
已编入索引,但已被 Robots.txt 阻止:您需要知道的一切
已发表: 2021-07-01如果您的网站上有被 Google 编入索引但无法抓取的网页,您将在 Google 搜索控制台 (GSC) 上收到“已编入索引,但已被 Robots.txt 阻止”消息。
虽然 Google 可以查看这些页面,但它不会将它们显示为目标关键字的搜索引擎结果页面的一部分。
如果是这种情况,您将错过为这些页面获得自然流量的机会。
这对于每月产生数千个自然访问者的页面尤其重要,只是遇到了这个问题。
此时,您可能对此错误消息有很多疑问。 你为什么收到它? 这是怎么发生的? 而且,更重要的是,如果这种情况发生在已经排名很好的页面上,你如何修复它并恢复流量。
这篇文章将回答所有这些问题,并向您展示如何避免此问题再次在您的网站上发生。
如何知道您的网站是否存在此问题
通常,您应该会收到一封来自 Google 的电子邮件,通知您网站上的“索引覆盖率问题”。 电子邮件如下所示:
该电子邮件不会具体说明受影响的页面或 URL 是什么。 您必须登录到您的 Google Search Console 才能找到自己。
如果您没有收到电子邮件,最好还是亲自查看,以确保您的网站处于最佳状态。
登录 GSC 后,点击 Index 下的 Coverage 进入 Index Coverage Report。 然后,在下一页上,向下滚动以查看 GSC 报告的问题。
