
Indexat, deși blocat de Robots.txt: tot ce trebuie să știți
Publicat: 2021-07-01Dacă aveți pagini pe site-ul dvs. pe care Google le-a indexat, dar nu le poate accesa cu crawlere, veți primi un mesaj „Indexat, deși blocat de Robots.txt” pe Google Search Console (GSC).
Deși Google poate vizualiza aceste pagini, nu le va afișa ca parte a paginilor cu rezultate ale motorului de căutare pentru cuvintele cheie vizate.
Dacă acesta este cazul, veți pierde oportunitatea de a obține trafic organic pentru aceste pagini.
Acest lucru este esențial în special pentru paginile care generează mii de vizitatori organici lunar doar pentru a se confrunta cu această problemă.
În acest moment, probabil că aveți o mulțime de întrebări despre acest mesaj de eroare. De ce ai primit-o? Cum s-a întâmplat? Și, mai important, cum îl puteți remedia și recupera traficul dacă acest lucru s-a întâmplat unei pagini care se clasa deja bine.
Această postare va răspunde la toate aceste întrebări și vă va arăta cum să evitați ca această problemă să se repete pe site-ul dvs.
Cum să știți dacă site-ul dvs. are această problemă
În mod normal, ar trebui să primiți un e-mail de la Google care vă informează despre o „problemă de acoperire a indexului” pe site-ul dvs. Iată cum arată e-mailul:
E-mailul nu va specifica care sunt paginile exacte sau adresa URL afectată. Va trebui să vă conectați la Google Search Console pentru a afla singur.
Dacă nu ați primit un e-mail, cel mai bine este să îl vedeți în continuare pentru a vă asigura că site-ul dvs. este într-o formă optimă.
După conectarea la GSC, accesați Raportul de acoperire a indexului făcând clic pe Acoperire sub Index. Apoi, pe pagina următoare, derulați în jos pentru a vedea problemele raportate de GSC.
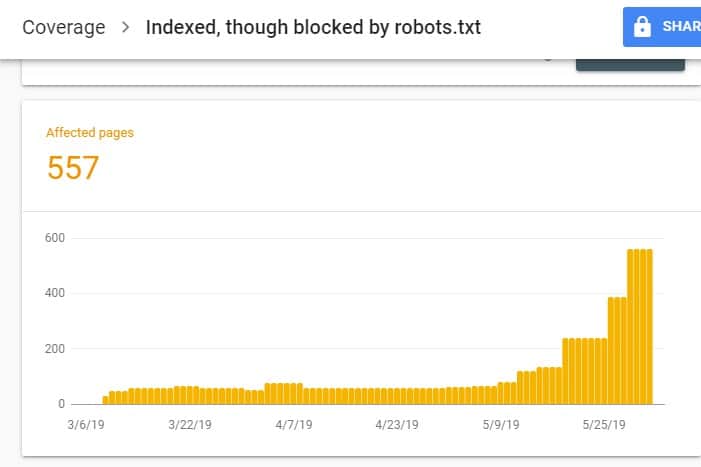
„Indexat, deși blocat de robots.txt” este etichetat sub „Valabil cu avertisment”. Aceasta înseamnă că nu este nimic în neregulă cu adresa URL în sine, dar motoarele de căutare nu vor afișa paginile în rezultatele motorului de căutare.
De ce site-ul dvs. are această problemă (și cum se rezolvă)?
Înainte de a începe să te gândești la o soluție, trebuie să știi mai întâi ce pagini trebuie indexate și trebuie să apară în rezultatele căutării.
Este posibil ca adresele URL pe care le vedeți pe GSC cu problema „Indexat, deși blocat de robots.txt” să nu aibă scopul de a genera trafic organic către site-ul dvs. De exemplu, paginile de destinație pentru campaniile dvs. de anunțuri plătite. Prin urmare, repararea paginilor poate să nu merite timpul și efortul dvs.
