
Indexado, aunque bloqueado por Robots.txt: todo lo que necesita saber
Publicado: 2021-07-01Si tiene páginas en su sitio web que Google indexó pero no puede rastrear, recibirá un mensaje "Indexado, aunque bloqueado por robots.txt" en su Google Search Console (GSC).
Si bien Google puede ver estas páginas, no las mostrará como parte de las páginas de resultados del motor de búsqueda para sus palabras clave objetivo.
Si este es el caso, perderá la oportunidad de obtener tráfico orgánico para estas páginas.
Esto es especialmente crucial para las páginas que generan miles de visitantes orgánicos mensuales solo para encontrar este problema.
En este punto, probablemente tenga muchas preguntas sobre este mensaje de error. ¿Por qué lo recibiste? ¿Como paso? Y, lo que es más importante, cómo puedes solucionarlo y recuperar el tráfico si esto le sucede a una página que ya estaba bien clasificada.
Esta publicación responderá todas estas preguntas y le mostrará cómo evitar que este problema vuelva a ocurrir en su sitio.
Cómo saber si su sitio tiene este problema
Normalmente, debería recibir un correo electrónico de Google informándole de un "problema de cobertura de índice" en su sitio. Así es como se ve el correo electrónico:
El correo electrónico no especificará cuáles son las páginas o URL afectadas exactas. Tendrá que iniciar sesión en su Google Search Console para averiguarlo usted mismo.
Si no recibiste un correo electrónico, es mejor que lo veas por ti mismo para asegurarte de que tu sitio esté en óptimas condiciones.
Al iniciar sesión en GSC, vaya al Informe de cobertura del índice haciendo clic en Cobertura en Índice. Luego, en la página siguiente, desplácese hacia abajo para ver los problemas que informa GSC.
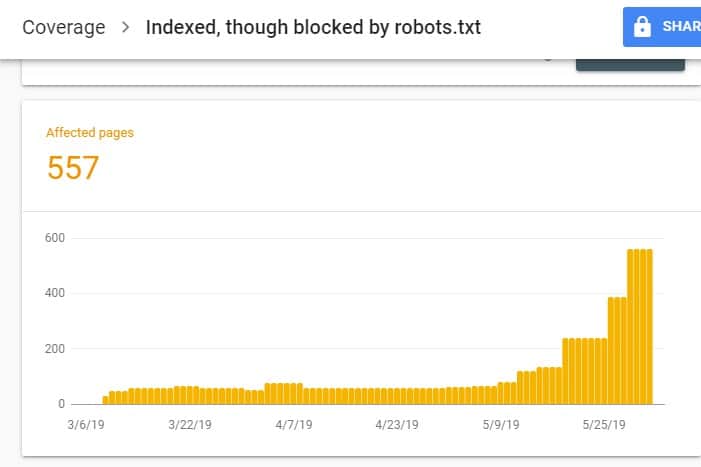
El "Indexado, aunque bloqueado por robots.txt" está etiquetado como "Válido con advertencia". Esto significa que no hay nada malo con la URL per se, pero los motores de búsqueda no mostrarán las páginas en los resultados de los motores de búsqueda.
¿Por qué su sitio tiene este problema (y cómo solucionarlo)?
Antes de comenzar a pensar en una solución, primero debe saber qué páginas deben indexarse y deben aparecer en los resultados de búsqueda.
Es posible que las URL que ve en GSC con el problema "Indexado, aunque bloqueado por robots.txt" no estén destinadas a atraer tráfico orgánico a su sitio. Por ejemplo, páginas de destino para sus campañas publicitarias pagas. Por lo tanto, arreglar las páginas puede no valer su tiempo y esfuerzo.
A continuación se muestran las razones por las que algunas de sus páginas tienen este problema y si debe solucionarlas o no:
Regla de rechazo en su Robots.txt y metaetiqueta Noindex en el HTML de la página
La razón más común por la que ocurre este problema es cuando usted o alguien que administra su sitio habilita la regla No permitir para esa URL específica en el archivo robots.txt de su sitio y agrega la metaetiqueta noindex en la misma URL.
En primer lugar, los propietarios de los sitios utilizan robots.txt para informar a los rastreadores de los motores de búsqueda sobre cómo tratar las URL de su sitio. En este caso, agregó la Regla de rechazo en las páginas y carpetas de su sitio en el archivo robots.txt de su sitio web.