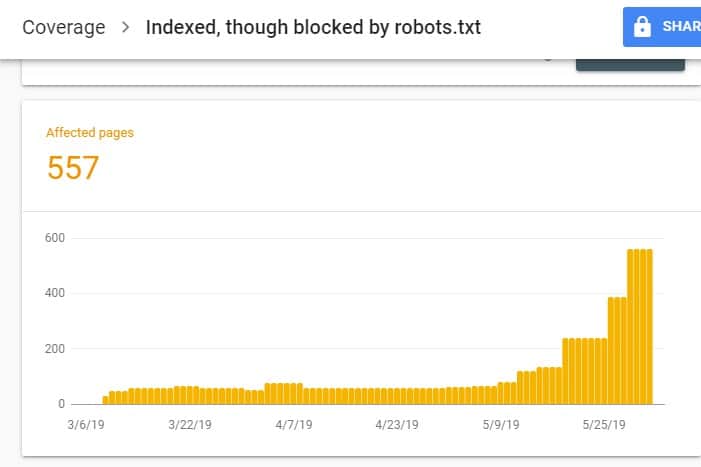
“已编入索引,但已被 robots.txt 阻止”标记在“有效但有警告”下。 这意味着 URL 本身没有问题,但搜索引擎不会在搜索引擎结果中显示页面。
为什么您的网站会出现此问题(以及如何解决)?
在开始考虑解决方案之前,您必须首先知道哪些页面需要被索引并且必须出现在搜索结果中。
您在 GSC 上看到的带有“已编入索引,但已被 robots.txt 阻止”问题的 URL 可能并非旨在为您的网站带来自然流量。 例如,您的付费广告活动的登陆页面。 因此,修复页面可能不值得您花费时间和精力。
以下是您的某些网页出现此问题的原因以及您是否应该修复它们:
页面 HTML 中的 Robots.txt和Noindex 元标记禁止规则
发生此问题的最常见原因是您或管理您网站的人在您网站的 robots.txt 上为该特定网址启用了禁止规则,并在同一网址上添加了 noindex 元标记。
首先,网站所有者使用 robots.txt 通知搜索引擎抓取工具如何处理您的网站 URL。 在这种情况下,您在网站的 robots.txt 中的网站页面和文件夹上添加了禁止规则。
当您打开网站的 robots.txt 文件时,您可能会看到以下内容:
用户代理:* 禁止:/
