
Indexado, embora bloqueado pelo Robots.txt: tudo o que você precisa saber
Publicados: 2021-07-01Se você tiver páginas em seu site que o Google indexou, mas não pode rastrear, você receberá uma mensagem "Indexada, embora bloqueada por Robots.txt" em seu Google Search Console (GSC).
Embora o Google possa visualizar essas páginas, ele não as mostrará como parte das páginas de resultados do mecanismo de pesquisa para suas palavras-chave de destino.
Se for esse o caso, você perderá a oportunidade de obter tráfego orgânico para essas páginas.
Isso é especialmente crucial para páginas que geram milhares de visitantes orgânicos mensais apenas para encontrar esse problema.
Neste ponto, você provavelmente tem muitas perguntas sobre essa mensagem de erro. Por que você recebeu? Como isso aconteceu? E, mais importante, como você pode corrigi-lo e recuperar o tráfego se isso aconteceu com uma página que já estava bem ranqueada.
Este post responderá a todas essas perguntas e mostrará como evitar que esse problema aconteça novamente em seu site.
Como saber se seu site tem esse problema
Normalmente, você deve receber um e-mail do Google informando sobre um “problema de cobertura de índice” em seu site. Veja como é o e-mail:
O e-mail não especificará quais são as páginas ou URLs afetadas exatas. Você terá que fazer login no Google Search Console para descobrir por si mesmo.
Se você não recebeu um e-mail, é melhor ver por si mesmo para ter certeza de que seu site está em ótima forma.
Ao fazer login no GSC, acesse o Relatório de Cobertura do Índice clicando em Cobertura em Índice. Em seguida, na próxima página, role para baixo para ver os problemas relatados pelo GSC.
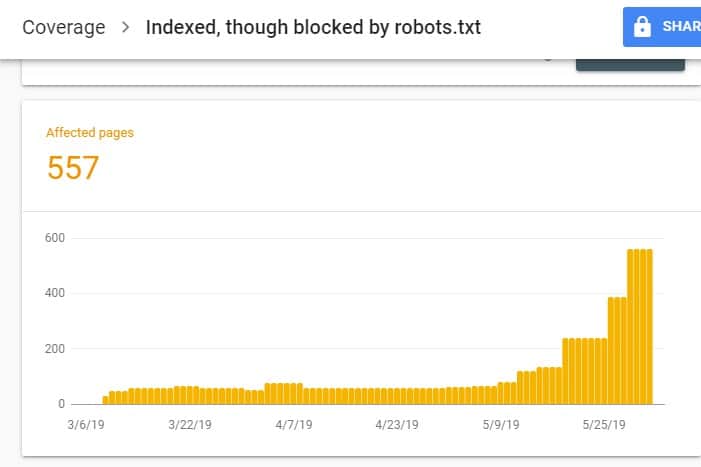
O "Indexado, embora bloqueado por robots.txt" está rotulado em "Válido com aviso". Isso significa que não há nada de errado com o URL em si, mas os mecanismos de pesquisa não mostrarão a(s) página(s) nos resultados do mecanismo de pesquisa.
Por que seu site tem esse problema (e como corrigi-lo)?
Antes de começar a pensar em uma solução, você deve saber primeiro quais páginas precisam ser indexadas e devem aparecer nos resultados da pesquisa.
É possível que os URLs que você vê no GSC com o problema "Indexado, embora bloqueado por robots.txt" não sejam destinados a direcionar tráfego orgânico para seu site. Por exemplo, páginas de destino para suas campanhas de anúncios pagos. Portanto, consertar as páginas pode não valer o seu tempo e esforço.
Veja abaixo os motivos pelos quais algumas de suas páginas apresentam esse problema e se você deve ou não corrigi-las:
Regra de proibição em seu Robots.txt e Noindex Meta Tag no HTML da página
O motivo mais comum pelo qual esse problema ocorre é quando você ou alguém que gerencia seu site ativa a regra Não permitir para esse URL específico no robots.txt do seu site e adiciona a metatag noindex no mesmo URL.
Primeiro, os proprietários de sites usam o robots.txt para informar os rastreadores de mecanismos de pesquisa sobre como tratar os URLs de seu site. Nesse caso, você adicionou a Regra de não permissão nas páginas e pastas do seu site no robots.txt do seu site.