Esto es lo que puede ver cuando abre el archivo robots.txt de su sitio:
Agente de usuario: * No permitir: /
En el ejemplo anterior, esta línea de código evita que todos los rastreadores web (*) rastreen las páginas de su sitio (no permitir), incluida su página de inicio (/). Como resultado, todos los motores de búsqueda no rastrearán ni indexarán las páginas de su sitio.
Puede editar robots.txt para destacar a los rastreadores web (Googlebot, msnbot, urraca-rastreador, etc.) y especificar qué página o páginas no desea que toquen los rastreadores (/página1, /página2, /página3, etc. ).
Sin embargo, si no tiene acceso raíz a su servidor, puede evitar que los robots de los motores de búsqueda indexen las páginas de su sitio usando la etiqueta noindex.
Este método tiene el mismo efecto que la regla de rechazo en robots.txt. Sin embargo, en lugar de enumerar las diferentes páginas y carpetas de su sitio en un archivo robots.txt que desea evitar que aparezcan en las SERP, debe ingresar la metaetiqueta noindex en cada página de su sitio que no desee. para aparecer en los resultados de búsqueda.
Este es un proceso que requiere mucho más tiempo que el método anterior, pero le brinda un control más granular sobre qué URL bloquear. Esto también significa que hay un margen de error más bajo de su parte.
Solución: nuevamente, el problema en GSC surge cuando las páginas de su sitio tienen una regla de rechazo en el archivo robots.txt y una etiqueta noindex.
Para que los motores de búsqueda sepan si indexar una página o no, deberían poder rastrearla desde su sitio. Pero si evita que los motores de búsqueda lo hagan a través de su archivo robots.txt, no sabrá qué hacer con esa página.
Al usar robots.txt y la etiqueta noindex para complementar y no competir entre sí, su sitio tendrá reglas mucho más claras y directas para que los robots de los motores de búsqueda las sigan cuando traten sus páginas.
Para hacer esto, debe editar su archivo robots.txt. Para los propietarios de sitios de WordPress, usar complementos de SEO con un editor de robots.txt como Yoast SEO o Rank Math es lo más conveniente.

