżetu indeksowania na stronach, które mają znaczenie w Twojej witrynie. Zanim dotrze do najważniejszych stron, po pewnym czasie Google nie będzie w stanie prawidłowo ich przeszukiwać i indeksować.
Poprawka: wyeliminuj przekierowania ze swojej witryny i zamiast tego umieść link do strony kanonicznej.
Korzystając ponownie z Narzędzi dla webmasterów Ahrefs, możesz wyświetlić swoje przekierowania na stronie Narzędzia > Eksplorator linków. Następnie przefiltruj wyniki, aby pokazać tylko linki przekierowujące w Twojej witrynie.
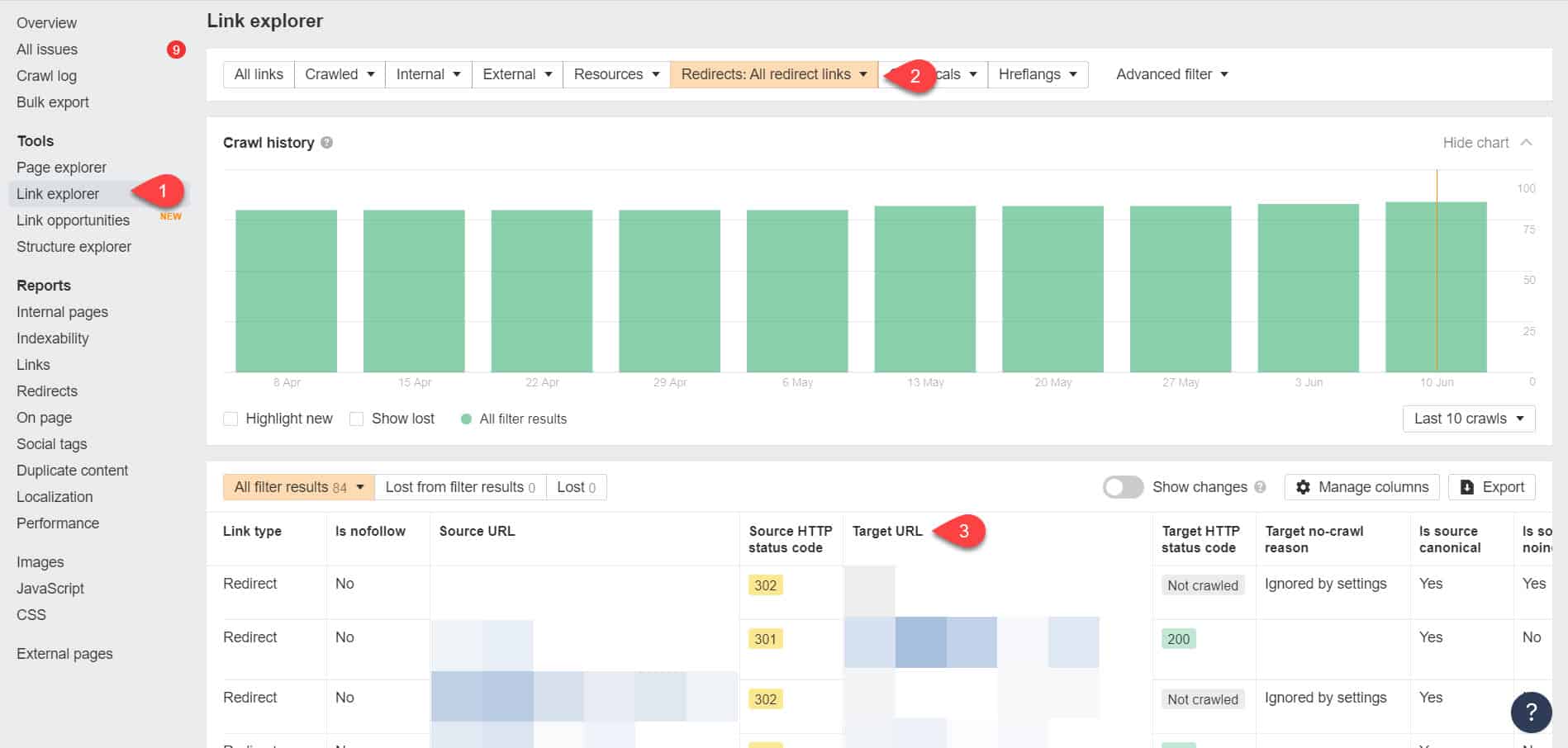
Na podstawie wyników określ, które linki tworzą niekończący się łańcuch przekierowań. Następnie przerwij łańcuch, znajdując odpowiednią stronę, do której powinna prowadzić każda strona z linkiem do przekierowań.