Veja o que você pode ver ao abrir o arquivo robots.txt do seu site:
Agente do usuário: * Não permitir: /
No exemplo acima, esta linha de código impede que todos os rastreadores da Web (*) rastreiem as páginas do seu site (Disallow) incluindo sua página inicial (/). Como resultado, todos os mecanismos de pesquisa não rastrearão nem indexarão as páginas do seu site.
Você pode editar o robots.txt para destacar rastreadores da Web (Googlebot, msnbot, magpie-crawler etc.) e especificar em qual página ou páginas você não deseja que os rastreadores toquem (/page1, /page2, /page3 etc.). ).
No entanto, se você não tiver acesso root ao seu servidor, poderá impedir que os bots do mecanismo de pesquisa indexem as páginas do seu site usando a tag noindex.
Este método tem o mesmo efeito que a regra de não permissão em robots.txt. No entanto, em vez de listar as diferentes páginas e pastas do seu site em um arquivo robots.txt que você deseja evitar que apareça nos SERPs, você deve inserir a metatag noindex em cada página do seu site que você não deseja para aparecer nos resultados da pesquisa.
Este é um processo muito mais demorado do que o método anterior, mas oferece um controle mais granular sobre qual URL bloquear. Isso também significa que há uma margem menor de erro de sua parte.
Correção: novamente, o problema no GSC surge quando as páginas do seu site têm uma regra de não permissão no arquivo robots.txt e uma tag noindex.
Para que os mecanismos de pesquisa saibam se devem indexar uma página ou não, eles devem ser capazes de rastreá-la do seu site. Mas se você impedir que os mecanismos de pesquisa façam isso por meio do seu robots.txt, ele não saberá o que fazer com essa página.
Ao usar o robots.txt e a tag noindex para complementar e não competir entre si, seu site terá regras muito mais claras e diretas para os bots dos mecanismos de busca seguirem ao tratar suas páginas.
Para fazer isso, você deve editar seu arquivo robots.txt. Para proprietários de sites WordPress, usar plugins de SEO com um editor robots.txt como Yoast SEO ou Rank Math é o mais conveniente.

