
Indiziert, obwohl von Robots.txt blockiert: Alles, was Sie wissen müssen
Veröffentlicht: 2021-07-01Wenn Sie Seiten auf Ihrer Website haben, die von Google indexiert wurden, aber nicht gecrawlt werden können, erhalten Sie in Ihrer Google Search Console (GSC) die Meldung „Indiziert, obwohl von Robots.txt blockiert“.
Obwohl Google diese Seiten anzeigen kann, werden sie nicht als Teil der Suchmaschinen-Ergebnisseiten für ihre Ziel-Keywords angezeigt.
Wenn dies der Fall ist, verpassen Sie die Gelegenheit, organischen Traffic für diese Seiten zu erhalten.
Dies ist besonders wichtig für Seiten, die Tausende von organischen Besuchern pro Monat generieren, nur um auf dieses Problem zu stoßen.
An dieser Stelle haben Sie wahrscheinlich viele Fragen zu dieser Fehlermeldung. Warum haben Sie es erhalten? Wie ist es passiert? Und, was noch wichtiger ist, wie können Sie das Problem beheben und den Verkehr wiederherstellen, wenn dies einer Seite passiert ist, die bereits ein gutes Ranking hatte?
Dieser Beitrag beantwortet all diese Fragen und zeigt Ihnen, wie Sie vermeiden können, dass dieses Problem auf Ihrer Website erneut auftritt.
So erkennen Sie, ob Ihre Website dieses Problem hat
Normalerweise sollten Sie eine E-Mail von Google erhalten, die Sie über ein „Problem mit der Indexabdeckung“ auf Ihrer Website informiert. So sieht die E-Mail aus:
Die E-Mail gibt nicht an, um welche genauen Seiten oder URL es sich handelt. Sie müssen sich bei Ihrer Google Search Console anmelden, um es selbst herauszufinden.
Wenn Sie keine E-Mail erhalten haben, sehen Sie es sich am besten selbst an, um sicherzustellen, dass Ihre Website in Topform ist.
Rufen Sie nach der Anmeldung bei GSC den Bericht zur Indexabdeckung auf, indem Sie unter „Index“ auf „Abdeckung“ klicken. Scrollen Sie dann auf der nächsten Seite nach unten, um die von GSC gemeldeten Probleme anzuzeigen.
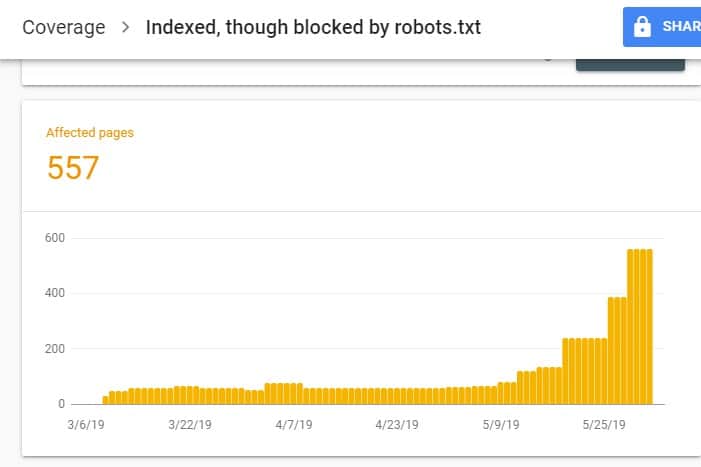
Die „Indiziert, obwohl von robots.txt blockiert“ ist unter „Gültig mit Warnung“ gekennzeichnet. Das bedeutet, dass an der URL an sich nichts auszusetzen ist, aber Suchmaschinen die Seite(n) nicht in den Suchmaschinenergebnissen anzeigen.
Warum hat Ihre Website dieses Problem (und wie kann es behoben werden)?
Bevor Sie über eine Lösung nachdenken, müssen Sie zunächst wissen, welche Seiten indexiert und in den Suchergebnissen angezeigt werden müssen.
