
我的网络数据爬虫坏了——我该如何修复它?
已发表: 2021-07-30在日益数字化的时代,数据是新的货币。 这是决定您能否跟上竞争对手的众多因素之一。 一个人拥有的数据越多,对他就越有利。 获取数据的一种方法是通过网络数据爬虫。
图:网页抓取多个网站并聚合数据
企业网络数据爬虫
网页抓取是指从网站中提取数据的过程。 用于提取数据的机器人被称为数据爬虫或蜘蛛。 它不是逐个像素的提取,而是提取底层的 HTML 代码和包含在其中的数据。 大量企业依赖网络抓取来获取数据——从使用社交媒体数据进行情绪分析的市场研究公司到为卖家网站自动获取价格的网站。
网页抓取或网页数据爬虫技术
手动刮
手动抓取是复制/粘贴相关信息并创建电子表格以跟踪数据。 就像手动刮音一样简单,它有其优点和缺点:
优点
- 最简单的网络抓取方法之一,它不需要任何先验知识或技能来使用网络数据爬虫。
- 几乎没有错误余地,因为它允许在提取过程中进行人工检查。
- 围绕网络抓取过程的问题之一是快速提取通常会导致网站阻止访问。 由于手动抓取是一个缓慢的过程,因此不会出现被阻塞的问题。
缺点
- 速度慢也是时间管理的麻烦。 机器人的抓取速度明显快于人类。
自动抓取
自动网络抓取或网络数据爬虫可以通过编写代码和创建自己的 DIY 网络抓取引擎来完成,或者使用基于订阅的工具来完成,这些工具可以由您的业务团队通过一周的培训来操作。 随着时间的推移,多种基于无代码的工具变得流行起来,因为它们易于使用并节省时间和金钱。
对于那些想要创建他们的网络数据爬虫或抓取工具的人,您可以让自己的团队编写需要执行的阶段以从多个网页收集数据,然后通过部署具有这些信息的爬虫来自动化整个过程云端。 涉及自动抓取的过程通常包括以下一项或多项:
HTML 解析: HTML 解析使用 JavaScript,用于线性或嵌套的 HTML 页面。 它通常用于链接提取、屏幕抓取、文本提取、资源提取等。

DOM 解析:文档对象模型或 DOM 用于理解 XML 文件中的样式、结构和内容。 当爬虫想要深入了解网页结构时,就会使用 DOM 解析器。 可以使用 DOM 解析器找到携带信息的节点,然后使用 XPath 等工具抓取网页。 即使生成的内容是动态的,也可以将 Internet Explorer 或 Mozilla Firefox 等 Web 浏览器与某些插件一起使用,以从网页中提取相关数据。
垂直聚合:垂直聚合平台是由可以访问大规模计算能力以针对特定垂直领域的公司创建的。 有时,公司也会利用云来运行这些平台。 机器人由平台创建和监控,无需任何基于垂直知识库的人工干预。 由于这个原因,创建的机器人的效率取决于它们提取的数据的质量。
XPath: XML 路径语言或 XPath,是一种用于 XML 文档的查询语言。 因为 XML 文档具有树状结构,所以 XPath 用于通过基于各种参数选择节点来进行导航。 XPath 和 DOM 解析可用于提取整个网页。
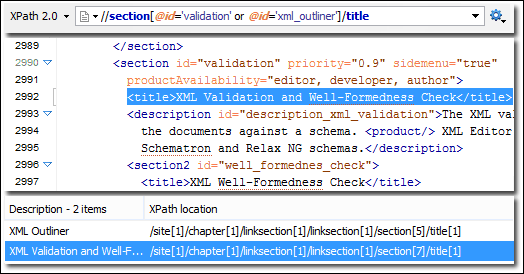
图:使用 Xpath 提取数据。 来源:XPath 支持 (oxygenxml.com)
谷歌表格:谷歌表格是刮板的流行选择。 借助 Sheets,IMPORTXML (,) 函数可用于从网站上抓取数据。 当刮板想要从网站中提取特定数据或模式时,它特别有用。 该命令还可用于检查您的网站是否防刮。