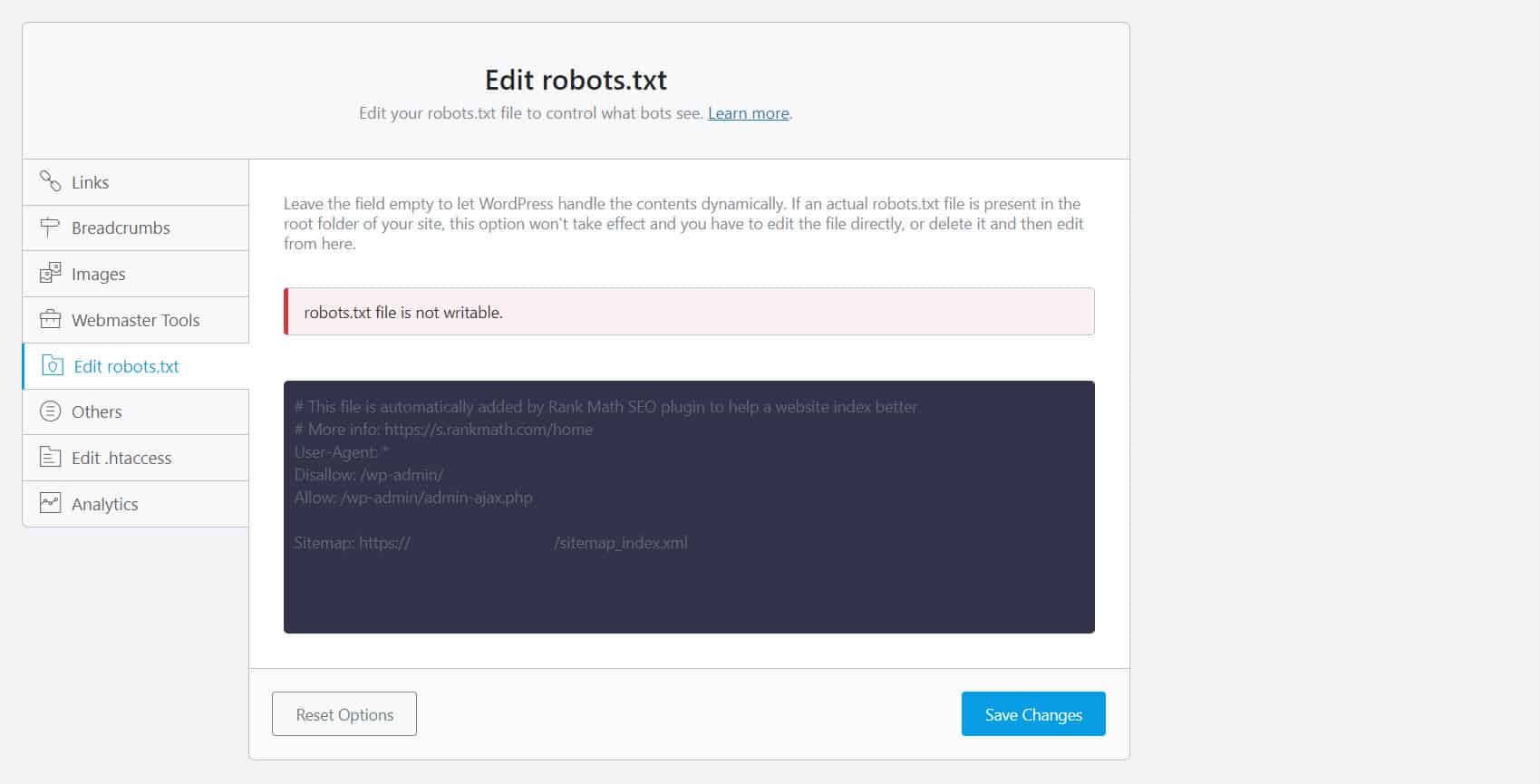
Si no se puede escribir en el archivo robots.txt, debe comunicarse con su proveedor de alojamiento para realizar cambios de permisos en sus archivos y carpetas.
Otra forma es iniciar sesión en su cliente FTP o en el Administrador de archivos de su proveedor de alojamiento. Este es el método preferido entre los desarrolladores porque tienen control total sobre cómo editar el archivo, entre otras cosas.
Formato de URL incorrecto
Las URL de su sitio que no son realmente "páginas" en el sentido más estricto pueden recibir el mensaje "Indexado, aunque bloqueado por robots.txt".
Por ejemplo, https://example.com?s=what+is+seo es una página en un sitio que muestra los resultados de búsqueda para la consulta "qué es seo". Esta URL prevalece entre los sitios de WordPress donde la función de búsqueda está habilitada en todo el sitio.
Solución: normalmente, no hay necesidad de abordar este problema, suponiendo que la URL sea inofensiva y no afecte profundamente su tráfico de búsqueda.
Las páginas que no desea indexar tienen enlaces internos
Incluso si no tiene una etiqueta de índice en la página que no desea indexar, Google puede tratarlas como sugerencias en lugar de reglas. Esto es evidente cuando se vincula a páginas con la directiva noindex o la regla de rechazo en las páginas de su sitio que los motores de búsqueda rastrean e indexan.
Por lo tanto, es posible que vea que estas páginas aparecen en las SERP incluso si no lo desea.
Solución : debe eliminar los enlaces que apuntan a esta página en particular y llevarlos a una página similar en su lugar.
Para hacer esto, debe identificar sus enlaces internos ejecutando una auditoría de SEO utilizando una herramienta como Screaming Frog (gratis para sitios web con 500 URL) o Ahrefs Webmaster Tools (una alternativa gratuita mucho mejor) para identificar qué páginas enlazan con sus páginas bloqueadas.
Con Ahrefs, vaya a Informes > Páginas internas después de realizar una auditoría. Encuentre las páginas que bloqueó de los rastreadores web y no indexó y vea qué páginas se vinculan a ellas en la columna Número de enlaces internos.