Es ist möglich, dass die URLs, die Sie auf GSC mit dem Problem „Indiziert, obwohl von robots.txt blockiert“ sehen, nicht dazu gedacht sind, organischen Traffic auf Ihre Website zu lenken. Zum Beispiel Zielseiten für Ihre bezahlten Werbekampagnen. Daher ist das Reparieren der Seiten möglicherweise nicht Ihre Zeit und Mühe wert.
Nachfolgend finden Sie Gründe, warum einige Ihrer Seiten dieses Problem haben und ob Sie es beheben sollten oder nicht:
Verbotsregel für Ihr Robots.txt- und Noindex-Meta-Tag im HTML der Seite
Der häufigste Grund, warum dieses Problem auftritt, ist, wenn Sie oder jemand, der Ihre Website verwaltet, die Disallow-Regel für diese bestimmte URL in der robots.txt-Datei Ihrer Website aktiviert und das noindex-Meta-Tag zu derselben URL hinzugefügt hat.
Erstens verwenden Websitebesitzer robots.txt, um Suchmaschinen-Crawler darüber zu informieren, wie sie mit Ihren Website-URLs umgehen sollen. In diesem Fall haben Sie die Verbotsregel auf Seiten und Ordnern Ihrer Website in der robots.txt-Datei Ihrer Website hinzugefügt.
Folgendes sehen Sie möglicherweise, wenn Sie die robots.txt-Datei Ihrer Website öffnen:
Benutzeragent: * Nicht zulassen: /
Im obigen Beispiel verhindert diese Codezeile, dass alle Webcrawler (*) Ihre Website-Seiten crawlen (Nicht zulassen), einschließlich Ihrer Homepage (/). Infolgedessen werden alle Suchmaschinen Ihre Website-Seiten weder crawlen noch indizieren.
Sie können die robots.txt-Datei bearbeiten, um Webcrawler (Googlebot, msnbot, magpie-crawler usw.) herauszugreifen und anzugeben, welche Seite oder Seiten die Crawler nicht berühren sollen (/page1, /page2, /page3 usw.). ).
Wenn Sie jedoch keinen Root-Zugriff auf Ihren Server haben, können Sie mit dem noindex-Tag verhindern, dass Suchmaschinen-Bots Ihre Seiten indexieren.
Diese Methode hat denselben Effekt wie die Disallow-Regel auf robots.txt. Anstatt jedoch die verschiedenen Seiten und Ordner Ihrer Website in einer robots.txt-Datei aufzulisten, deren Erscheinen in SERPs Sie verhindern möchten, müssen Sie das noindex-Meta-Tag auf jeder Seite Ihrer Website eingeben, die Sie nicht möchten in den Suchergebnissen erscheinen.
Dies ist ein viel zeitaufwändigerer Prozess als die vorherige Methode, aber Sie haben eine genauere Kontrolle darüber, welche URL blockiert werden soll. Dies bedeutet auch, dass Ihre Fehlerquote geringer ist.
Behebung: Auch hier tritt das Problem in GSC auf, wenn Seiten auf Ihrer Website eine Verbotsregel für die robots.txt-Datei und ein noindex-Tag haben.
Damit Suchmaschinen wissen, ob eine Seite indexiert werden soll oder nicht, sollten sie in der Lage sein, sie von Ihrer Website aus zu crawlen. Aber wenn Sie Suchmaschinen daran hindern, dies durch Ihre robots.txt zu tun, wüsste sie nicht, was sie mit dieser Seite machen sollen.
Indem Sie robots.txt und das noindex-Tag verwenden, um sich zu ergänzen und nicht miteinander zu konkurrieren, hat Ihre Website viel klarere und direktere Regeln für Suchmaschinen-Bots, die sie befolgen müssen, wenn sie ihre Seiten behandeln.
Dazu müssen Sie Ihre robots.txt-Datei bearbeiten. Für WordPress-Site-Besitzer ist die Verwendung von SEO-Plugins mit einem robots.txt-Editor wie Yoast SEO oder Rank Math am bequemsten.