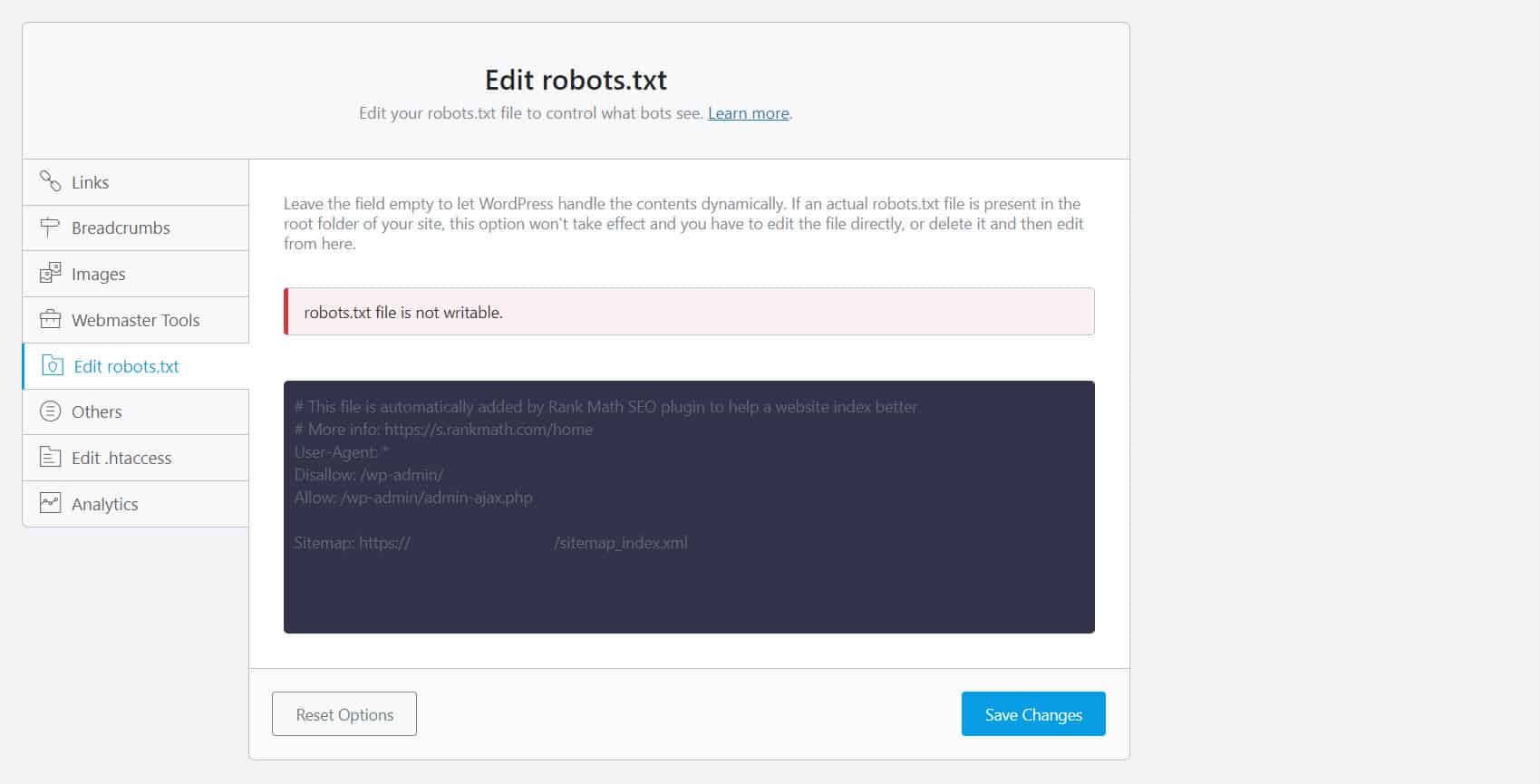
Se o robots.txt não for gravável do seu lado, você deve entrar em contato com seu provedor de hospedagem para fazer alterações de permissão em seus arquivos e pastas.
Outra maneira é fazer login no seu cliente FTP ou no Gerenciador de Arquivos do seu provedor de hospedagem. Este é o método preferido entre os desenvolvedores porque eles têm controle total sobre como editar o arquivo, entre outras coisas.
Formato de URL incorreto
URLs em seu site que não são realmente “páginas” no sentido mais estrito podem receber a mensagem “Indexado, embora bloqueado por robots.txt”.
Por exemplo, https://example.com?s=what+is+seo é uma página em um site que mostra os resultados da pesquisa para a consulta "o que é seo". Essa URL é predominante entre os sites do WordPress em que o recurso de pesquisa está ativado em todo o site.
Correção: Normalmente, não há necessidade de resolver esse problema, assumindo que o URL é inofensivo e não está afetando profundamente seu tráfego de pesquisa.
As páginas que você não deseja indexar têm links internos
Mesmo que você tenha uma tag noindex na página que não deseja indexar, o Google pode tratá-las como sugestões em vez de regras. Isso fica evidente quando você vincula a páginas com a diretiva noindex ou a regra de não permitir em páginas em seu site que os mecanismos de pesquisa rastreiam e indexam.
Portanto, você pode ver essas páginas aparecendo em SERPs mesmo que não queira.
Correção : Você deve remover os links que apontam para esta página específica e direcioná-los para uma página semelhante.
Para fazer isso, você deve identificar seus links internos executando uma auditoria de SEO usando uma ferramenta como Screaming Frog (gratuita para sites com 500 URLs) ou Ahrefs Webmaster Tools (uma alternativa gratuita muito melhor) para identificar quais páginas estão vinculadas às suas páginas bloqueadas.
Usando o Ahrefs, vá para Relatórios > Páginas internas após executar uma auditoria. Encontre as páginas que você bloqueou de rastreadores da web e noindexed e veja quais páginas estão vinculadas a elas na coluna No. of Inlinks.