Mai jos sunt motivele pentru care unele dintre paginile dvs. au această problemă și dacă ar trebui sau nu să le remediați:
Nu permiteți regula pe Robots.txt și Metaeticheta Noindex din HTML-ul paginii
Cel mai frecvent motiv pentru care apare această problemă este atunci când dvs. sau cineva care vă gestionează site-ul activează regula de respingere pentru acea adresă URL specifică pe robots.txt al site-ului dvs. și a adăugat metaeticheta noindex pe aceeași adresă URL.
În primul rând, proprietarii de site-uri folosesc robots.txt pentru a informa crawlerele motoarelor de căutare despre cum să trateze adresele URL ale site-urilor dvs. În acest caz, ați adăugat regula de respingere pe paginile și folderele site-ului dvs. în robots.txt al site-ului dvs.
Iată ce puteți vedea când deschideți fișierul robots.txt al site-ului dvs.:
Agent utilizator: * Nu permite: /
În exemplul de mai sus, această linie de cod împiedică toate crawlerele web (*) să acceseze cu crawlere paginile site-ului dvs. (Disallow) să includă pagina dvs. de pornire (/). Drept urmare, toate motoarele de căutare nu vor accesa cu crawlere și nici nu vor indexa paginile site-ului dvs.
Puteți edita robots.txt pentru a identifica crawlerele web (Googlebot, msnbot, magpie-crawler etc.) și pentru a specifica ce pagină sau paginile pe care nu doriți să le atingă crawlerele (/page1, /page2, /page3 etc.). ).
Cu toate acestea, dacă nu aveți acces root la serverul dvs., puteți împiedica roboții motoarelor de căutare să indexeze paginile site-ului dvs. folosind eticheta noindex.
Această metodă are același efect ca regula de interzicere pe robots.txt. Cu toate acestea, în loc să enumerați diferitele pagini și foldere de pe site-ul dvs. într-un fișier robots.txt pe care doriți să îl împiedicați să apară pe SERP-uri, trebuie să introduceți metaeticheta noindex pe fiecare pagină a site-ului dvs. pe care nu o doriți. să apară în rezultatele căutării.
Acesta este un proces care consumă mult mai mult timp decât metoda anterioară, dar vă oferă un control mai detaliat asupra adresei URL să blocați. Acest lucru înseamnă, de asemenea, că există o marjă mai mică de eroare din partea dvs.
Remediere: din nou, problema în GSC apare atunci când paginile de pe site-ul dvs. au o regulă de interzicere a fișierului robots.txt și o etichetă noindex.
Pentru ca motoarele de căutare să știe dacă să indexeze sau nu o pagină, ar trebui să o poată accesa cu crawlere de pe site-ul dvs. Dar dacă împiedicați motoarele de căutare să facă acest lucru prin robots.txt, acesta nu ar ști ce să facă cu pagina respectivă.
Folosind robots.txt și eticheta noindex pentru a se completa și nu a concura unul împotriva celuilalt, site-ul dvs. va avea reguli mult mai clare și mai directe de urmat de roboții motoarelor de căutare atunci când își tratează paginile.
Pentru a face acest lucru, trebuie să editați fișierul robots.txt. Pentru proprietarii de site-uri WordPress, utilizarea pluginurilor SEO cu un editor robots.txt precum Yoast SEO sau Rank Math este cea mai convenabilă.

Dacă robots.txt nu poate fi scris de partea dvs., trebuie să contactați furnizorul dvs. de găzduire pentru a modifica permisiunea fișierelor și folderelor dvs.
O altă modalitate este să vă conectați la clientul dvs. FTP sau la Managerul de fișiere al furnizorului dvs. de găzduire. Aceasta este metoda preferată în rândul dezvoltatorilor, deoarece aceștia au control complet asupra modului de editare a fișierului, printre altele.
Format URL greșit
Adresele URL de pe site-ul dvs. care nu sunt cu adevărat „pagini” în sensul cel mai strict pot primi mesajul „Indexat, deși blocat de robots.txt”.