Co zrobić po rozwiązaniu tego problemu
Po zaimplementowaniu powyższych rozwiązań na ważnych stronach z problemem „Zindeksowany, chociaż zablokowany przez plik robots.txt” musisz zweryfikować zmiany, aby Google Search Console mogła je oznaczyć jako rozwiązane.
Wracając do Raportu o stanie indeksu w GSC, kliknij łącza z tym rozwiązanym problemem. Na następnym ekranie kliknij przycisk Sprawdź poprawność.
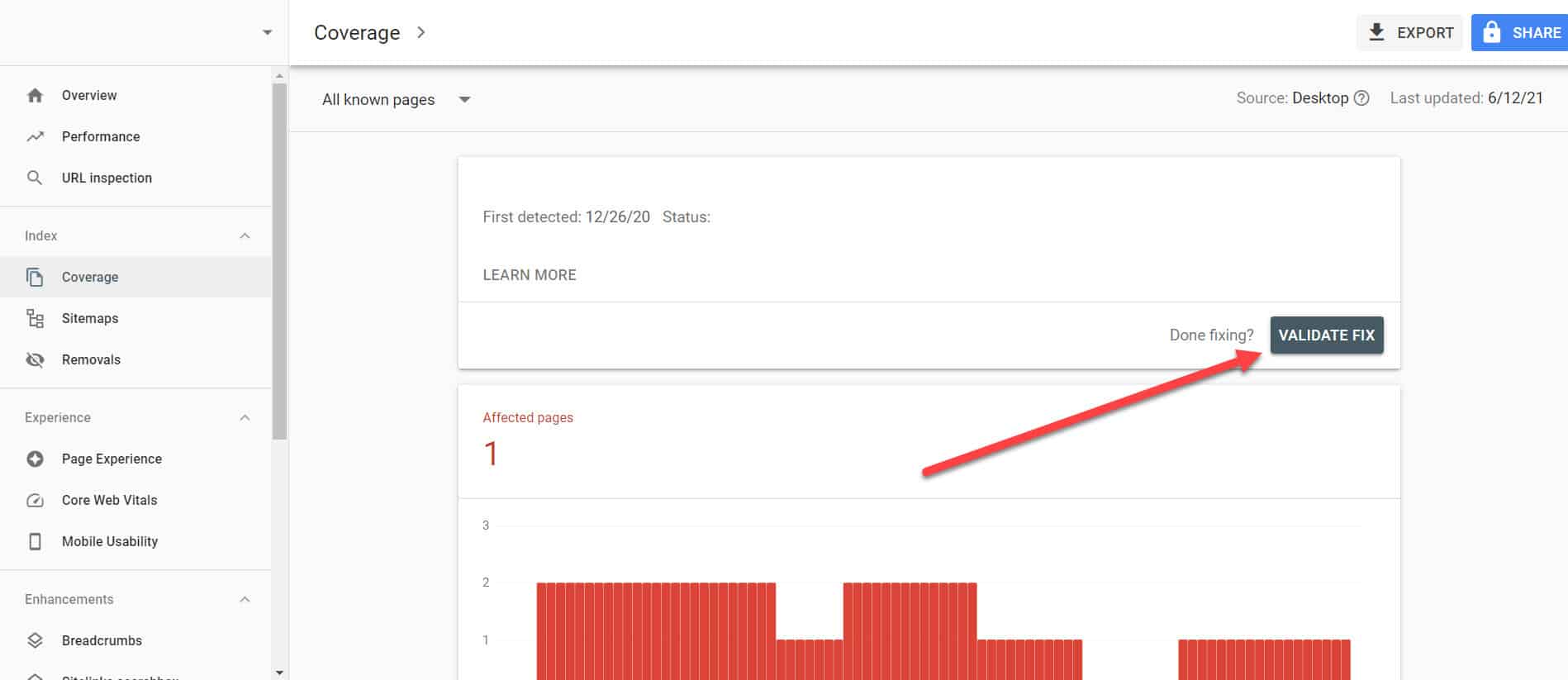
Spowoduje to poproszenie Google o sprawdzenie, czy na stronie nie ma już problemu.
Wniosek
W przeciwieństwie do innych problemów wykrytych przez Google Search Console, „Zindeksowany, choć zablokowany przez plik robots.txt” może wydawać się kroplą w morzu. Jednak te spadki mogą kumulować się w potok problemów dla całej witryny, co uniemożliwi jej generowanie ruchu organicznego.
Postępując zgodnie z powyższymi wskazówkami dotyczącymi rozwiązywania problemów na najważniejszych stronach, możesz zapobiec utracie cennego ruchu w witrynie, optymalizując ją pod kątem prawidłowego indeksowania i indeksowania przez Google.