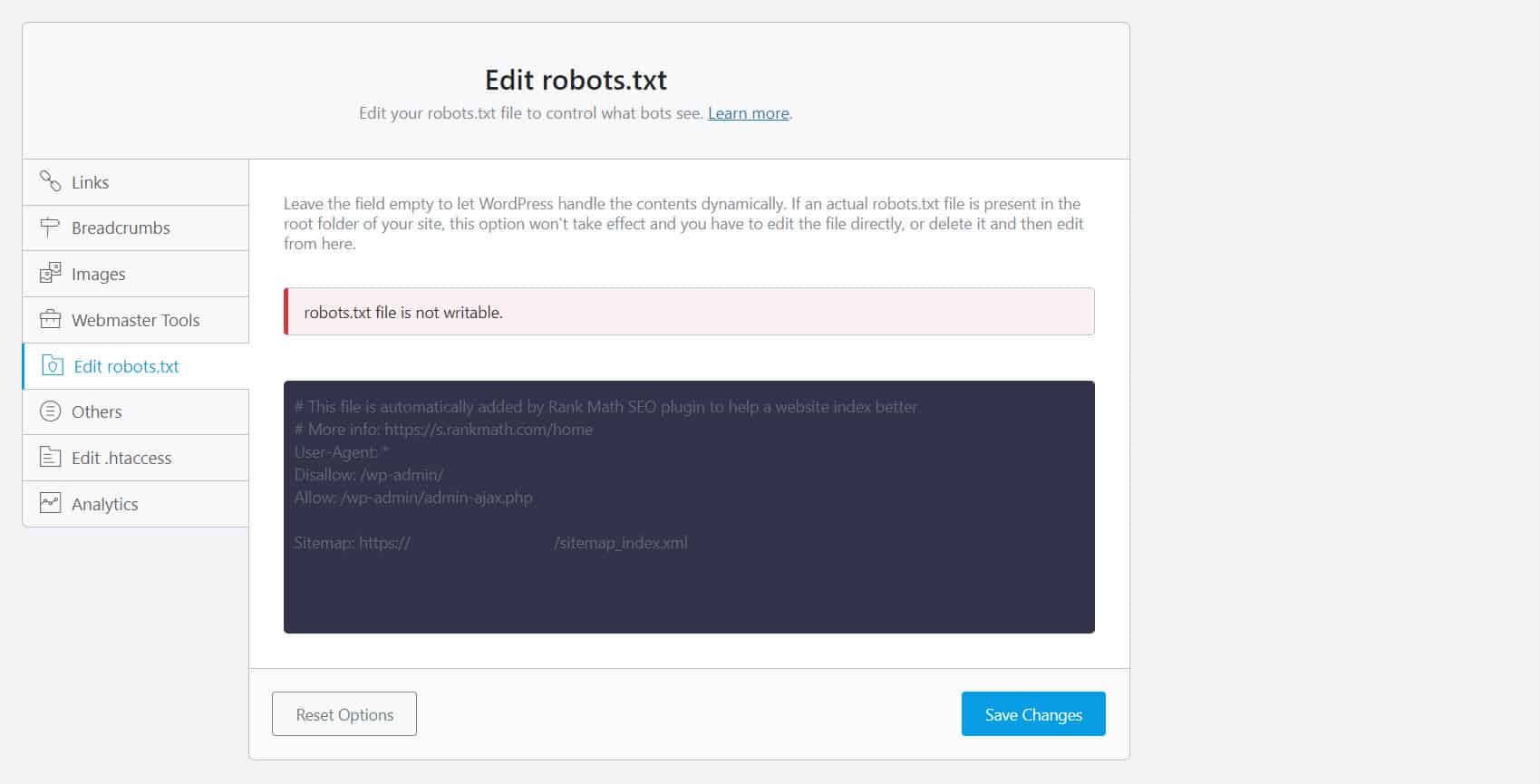

Wenn die robots.txt auf Ihrer Seite nicht beschreibbar ist, müssen Sie sich an Ihren Hosting-Provider wenden, um Berechtigungsänderungen an Ihren Dateien und Ordnern vorzunehmen.
Eine andere Möglichkeit besteht darin, sich bei Ihrem FTP-Client oder dem Dateimanager Ihres Hosting-Providers anzumelden. Dies ist die bevorzugte Methode unter Entwicklern, da sie unter anderem die vollständige Kontrolle darüber haben, wie die Datei bearbeitet wird.
