
Mój internetowy robot indeksujący jest uszkodzony — jak to naprawić?
Opublikowany: 2021-07-30W erze postępującej cyfryzacji dane są nową walutą. To jeden z wielu czynników, które zadecydują, czy dotrzymasz kroku konkurencji. Im więcej danych ma, tym korzystniej będzie dla niego. Jednym ze sposobów uzyskania danych jest przeszukiwarka danych internetowych.
Rys: Web Scraping wielu witryn i agregowanie danych
Internetowy robot indeksujący dane dla firm
Web scraping odnosi się do procesu, w którym dane są pobierane ze stron internetowych . Boty używane do wyodrębniania danych są określane jako roboty indeksujące lub pająki danych. Nie jest to ekstrakcja piksel po pikselu, ale raczej ekstrakcja bazowego kodu HTML i danych w nim pochłoniętych. Mnóstwo firm polega na zbieraniu danych z sieci — od firm zajmujących się badaniem rynku, które wykorzystują dane z mediów społecznościowych do analizy nastrojów, po witryny, które automatycznie pobierają ceny dla witryn sprzedawców.
Web Scraping lub techniki przeszukiwacza danych internetowych
Skrobanie ręczne
Skrobanie ręczne to kopiowanie/wklejanie odpowiednich informacji i tworzenie arkusza kalkulacyjnego w celu śledzenia danych. Tak proste, jak dźwięki ręcznego skrobania, ma swoje zalety i wady:
Plusy
- Jedna z najłatwiejszych metod web scrapingu, nie wymaga wcześniejszej wiedzy ani umiejętności korzystania z robota indeksującego dane internetowe.
- Margines błędu jest niewielki, ponieważ pozwala na kontrole przez człowieka podczas procesu ekstrakcji.
- Jednym z problemów związanych z procesem web scrapingu jest to, że szybkie wyodrębnianie często powoduje zablokowanie dostępu przez witrynę. Ponieważ ręczne skrobanie jest procesem powolnym, nie pojawia się kwestia zablokowania.
Cons
- Niska prędkość jest również kłopotliwa w zarządzaniu czasem. Boty są znacznie szybsze w skrobaniu niż ludzie.
Automatyczne skrobanie
Zautomatyzowany web scraping lub web data crawler można wykonać, pisząc kod i tworząc własny silnik do samodzielnego scrapingu lub korzystając z narzędzi opartych na subskrypcji, które mogą być obsługiwane przez zespół biznesowy po tygodniu szkolenia. Z czasem popularne stało się wiele narzędzi nie opartych na kodzie, ponieważ są one łatwe w użyciu i oszczędzają zarówno czas, jak i pieniądze.
Jeśli chodzi o tych, którzy chcą tworzyć swoje roboty indeksujące lub skrobaki danych internetowych, możesz pozyskać zespół, który zakoduje etapy, które należy wykonać, aby zebrać dane z wielu stron internetowych, a następnie zautomatyzować cały proces, wdrażając roboty indeksujące posiadające te informacje w Chmura. Procesy związane z automatycznym skrobaniem zwykle obejmują co najmniej jedno z poniższych:
Parsowanie HTML: parsowanie HTML wykorzystuje JavaScript i jest używane do liniowych lub zagnieżdżonych stron HTML. Jest zwykle używany do ekstrakcji linków, przechwytywania ekranu, ekstrakcji tekstu, ekstrakcji zasobów i innych.
Analiza DOM: Document Object Model (DOM) służy do zrozumienia stylu, struktury i zawartości plików XML. Parsery DOM są używane, gdy scraper chce uzyskać dogłębny wgląd w strukturę strony internetowej. Parser DOM może być użyty do znalezienia węzłów, które przenoszą informacje, a następnie za pomocą narzędzi takich jak strony internetowe XPath można je zeskrobać. Przeglądarek internetowych, takich jak Internet Explorer lub Mozilla Firefox, można używać wraz z określonymi wtyczkami do wyodrębniania odpowiednich danych ze stron internetowych, nawet jeśli generowana zawartość jest dynamiczna.