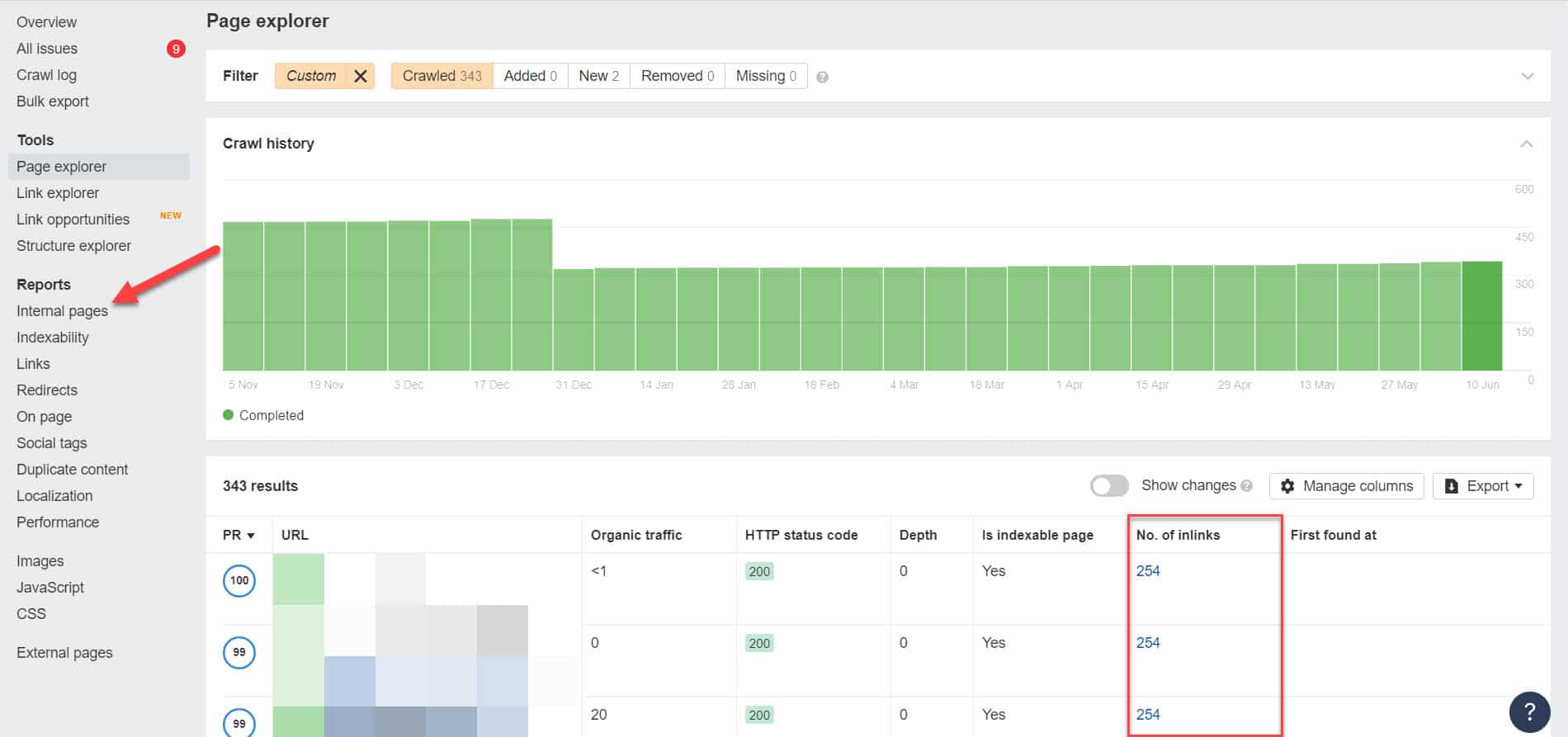
A partir daqui, edite os links dessas páginas, um de cada vez. Ou você pode substituí-los por um link para sua página com uma tag noindex.
Apontando para uma cadeia de redirecionamento
Se um link em seu site apontar para um fluxo interminável de redirecionamentos, o Googlebot deixará de passar por cada link antes de encontrar o URL real da página.
Essas cadeias de redirecionamento também podem causar problemas de conteúdo duplicado que podem causar maiores problemas de SEO no futuro. A única maneira de resolver isso é identificando sua página preferida e canônica com a tag canônica para que o Google saiba qual página entre muitas deve rastrear e indexar.
Além disso, considere que o link para redirecionar em vez da página canônica consome seu orçamento de rastreamento. Se o link de redirecionamento apontar para vários redirecionamentos, você não poderá usar seu orçamento de rastreamento em páginas importantes em seu site. Quando chegar às páginas mais importantes, o Google não poderá rastreá-las e indexá-las adequadamente após um período.
Correção: Elimine os links de redirecionamento do seu site e vincule-os à página canônica.