在上面的示例中,这行代码阻止所有网络爬虫 (*) 爬取您的网站页面(禁止)包括您的主页 (/)。 因此,所有搜索引擎都不会抓取或索引您的网站页面。
您可以编辑 robots.txt 以挑选出网络爬虫(Googlebot、msnbot、magpie-crawler 等)并指定您不希望爬虫触及的页面(/page1、/page2、/page3 等)。 )。
但是,如果您没有对服务器的 root 访问权限,则可以防止搜索引擎机器人使用 noindex 标记为您的网站页面编制索引。
此方法与 robots.txt 上的禁止规则具有相同的效果。 但是,您不必在 robots.txt 文件中列出您网站上要防止出现在 SERP 上的不同页面和文件夹,而是必须在您不想要的网站每个页面上输入 noindex 元标记出现在搜索结果中。
这是一个比以前的方法更耗时的过程,但它可以让您更精细地控制要阻止的 URL。 这也意味着您的错误余地较小。
修复:同样,当您网站上的页面对 robots.txt 文件和 noindex 标记有禁止规则时,就会出现 GSC 中的问题。
为了让搜索引擎知道是否要索引页面,它应该能够从您的站点抓取它。 但是,如果您通过 robots.txt 阻止搜索引擎这样做,它就不会知道如何处理该页面。
通过使用 robots.txt 和 noindex 标签来相互补充而不是相互竞争,您的网站将有更清晰和更直接的规则供搜索引擎机器人在处理其页面时遵循。