Falsches URL-Format
URLs auf Ihrer Website, die eigentlich keine „Seiten“ im eigentlichen Sinne sind, erhalten möglicherweise die Meldung „Indiziert, obwohl von robots.txt blockiert“.
Beispielsweise ist https://example.com?s=what+is+seo eine Seite auf einer Website, die die Suchergebnisse für die Suchanfrage „Was ist SEO“ anzeigt. Diese URL ist unter WordPress-Sites weit verbreitet, auf denen die Suchfunktion seitenweit aktiviert ist.
Behebung: Normalerweise muss dieses Problem nicht behoben werden, vorausgesetzt, die URL ist harmlos und beeinträchtigt Ihren Suchverkehr nicht grundlegend.
Seiten, die Sie nicht indizieren möchten, haben interne Links
Selbst wenn Sie auf der Seite, die Sie nicht indexieren möchten, ein noindex-Tag haben, behandelt Google diese möglicherweise als Vorschläge und nicht als Regeln. Dies ist offensichtlich, wenn Sie auf Seiten Ihrer Website, die von Suchmaschinen gecrawlt und indexiert werden, entweder mit der Noindex-Anweisung oder der Disallow-Regel auf Seiten verlinken.
Daher können Sie diese Seiten auf SERPs sehen, auch wenn Sie dies nicht möchten.
Behebung : Sie müssen die Links entfernen, die auf diese bestimmte Seite verweisen, und sie stattdessen zu einer ähnlichen Seite führen.
Dazu müssen Sie die internen Links identifizieren, indem Sie ein SEO-Audit mit einem Tool wie Screaming Frog (kostenlos für Websites mit 500 URLs) oder Ahrefs Webmaster Tools (eine viel bessere kostenlose Alternative) durchführen, um festzustellen, welche Seiten auf Ihre blockierten Seiten verlinken.