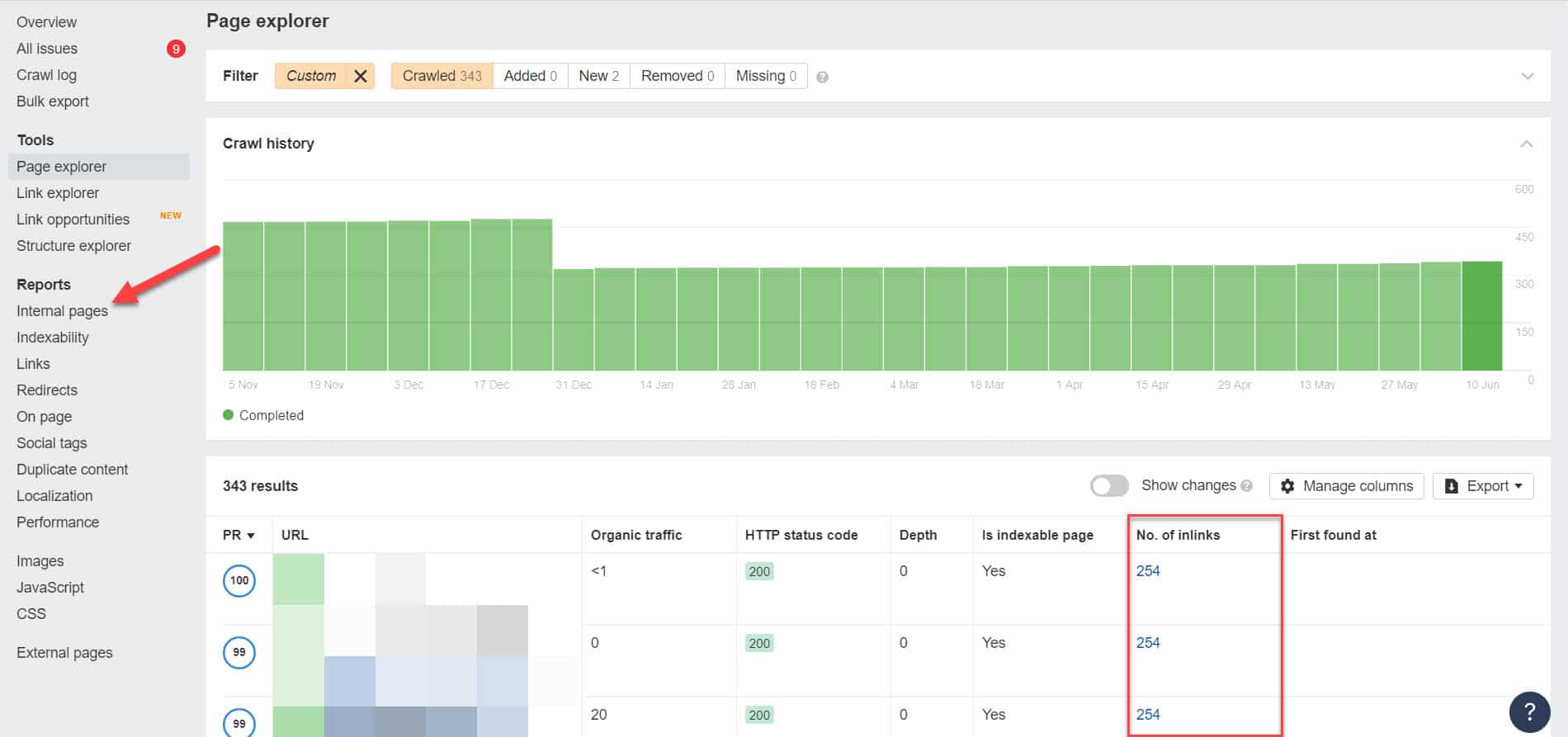
Desde aquí, edite los enlaces de estas páginas de uno en uno. O puede reemplazarlos con un enlace a su página con una etiqueta noindex.
Apuntando a una cadena de redirección
Si un enlace en su sitio apunta a un flujo interminable de redireccionamientos, Googlebot dejará de pasar por cada enlace antes de encontrar la URL real de la página.
Estas cadenas de redireccionamiento también podrían causar problemas de contenido duplicado que podrían causar mayores problemas de SEO en el futuro. La única forma de resolver esto es identificando su página preferida y canónica con la etiqueta canónica para que Google sepa qué página entre muchas debe rastrear e indexar.
Además, considere que vincular para redirigir en lugar de la página canónica consume su presupuesto de rastreo. Si el enlace de redireccionamiento apunta a múltiples redireccionamientos, no podrá usar su presupuesto de rastreo en las páginas que son importantes en su sitio. Para cuando llegue a las páginas más importantes, Google no podrá rastrearlas ni indexarlas correctamente después de un período.
Solución: elimine los enlaces de redireccionamiento de su sitio y, en su lugar, vincule a la página canónica.