Agregacja pionowa: platformy agregacji pionowej są tworzone przez firmy, które mają dostęp do dużej mocy obliczeniowej, aby kierować reklamy na określone branże. Czasami firmy wykorzystują chmurę również do obsługi tych platform. Boty są tworzone i monitorowane przez platformy bez konieczności ingerencji człowieka w oparciu o bazę wiedzy dla branży. Z tego powodu wydajność tworzonych botów zależy od jakości wydobywanych przez nie danych.
XPath: XML Path Language lub XPath to język zapytań używany w dokumentach XML. Ponieważ dokumenty XML mają strukturę podobną do drzewa, XPath służy do nawigacji poprzez wybieranie węzłów na podstawie różnych parametrów. XPath wraz z parsowaniem DOM może być użyty do wyodrębnienia całych stron internetowych.

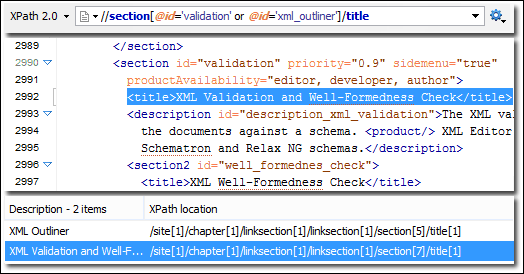
Rys: Wyodrębnianie danych za pomocą XPath. Źródło: Wsparcie XPath (oxygenxml.com)
Arkusze Google: Arkusze Google to popularny wybór dla skrobaków. W Arkuszach funkcja IMPORTXML (,) może być używana do pobierania danych z witryn internetowych. Jest to szczególnie przydatne, gdy scraper chce wydobyć określone dane lub wzorce ze strony internetowej. Polecenia można również użyć do sprawdzenia, czy Twoja witryna jest odporna na zadrapania.
Dopasowywanie wzorców tekstowych: Jest to powszechna technika dopasowywania wyrażeń, która korzysta z polecenia grep systemu UNIX i jest zwykle dołączana do języków programowania, takich jak Perl lub Python.
Takie narzędzia i usługi zgarniania z sieci są szeroko dostępne online, a sami zgarniacze nie muszą być wysoko wykwalifikowani w powyższych technikach, jeśli nie chcą samodzielnie wykonywać zdrapywania. Narzędzia takie jak CURL, Wget, HTTrack, Import.io, Node.js i inne są wysoce zautomatyzowane. Zautomatyzowane przeglądarki bezgłowe, takie jak Phantom.js, Slimmer.js, Casper.js, mogą być również używane przez web scraper.
Plusy
- Zautomatyzowane skrobanie lub przeszukiwarka danych internetowych może pomóc w wyodrębnieniu setek punktów danych z tysięcy stron internetowych w ciągu kilku sekund.
- Narzędzia są łatwe w użyciu. Nawet niewykwalifikowany lub amatorski programista może skorzystać z przyjaznych dla użytkownika interfejsów użytkownika, aby zeskrobać dane z Internetu.
- Niektóre narzędzia można ustawić tak, aby działały zgodnie z harmonogramem, a następnie dostarczały wyodrębnione dane w arkuszu Google lub pliku JSON.
- Większość języków, takich jak Python, jest dostarczana z dedykowanymi bibliotekami, takimi jak BeautifulSoup, które mogą pomóc w łatwym pobieraniu danych z sieci.
Cons
- Narzędzia wymagają szkolenia, a rozwiązania dla majsterkowiczów wymagają doświadczenia, więc albo musisz poświęcić trochę energii swojego zespołu biznesowego na skrobanie sieci, albo pozyskać zespół techniczny do obsługi prac związanych ze skrobaniem sieci.