Usando as Ferramentas do Ahrefs para webmasters novamente, você pode visualizar seus links de redirecionamento na página Ferramentas > Explorador de links. Em seguida, filtre os resultados para mostrar apenas links de redirecionamento em seu site.
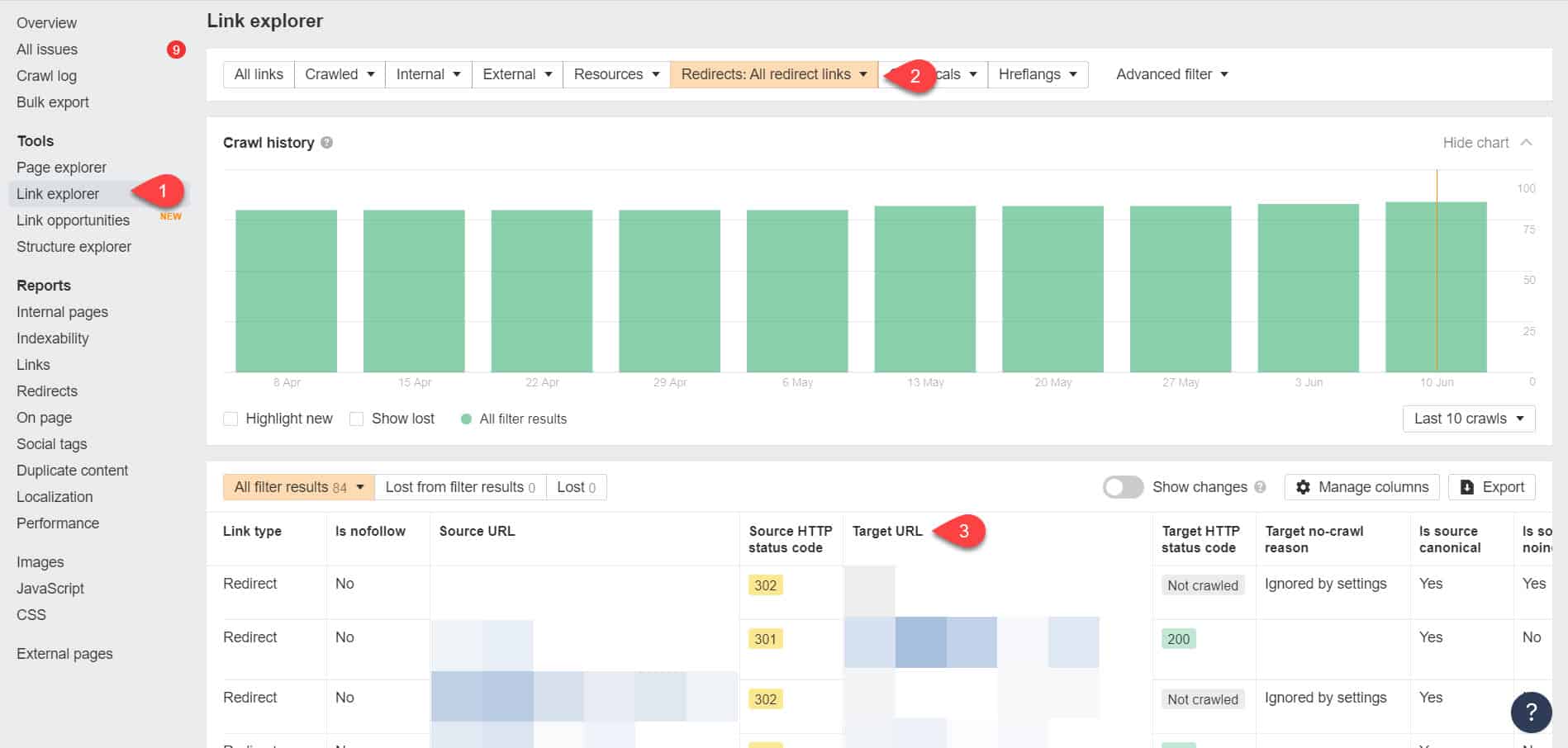
A partir dos resultados, identifique quais links formam uma cadeia de redirecionamento sem fim. Em seguida, quebre a cadeia encontrando a página correta à qual cada página vinculada aos redirecionamentos deve vincular.
O que fazer depois de corrigir esse problema
Depois de implementar as soluções acima para páginas importantes com o problema "Indexado, embora bloqueado por Robots.txt", você precisa verificar as alterações para que o Google Search Console possa marcá-las como resolvidas.