为此,您必须编辑 robots.txt 文件。 对于 WordPress 网站所有者,使用带有 robots.txt 编辑器(如 Yoast SEO 或 Rank Math)的 SEO 插件是最方便的。
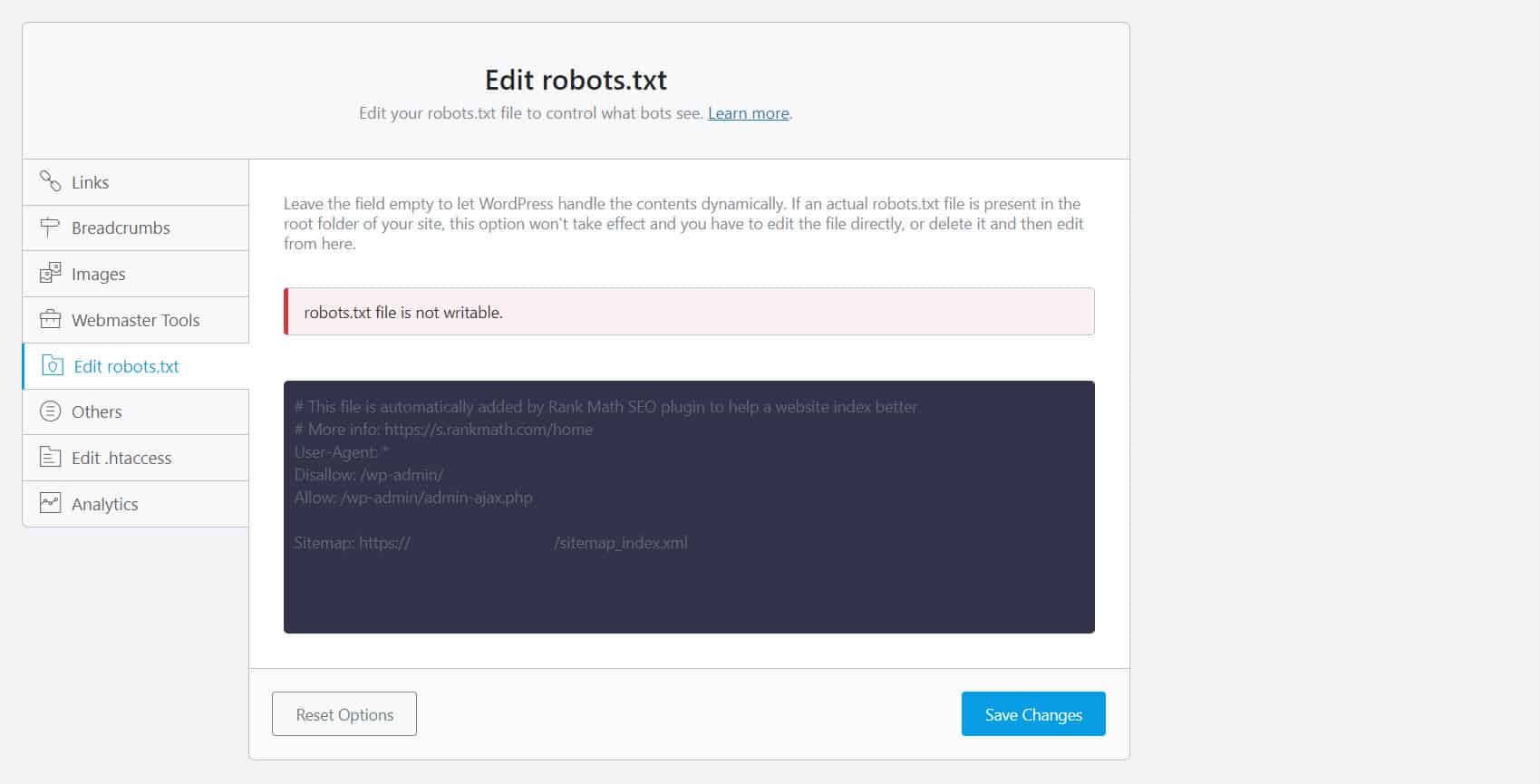

如果您无法写入 robots.txt,您必须联系您的托管服务提供商以更改您的文件和文件夹的权限。
另一种方法是登录到您的 FTP 客户端或托管服务提供商的文件管理器。 这是开发人员的首选方法,因为他们可以完全控制如何编辑文件等。
错误的网址格式
您网站中严格意义上的并非真正“页面”的 URL 可能会收到“已编入索引,但已被 robots.txt 阻止”消息。
例如,https://example.com?s=what+is+seo 是网站上的一个页面,显示查询“什么是 seo”的搜索结果。 此 URL 在站点范围内启用了搜索功能的 WordPress 站点中很普遍。
修复:通常情况下,无需解决此问题,假设 URL 是无害的并且不会严重影响您的搜索流量。
你不想被索引的页面有内部链接
即使您不想索引的页面上有 noindex 标记,Google 也可能会将它们视为建议而不是规则。 当您链接到具有 noindex 指令的页面或在您的网站上搜索引擎抓取和索引的页面上禁止规则的页面时,这一点很明显。