De exemplu, https://example.com?s=what+is+seo este o pagină de pe un site care arată rezultatele căutării pentru interogarea „ce este seo”. Această adresă URL este răspândită printre site-urile WordPress unde funcția de căutare este activată la nivelul întregului site.
Remediere: în mod normal, nu este nevoie să rezolvați această problemă, presupunând că adresa URL este inofensivă și nu vă afectează profund traficul de căutare.
Paginile pe care nu doriți să le indexați au legături interne
Chiar dacă nu aveți etichetă index pe pagina pe care nu doriți să o indexați, Google le poate trata ca sugestii în loc de reguli. Acest lucru este evident atunci când conectați la pagini fie cu directiva noindex, fie cu regula interzicerea paginilor de pe site-ul dvs. pe care motoarele de căutare le accesează cu crawlere și le indexează.
Prin urmare, este posibil să vedeți aceste pagini care apar pe SERP-uri chiar dacă nu doriți.
Remediere : trebuie să eliminați linkurile care indică această pagină și să le duceți la o pagină similară.
Pentru a face acest lucru, trebuie să identificați legăturile sale interne prin efectuarea unui audit SEO folosind un instrument precum Screaming Frog (gratuit pentru site-urile web cu 500 de adrese URL) sau Ahrefs Webmaster Tools (o alternativă gratuită mult mai bună) pentru a identifica ce pagini leagă la paginile dvs. blocate.
Folosind Ahrefs, accesați Rapoarte > Pagini interne după executarea unui audit. Găsiți paginile pe care le-ați blocat de la crawlerele web și pe care nu le-ați indexat și vedeți ce pagini leagă la ele în coloana Nr. de linkuri.