文本模式匹配:这是一种使用 UNIX grep 命令的常用表达式匹配技术,通常与 Perl 或 Python 等编程语言结合使用。
这样的网络爬虫工具和服务在网上广泛可用,如果爬虫者不想自己进行爬虫,则不必对上述技术非常熟练。 CURL、Wget、HTTrack、Import.io、Node.js 等工具是高度自动化的。 网络爬虫也可以使用自动无头浏览器,例如 Phantom.js、Slimmer.js、Casper.js。
优点
- 自动抓取或网络数据爬虫可以帮助您在几秒钟内从数千个网页中提取数百个数据点。
- 这些工具易于使用。 即使是不熟练或业余的编码人员也可以使用用户友好的 UI 从 Internet 上抓取数据。
- 可以将某些工具设置为按计划运行,然后将提取的数据以 Google 表格或 JSON 文件的形式提供。
- 像 Python 这样的大多数语言都带有像 BeautifulSoup 这样的专用库,可以帮助轻松地从网络上抓取数据。
缺点
- 这些工具需要培训,而 DIY 解决方案需要经验——因此您要么需要将业务团队的一些精力投入到网页抓取上,要么让技术团队来处理网页抓取工作。
- 大多数工具都有一些限制,其中一个可能无法帮助您抓取登录屏幕后面的数据,而其他工具可能会遇到嵌入内容的问题。
- 对于付费的无代码工具,可能会要求升级,但补丁可能会很慢,并且在紧迫的期限内工作时可能无济于事。
数据即服务(或 DaaS)
顾名思义,这意味着将您的完整数据提取过程外包。 你的基础设施,你的代码,维护,一切都得到了照顾。 您提供要求并获得结果。
网页抓取的过程很复杂,需要熟练的编码人员。 维持内部爬行设置所需的基础设施和人力可能变得过于繁重,尤其是对于尚未拥有内部技术团队的公司而言。 在这种情况下,最好使用外部网络抓取服务。
使用 DaaS 有很多好处,其中一些是:
专注核心业务
与其将时间和精力花在网络抓取的技术方面以及建立一个围绕它的整个团队,不如将工作外包,从而将重点放在核心业务上。
与 DIY 网络数据爬虫相比具有成本效益
内部网络抓取解决方案将比获得 DaaS 服务成本更高。 网页抓取不是一件容易的工作,而且复杂性意味着您必须聘请熟练的开发人员,从长远来看这将花费您。 由于大多数 DaaS 解决方案仅根据使用情况向您收费,因此您只需为提取的数据点和总数据大小付费。
无需维护
当您构建内部解决方案或使用网络抓取工具时,由于网站的变化或其他可能需要立即修复的技术问题而导致机器人崩溃的额外开销。 这可能意味着某人或团队总是需要注意抓取的数据中的不准确之处,并检查整个系统的停机时间。 由于网站可能经常更改,因此每次更改代码时都需要更新代码,否则会有崩溃的风险。 使用 DaaS 提供商,您将永远不必承担维护内部网络抓取解决方案的额外麻烦。
当涉及网络抓取或网络数据爬虫时,您可以根据您的具体需求从上面讨论的方法中进行选择。 但是,如果您需要企业级 DaaS 解决方案,我们在 PromptCloud 提供完全托管的 DaaS 服务,可以根据您的喜好为您提供清理和格式化的抓取数据点。 您需要指定您的要求,我们将为您提供您可以即插即用的数据。 使用 DaaS 解决方案,您可以忘记维护、基础设施、时间和成本的不便,或者在从站点抓取时被阻止。 我们是按使用付费的基于云的服务,可满足您的需求并满足您的抓取要求。