Gehen Sie mit Ahrefs zu Berichte > Interne Seiten, nachdem Sie ein Audit durchgeführt haben. Finden Sie die Seiten, die Sie für Webcrawler blockiert und noindexed haben, und sehen Sie in der Spalte Anzahl der Inlinks, welche Seiten auf sie verlinken.
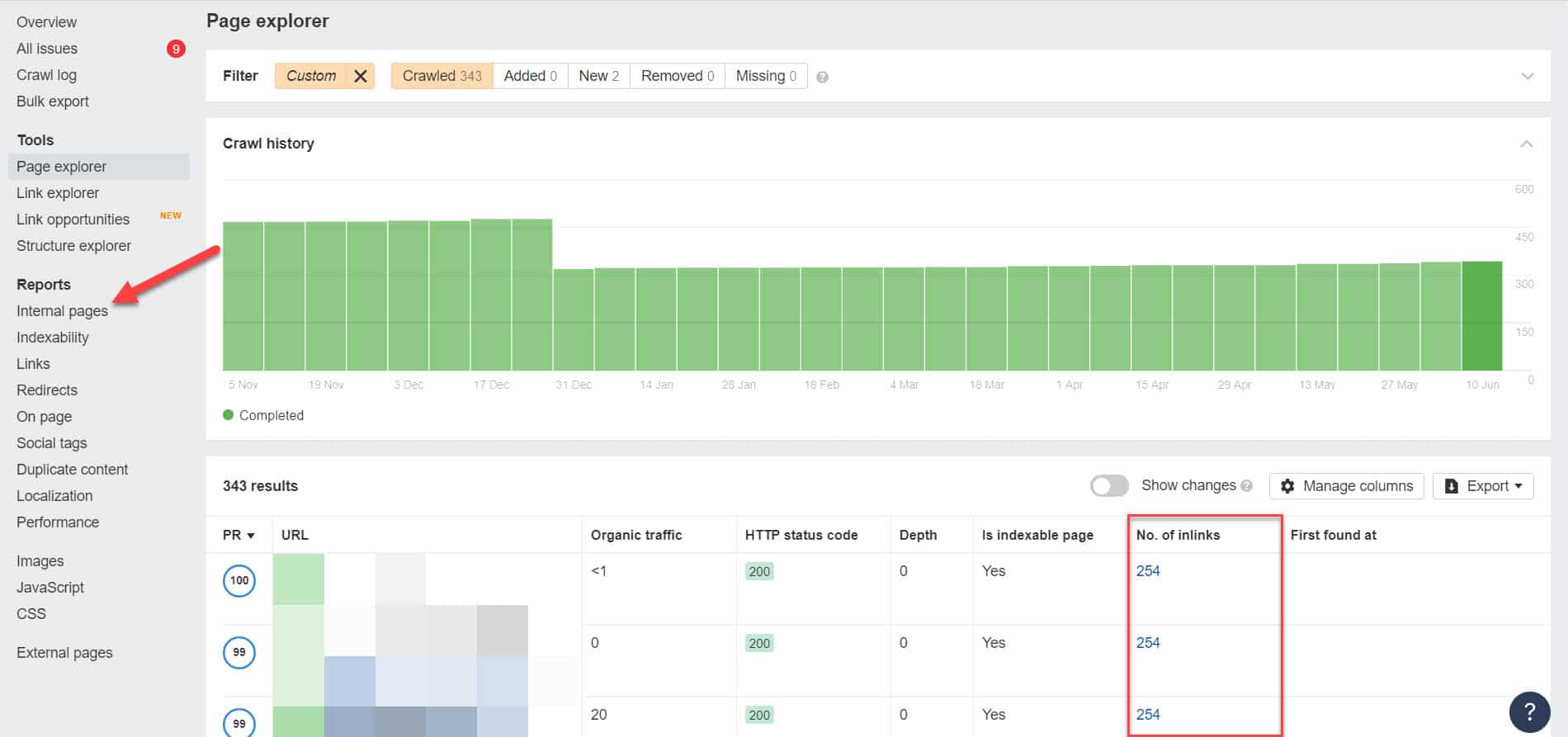
Bearbeiten Sie von hier aus die Links von diesen Seiten einzeln. Oder Sie können sie durch einen Link zu Ihrer Seite mit einem noindex-Tag ersetzen.
Hinweis auf eine Umleitungskette
Wenn ein Link auf Ihrer Website auf einen endlosen Strom von Weiterleitungen verweist, hört der Googlebot auf, jeden Link weiterzuleiten, bevor er die tatsächliche URL zu der Seite findet.
Diese Umleitungsketten könnten auch Probleme mit duplizierten Inhalten verursachen, die später größere SEO-Probleme verursachen könnten. Die einzige Möglichkeit, dies zu lösen, besteht darin, Ihre bevorzugte und kanonische Seite mit dem kanonischen Tag zu identifizieren, damit Google weiß, welche Seite unter vielen gecrawlt und indexiert werden soll.
Bedenken Sie auch, dass die Verlinkung zur Weiterleitung anstelle der kanonischen Seite Ihr Crawl-Budget aufbraucht. Wenn der Weiterleitungslink auf mehrere Weiterleitungen verweist, können Sie Ihr Crawl-Budget nicht auf wichtigen Seiten Ihrer Website verwenden. Bis die wichtigsten Seiten erreicht sind, kann Google sie nach einiger Zeit nicht mehr richtig crawlen und indizieren.
Behebung : Entfernen Sie die Weiterleitungslinks von Ihrer Website und verlinken Sie stattdessen auf die kanonische Seite.
Wenn Sie Ahrefs Webmaster Tools erneut verwenden, können Sie Ihre Weiterleitungslinks auf der Seite Tools > Link Explorer anzeigen. Filtern Sie dann die Ergebnisse, um nur die Weiterleitungslinks auf Ihrer Website anzuzeigen.