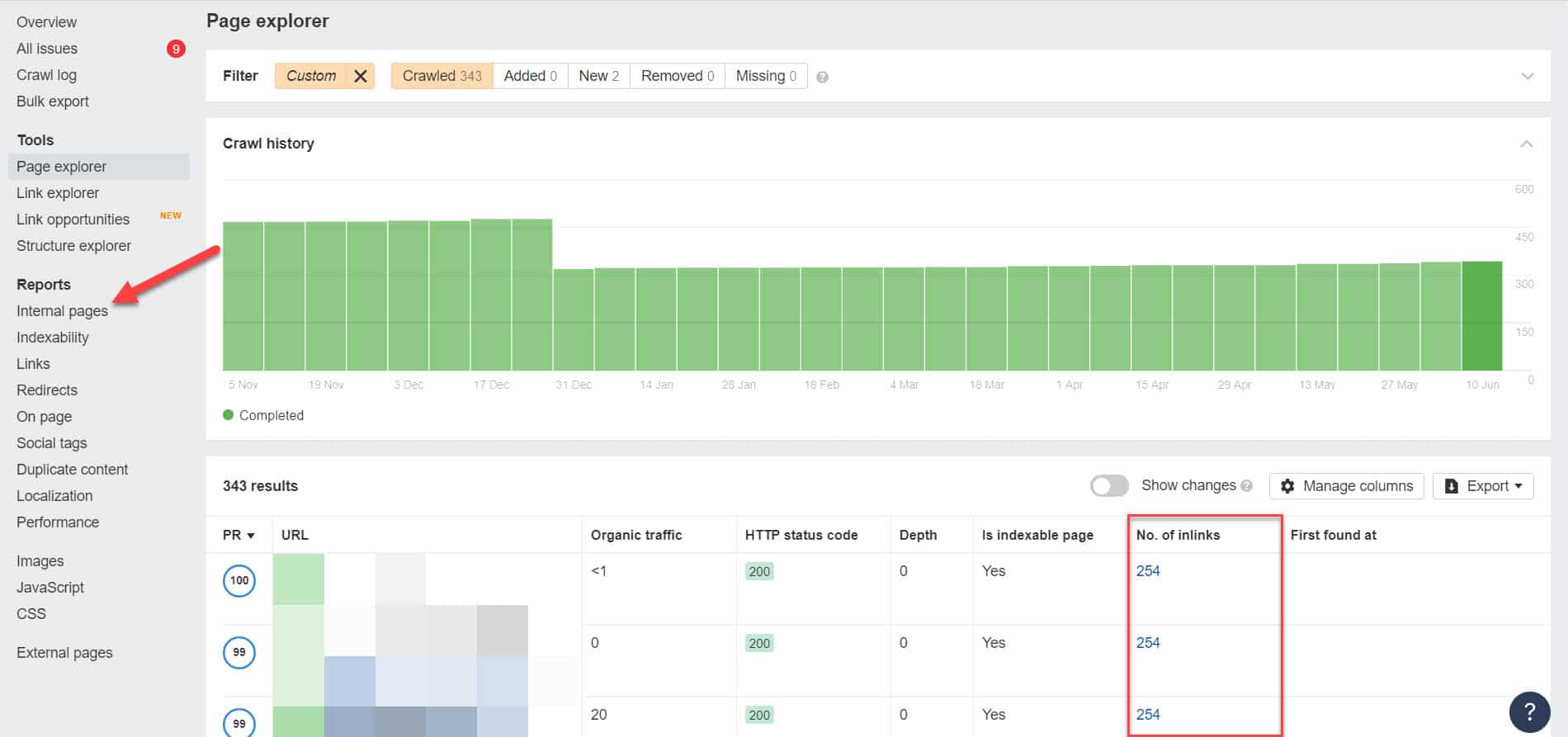
De aici, editați linkurile din aceste pagini pe rând. Sau le puteți înlocui cu un link către pagina dvs. cu o etichetă noindex.
Arătând către un lanț de redirecționare
Dacă un link de pe site-ul dvs. indică un flux nesfârșit de redirecționări, atunci Googlebot nu va mai trece prin fiecare link înainte de a găsi adresa URL reală a paginii.
Aceste lanțuri de redirecționare ar putea provoca, de asemenea, probleme de conținut duplicat, care ar putea cauza probleme SEO mai mari în continuare. Singura modalitate de a rezolva acest lucru este identificarea paginii dvs. preferate și canonice cu eticheta canonică, astfel încât Google să știe ce pagină dintre multe ar trebui să acceseze cu crawlere și să indexeze.
De asemenea, luați în considerare faptul că conectarea către redirecționare în loc de pagina canonică vă consumă bugetul de accesare cu crawlere. Dacă linkul de redirecționare indică mai multe redirecționări, nu puteți utiliza bugetul de accesare cu crawlere în paginile care contează pe site-ul dvs. Până când ajunge la cele mai importante pagini, Google nu va putea să le acceseze cu crawlere și să le indexeze corect după o perioadă.
Remediere: Eliminați link-urile de redirecționare de pe site-ul dvs. și, în schimb, trimiteți către pagina canonică.
Folosind din nou Instrumentele pentru webmasteri Ahrefs, puteți vizualiza linkurile de redirecționare pe pagina Instrumente > Explorator de linkuri. Apoi filtrați rezultatele pentru a vă afișa numai link-uri de redirecționare pe site-ul dvs.