因此,即使您不想,您也可能会看到这些页面出现在 SERP 上。
修复:您必须删除指向此特定页面的链接,并将它们引导至类似页面。
为此,您必须使用 Screaming Frog(对 500 个 URL 的网站免费)或 Ahrefs 网站管理员工具(更好的免费替代品)等工具运行 SEO 审核来识别其内部链接,以确定哪些页面链接到您的被阻止页面。
使用 Ahrefs,在运行审计后转到报告 > 内部页面。 查找您已阻止网络爬虫和未编入索引的页面,并在“链接数量”列中查看哪些页面链接到它们。
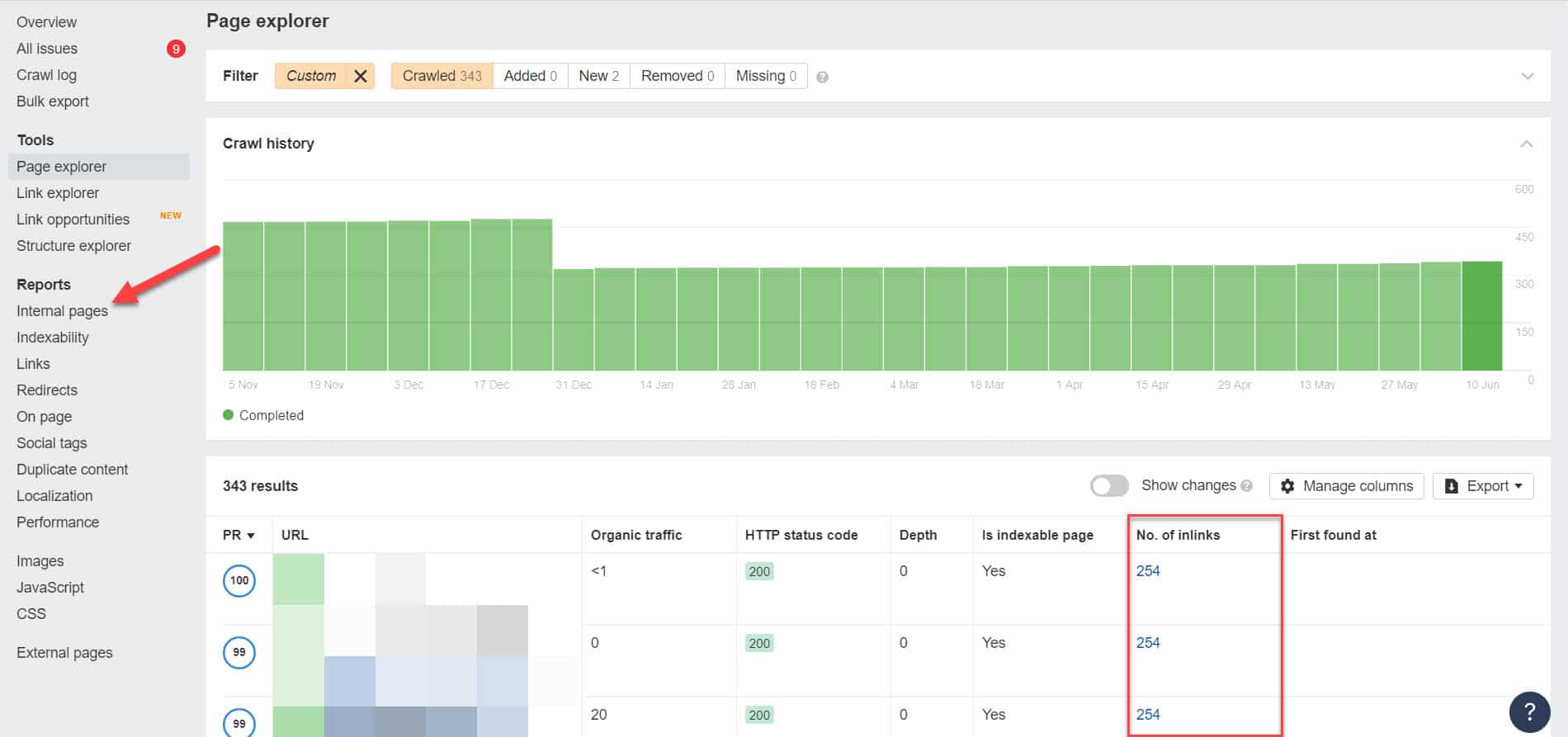
从这里,一次编辑这些页面的链接。 或者,您可以将它们替换为带有 noindex 标记的页面链接。
指向重定向链
如果您网站上的链接指向无穷无尽的重定向流,那么 Googlebot 将在找到该页面的实际 URL 之前停止通过每个链接。
这些重定向链也可能导致重复的内容问题,从而导致更大的 SEO 问题。 解决此问题的唯一方法是使用规范标签标识您的首选和规范页面,以便 Google 知道它应该抓取和索引的众多页面中的哪个页面。
此外,请考虑链接到重定向而不是规范页面会耗尽您的抓取预算。 如果重定向链接指向多个重定向,则您无法在网站中重要的页面上使用抓取预算。 当它到达最重要的页面时,Google 将无法在一段时间后正确抓取它们并将其编入索引。