- Większość narzędzi ma pewne ograniczenia, jedno może nie być w stanie pomóc w zeskrobaniu danych znajdujących się za ekranem logowania, podczas gdy inne mogą mieć problemy z osadzoną zawartością.
- W przypadku płatnych narzędzi bez kodu mogą być wymagane aktualizacje, ale poprawki mogą być powolne i mogą nie być pomocne w pracy z napiętymi terminami.
Dane jako usługa (lub DaaS)
Jak sama nazwa wskazuje, przekłada się to na outsourcing całego procesu ekstrakcji danych. Twoja infrastruktura, Twój kod, konserwacja, wszystko jest pod opieką. Podajesz wymagania i otrzymujesz wyniki.
Proces skrobania wstęgi jest skomplikowany i wymaga wykwalifikowanych koderów. Infrastruktura wraz z siłą roboczą wymaganą do utrzymania wewnętrznej konfiguracji indeksowania może stać się zbyt uciążliwa, szczególnie dla firm, które nie mają jeszcze własnego zespołu technicznego. W takich przypadkach lepiej jest skorzystać z zewnętrznej usługi web-scrapingu.
Korzystanie z DaaS ma wiele zalet, a niektóre z nich to:
Skoncentruj się na podstawowej działalności
Zamiast spędzać czas i wysiłek na technicznych aspektach web scrapingu i tworzeniu całego zespołu, aby się wokół niego kręcił, outsourcing pracy pozwala skupić się na podstawowej działalności.
Opłacalny w porównaniu do DIY Web Data Crawler
Własne rozwiązanie do skrobania sieci będzie kosztować więcej niż uzyskanie usługi DaaS. Web scraping nie jest łatwym zadaniem, a złożoność oznacza, że będziesz musiał zdobyć wykwalifikowanych programistów, co będzie cię kosztować na dłuższą metę. Ponieważ większość rozwiązań DaaS będzie pobierać opłaty tylko na podstawie wykorzystania, będziesz płacić tylko za wyodrębnione punkty danych i całkowity rozmiar danych.
Brak konserwacji
Kiedy budujesz własne rozwiązanie lub używasz narzędzi do skrobania stron internetowych, pojawia się dodatkowy narzut związany z awarią bota z powodu zmian na stronach internetowych lub innych problemów technicznych, które mogą wymagać natychmiastowej naprawy. Może to oznaczać, że ktoś lub zespół będzie musiał zawsze zwracać uwagę na nieścisłości w zeskrobanych danych i kontrolować ogólny czas przestoju systemu. Ponieważ strony internetowe mogą się często zmieniać, kod będzie musiał być aktualizowany za każdym razem, gdy to zrobi, w przeciwnym razie wystąpi ryzyko awarii. Dzięki dostawcom DaaS nigdy nie będziesz musiał ponosić dodatkowych kłopotów związanych z utrzymywaniem własnego rozwiązania do zgarniania sieci.
Jeśli chodzi o web scraping lub web data crawler, możesz wybierać spośród omówionych powyżej metod zgodnie ze swoimi konkretnymi potrzebami. Jeśli jednak potrzebujesz rozwiązania DaaS klasy korporacyjnej, w PromptCloud oferujemy w pełni zarządzaną usługę DaaS, która może zapewnić, że zeskrobane punkty danych zostaną oczyszczone i sformatowane zgodnie z Twoimi preferencjami. Musisz sprecyzować swoje wymagania, a my dostarczymy Ci dane, które możesz podłączyć i odtwarzać. Dzięki rozwiązaniu DaaS możesz zapomnieć o niedogodnościach związanych z utrzymaniem, infrastrukturą, czasem i kosztami lub blokowaniem podczas zdrapywania ze strony. Jesteśmy usługą w chmurze typu pay-per-use, która zaspokoi Twoje wymagania i spełni Twoje wymagania dotyczące złomowania.