Usando Ahrefs Webmaster Tools de nuevo, puedes ver tus enlaces de redirección en la página Herramientas > Explorador de enlaces. Luego filtre los resultados para mostrarle solo los enlaces de redirección en su sitio.
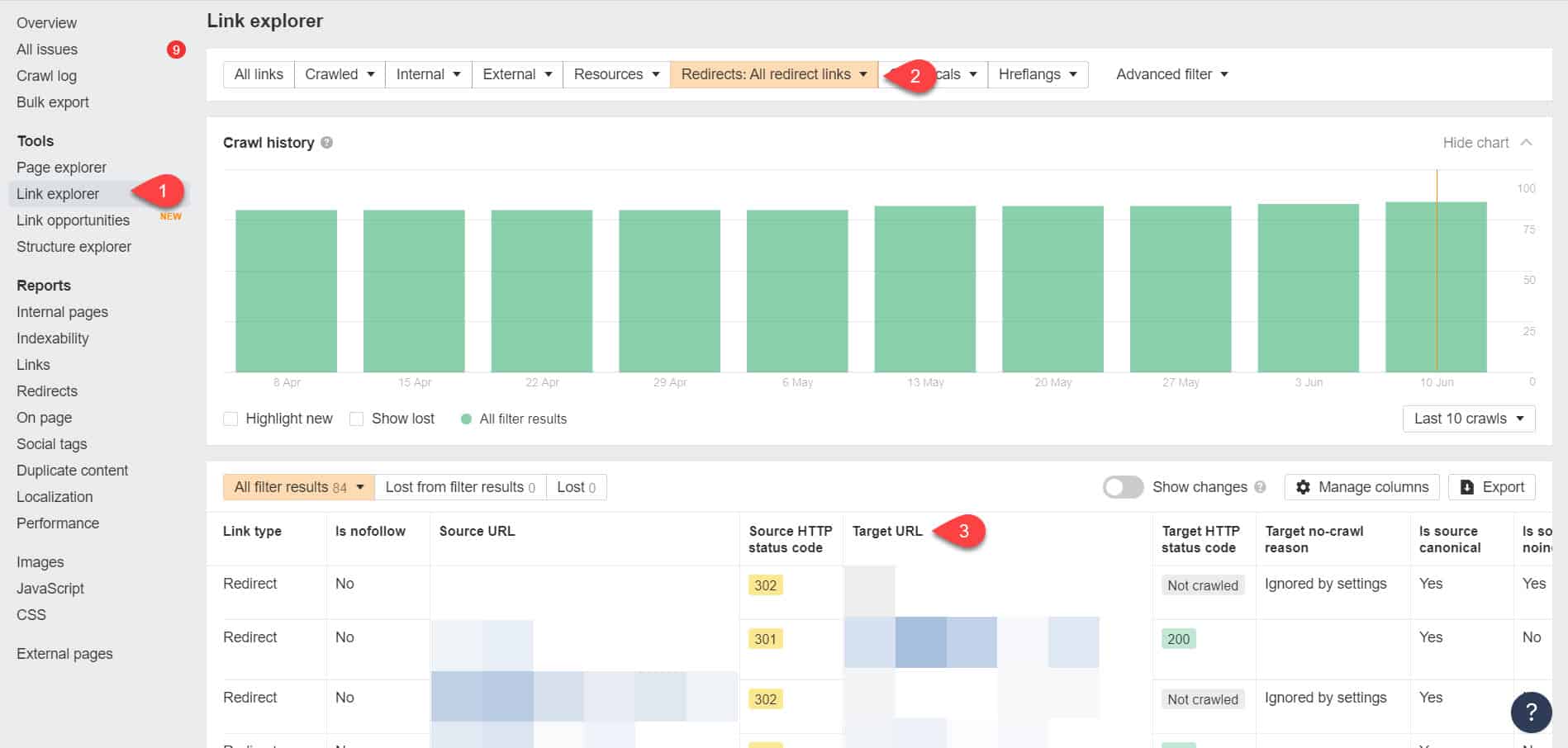
A partir de los resultados, identifique qué enlaces forman una cadena de redirección sin fin. Luego rompa la cadena encontrando la página correcta a la que debe vincular cada página que se vincule a los redireccionamientos.
Qué hacer después de solucionar este problema
Una vez que haya implementado las soluciones anteriores en páginas importantes con el problema "Indexado, aunque bloqueado por Robots.txt", debe verificar los cambios para que Google Search Console pueda marcarlos como resueltos.