修复:从您的站点中删除重定向链接,并改为链接到规范页面。
再次使用 Ahrefs 网站管理员工具,您可以在工具 > 链接浏览器页面上查看您的重定向链接。 然后过滤结果以仅显示您网站中的重定向链接。
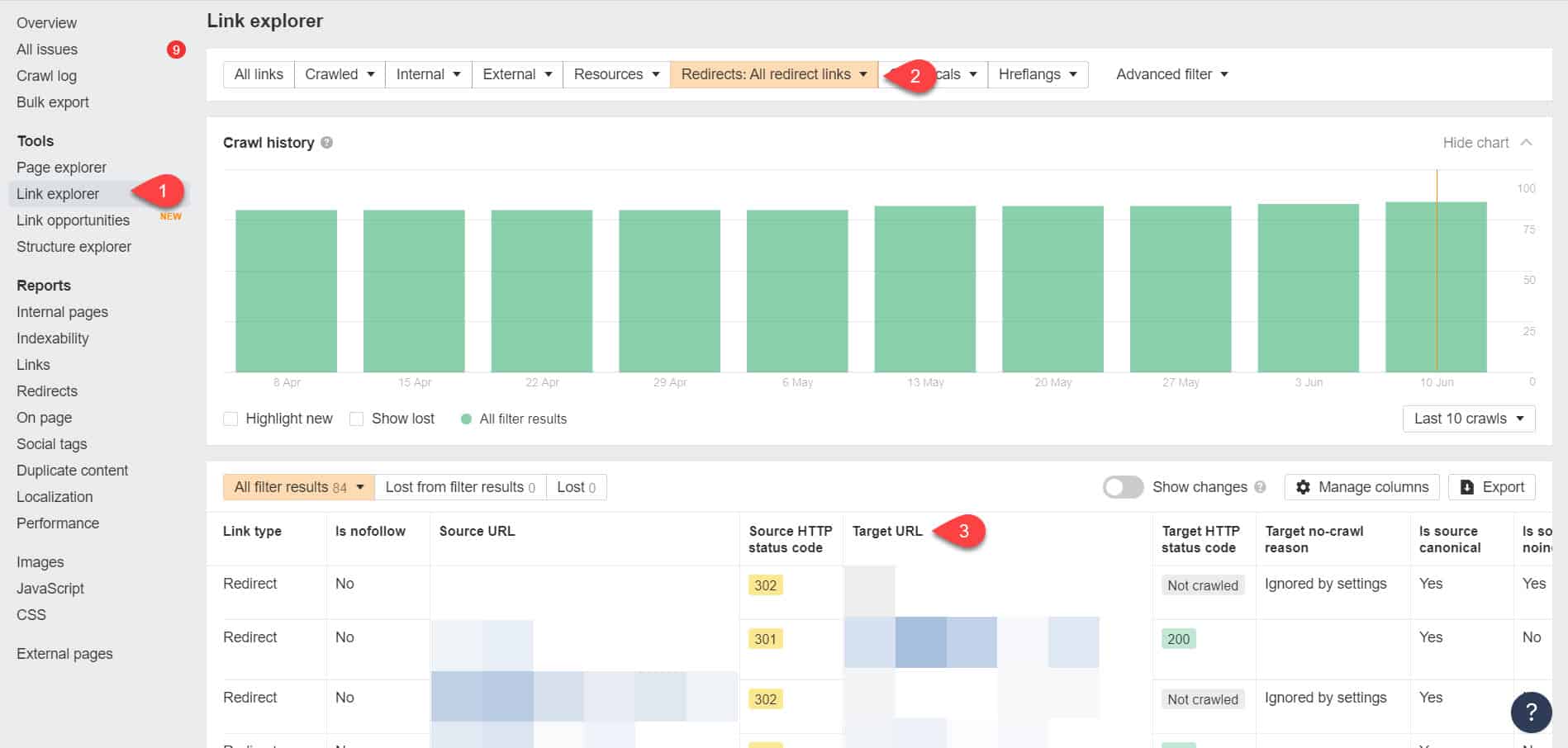
从结果中,确定哪些链接形成了无限的重定向链。 然后通过找到链接到重定向的每个页面应该链接到的正确页面来打破链。
解决此问题后该怎么办
对具有“已编入索引,但被 Robots.txt 阻止”问题的重要页面实施上述解决方案后,您需要验证更改,以便 Google Search Console 将其标记为已解决。
返回 GSC 中的索引覆盖率报告,单击您已修复的与此问题相关的链接。 在下一个屏幕上,单击 Validate Fix 按钮。
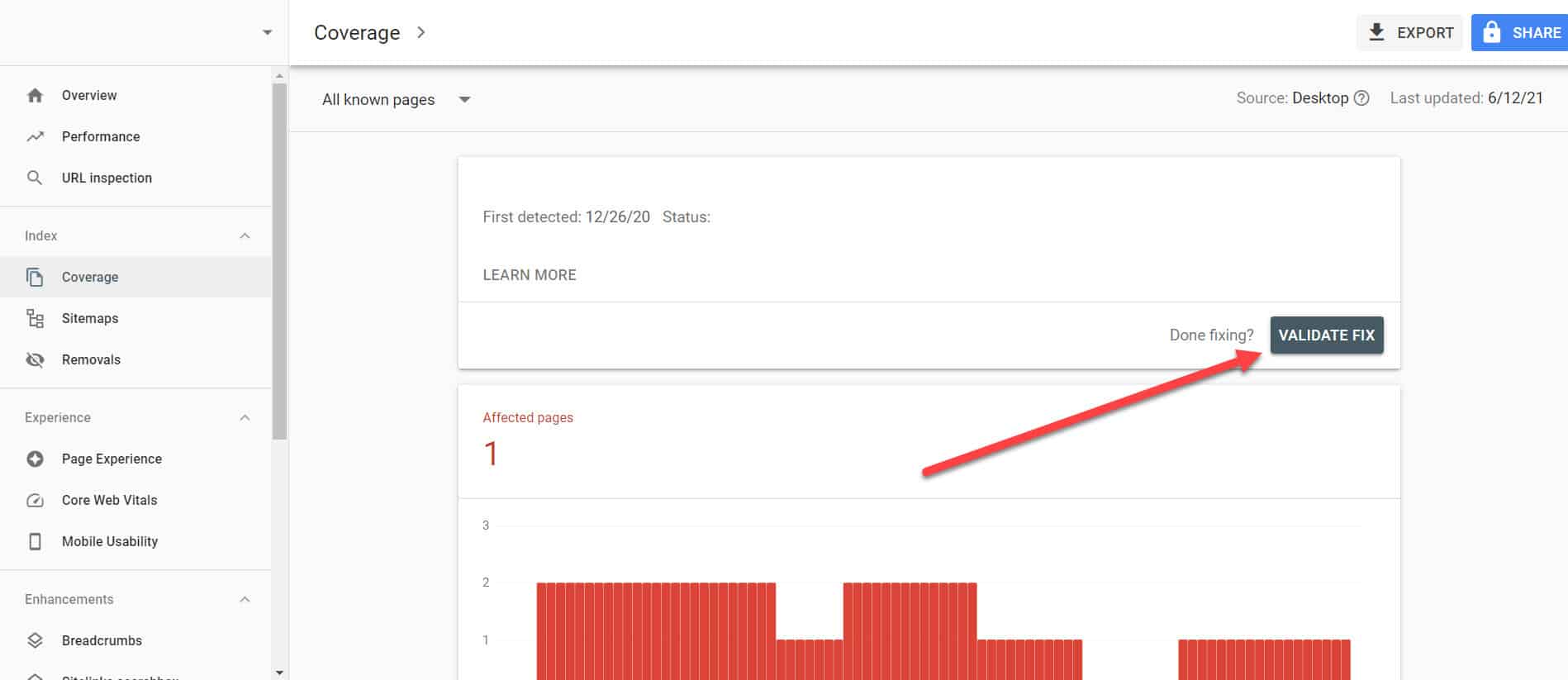
这将要求 Google 验证该页面是否不再存在问题。
结论
与 Google Search Console 发现的其他问题不同,“已编入索引,但已被 robots.txt 阻止”似乎是杯水车薪。 但是,这些下降可能会累积成整个网站的大量问题,这将阻止它产生自然流量。
通过遵循上述有关如何解决最重要页面上的问题的指南,您可以通过优化您的网站以供 Google 正确抓取和索引,从而防止您的网站失去宝贵的流量。