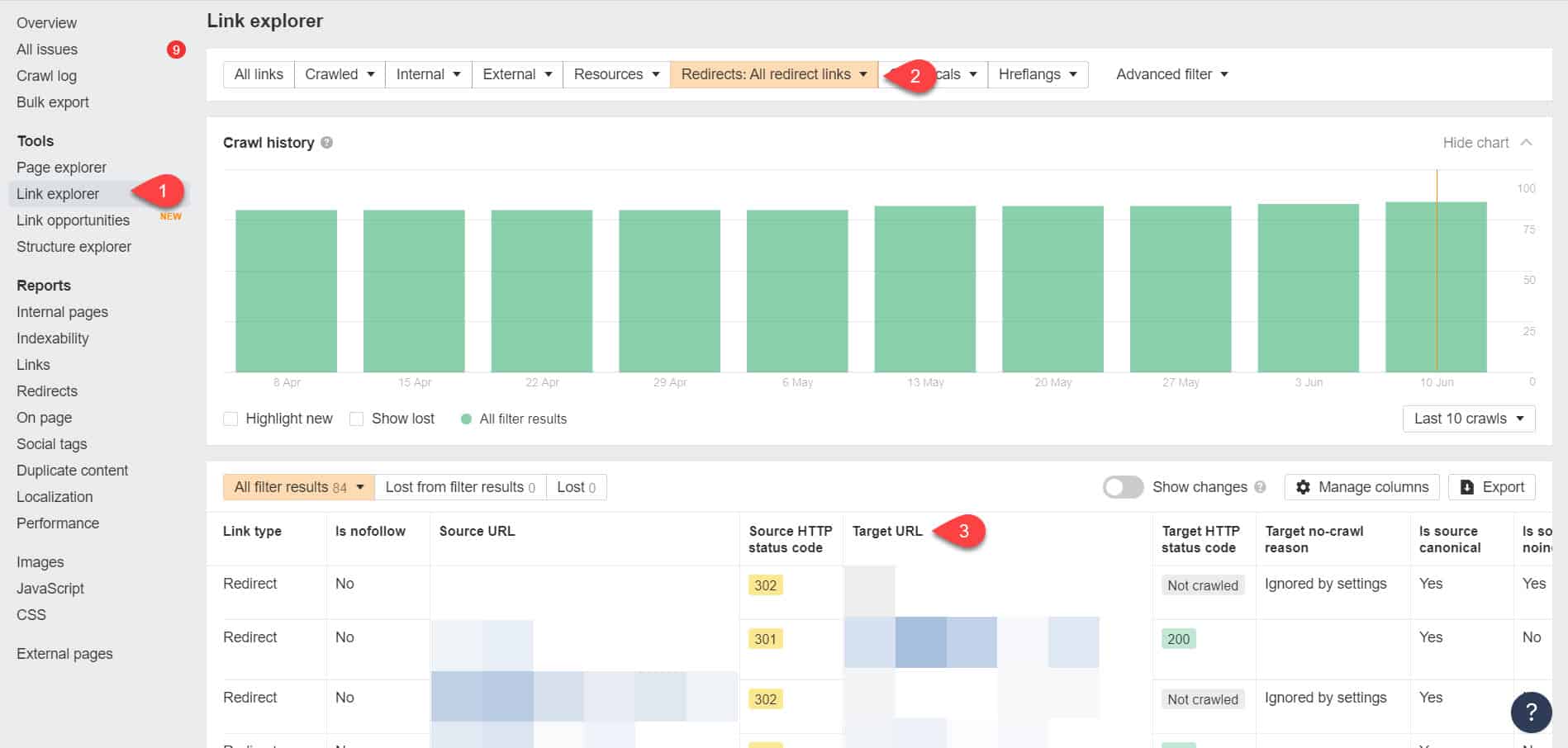
Identifizieren Sie anhand der Ergebnisse, welche Links eine endlose Weiterleitungskette bilden. Unterbrechen Sie dann die Kette, indem Sie die richtige Seite finden, auf die jede Seite, die auf die Weiterleitungen verweist, verlinken sollte.
Vorgehensweise nach Behebung dieses Problems
Nachdem Sie die oben genannten Lösungen für wichtige Seiten mit dem Problem „Indiziert, obwohl von Robots.txt blockiert“ implementiert haben, müssen Sie die Änderungen überprüfen, damit die Google Search Console sie als gelöst markieren kann.
Kehren Sie zum Bericht zur Indexabdeckung in GSC zurück und klicken Sie auf die Links mit diesem Problem, das Sie behoben haben. Klicken Sie im nächsten Bildschirm auf die Schaltfläche Fix validieren.