Volviendo al Informe de cobertura de índice en GSC, haga clic en los enlaces con este problema que ha solucionado. En la siguiente pantalla, haga clic en el botón Validar corrección.
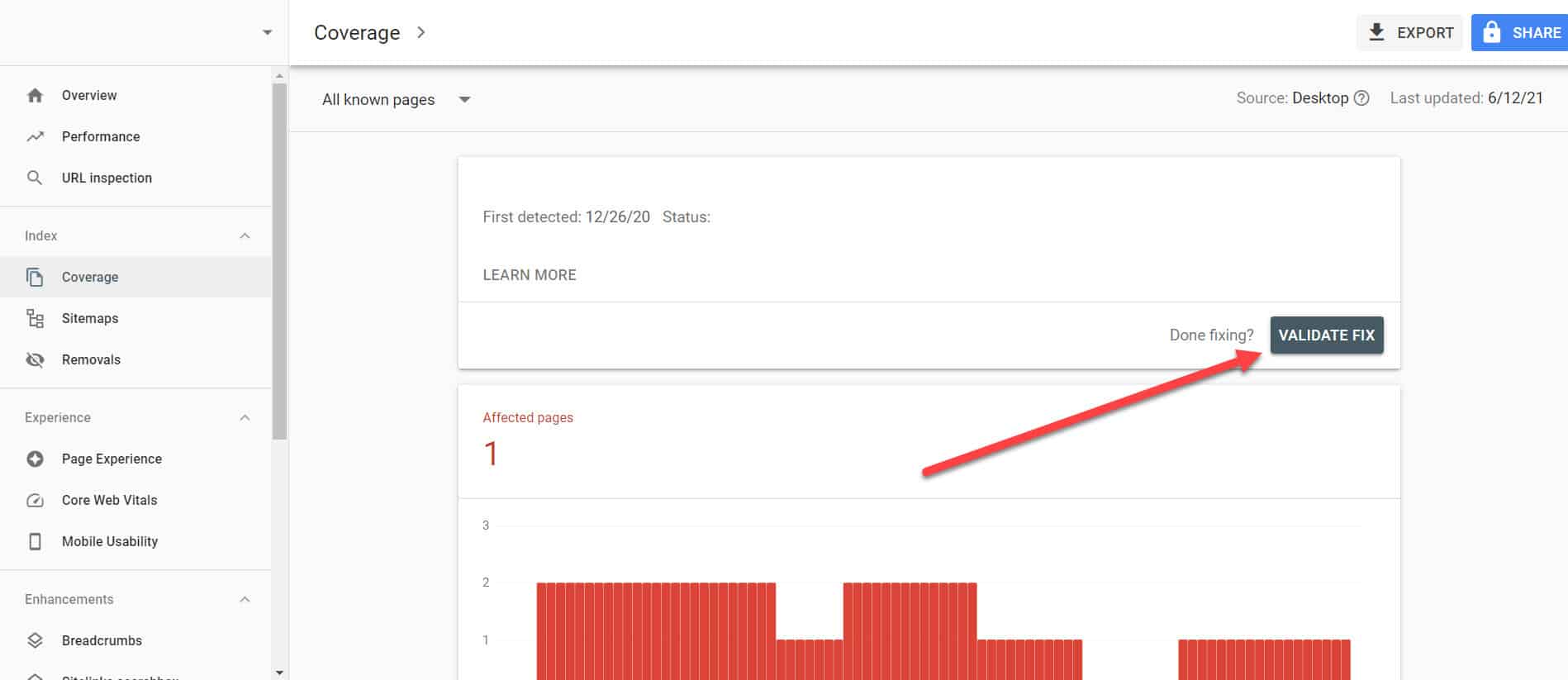
Esto le pedirá a Google que verifique si la página ya no tiene el problema.
Conclusión
A diferencia de otros problemas descubiertos por Google Search Console, "Indexado, aunque bloqueado por robots.txt" puede parecer una gota en el océano. Sin embargo, estas caídas podrían acumularse en un torrente de problemas en todo su sitio que evitarán que genere tráfico orgánico.
Al seguir las pautas anteriores sobre cómo resolver el problema en sus páginas más importantes, puede evitar que su sitio web pierda tráfico valioso al optimizar su sitio web para que Google lo rastree e indexe correctamente.