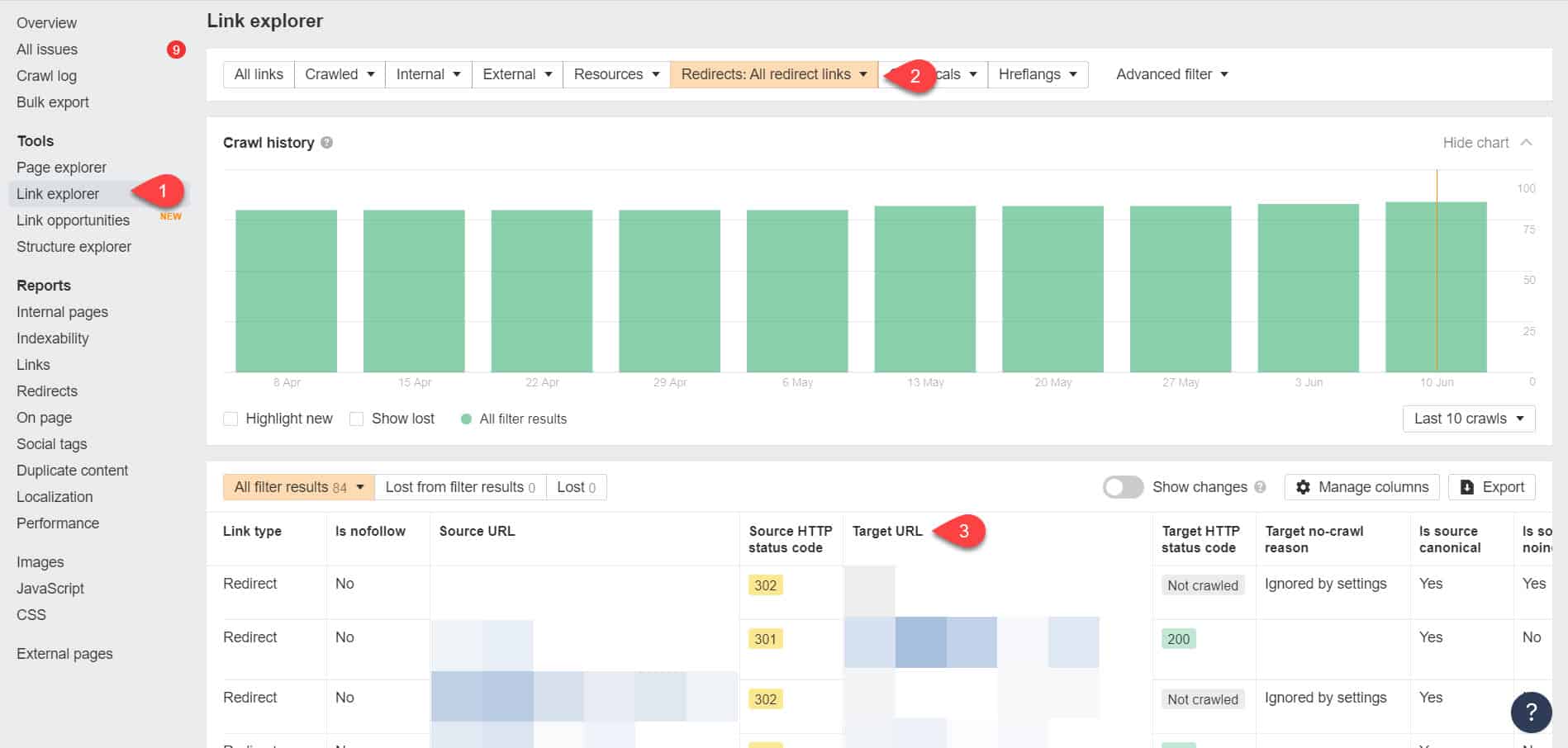
Din rezultate, identificați care legături formează un lanț de redirecționare fără sfârșit. Apoi întrerupeți lanțul găsind pagina corectă la care ar trebui să fie conectată fiecare pagină care trimite la redirecționări.
Ce să faceți după rezolvarea acestei probleme
După ce ați implementat soluțiile de mai sus în paginile importante cu problema „Indexat, deși blocat de Robots.txt”, trebuie să verificați modificările, astfel încât Google Search Console să le poată marca ca rezolvate.
Revenind la Raportul de acoperire a indexului din GSC, faceți clic pe linkurile cu această problemă pe care le-ați remediat. Pe ecranul următor, faceți clic pe butonul Validate Fix.