Voltando ao Relatório de cobertura de índice no GSC, clique nos links com esse problema que você corrigiu. Na próxima tela, clique no botão Validar Correção.
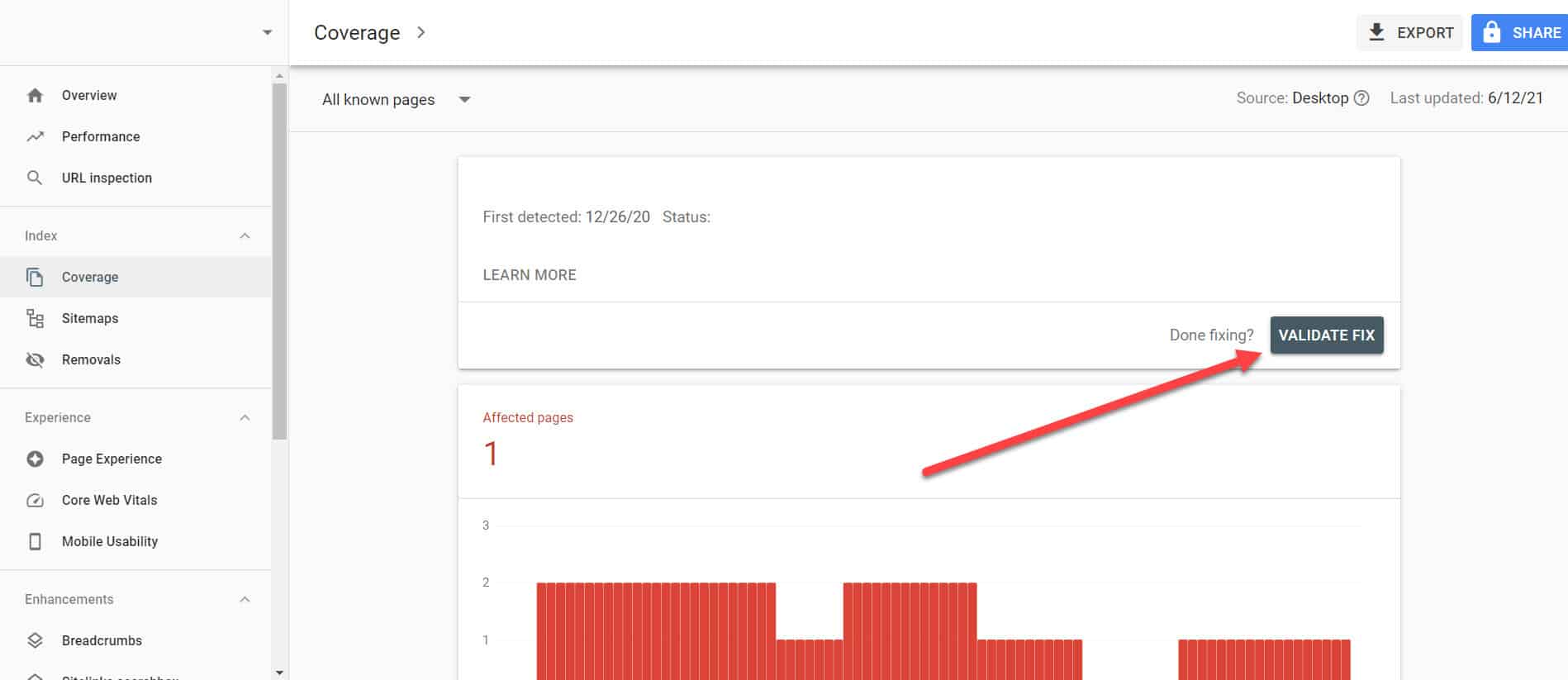
Isso solicitará que o Google verifique se a página não apresenta mais o problema.
Conclusão
Ao contrário de outros problemas descobertos pelo Google Search Console, “Indexado, embora bloqueado por robots.txt” pode parecer uma gota no balde. No entanto, essas quedas podem se acumular em uma torrente de problemas para todo o seu site que o impedirão de gerar tráfego orgânico.
Ao seguir as diretrizes acima sobre como resolver o problema em suas páginas mais importantes, você pode evitar que seu site perca tráfego valioso otimizando seu site para que o Google rastreie e indexe corretamente.