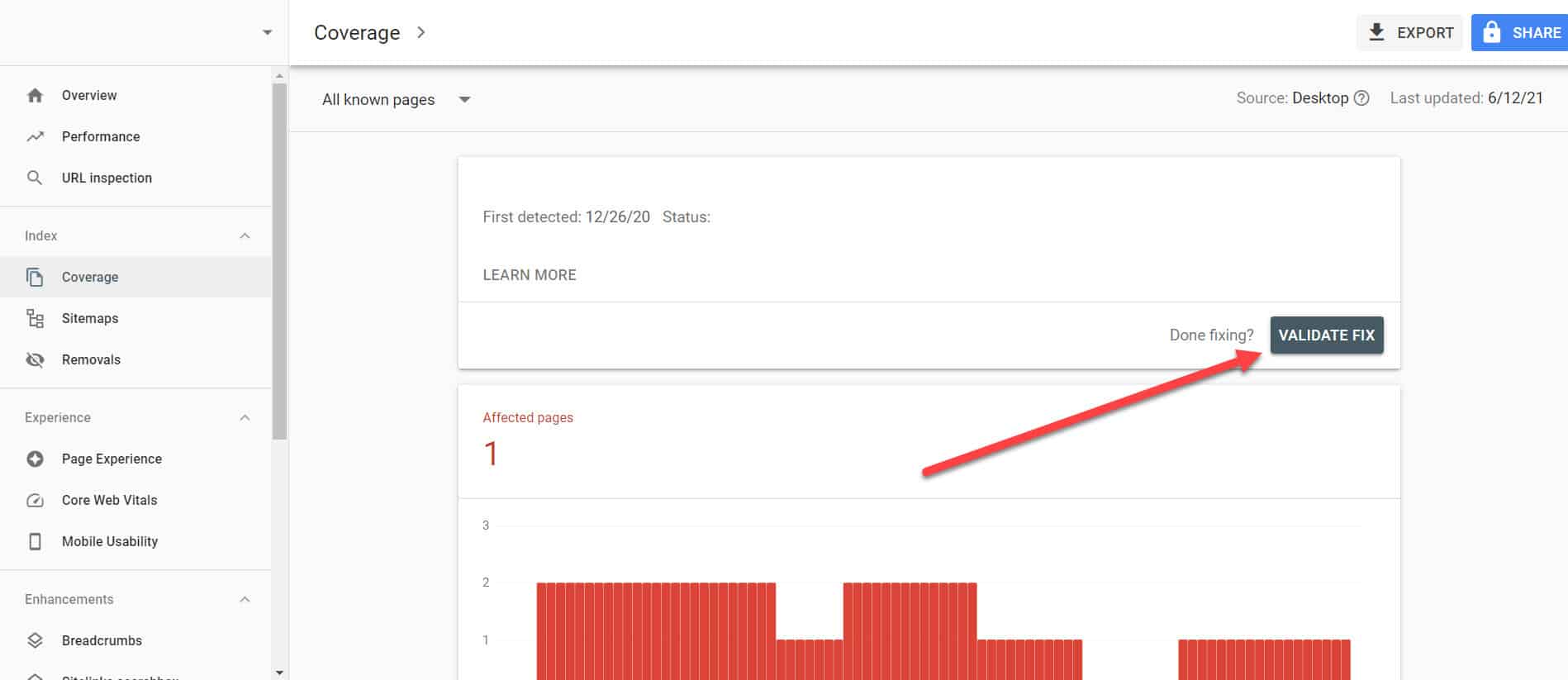
Dadurch wird Google aufgefordert, zu überprüfen, ob das Problem auf der Seite nicht mehr auftritt.
Fazit
Im Gegensatz zu anderen Problemen, die von der Google Search Console aufgedeckt wurden, scheint „Indiziert, obwohl von robots.txt blockiert“ wie ein Tropfen auf den heißen Stein zu sein. Diese Einbrüche könnten sich jedoch zu einer Flut von Problemen auf Ihrer gesamten Website ansammeln, die sie daran hindern, organischen Traffic zu generieren.
Indem Sie die obigen Richtlinien zur Behebung des Problems auf Ihren wichtigsten Seiten befolgen, können Sie verhindern, dass Ihre Website wertvollen Traffic verliert, indem Sie Ihre Website für Google so optimieren, dass sie ordnungsgemäß gecrawlt und indexiert wird.