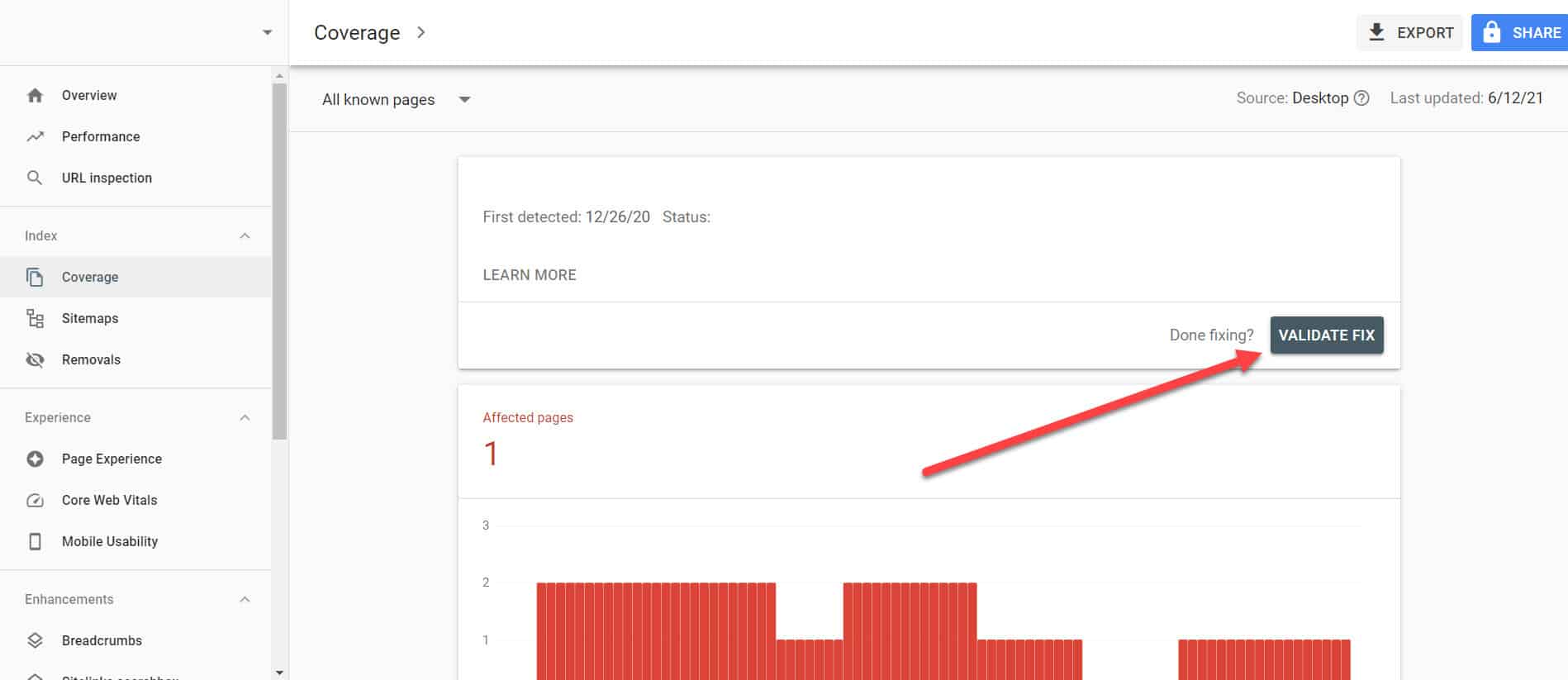
Aceasta va solicita Google să verifice dacă pagina nu mai are problema.
Concluzie
Spre deosebire de alte probleme descoperite de Google Search Console, „Indexat, deși blocat de robots.txt” poate părea o picătură în găleată. Cu toate acestea, aceste picături s-ar putea acumula într-un torent de probleme pe întregul tău site, ceea ce îl va împiedica să genereze trafic organic.
Urmând instrucțiunile de mai sus cu privire la modul de rezolvare a problemei din paginile dvs. cele mai importante, puteți împiedica site-ul dvs. web să piardă trafic valoros, optimizând site-ul dvs. pentru ca Google să poată accesa cu crawlere și să indexeze corect.