
Il mio Web Data Crawler è danneggiato: come posso risolverlo?
Pubblicato: 2021-07-30In un'era di crescente digitalizzazione, i dati sono la nuova valuta. È uno dei tanti fattori che decideranno se puoi stare al passo con i tuoi concorrenti. Più dati si ha, più sarà vantaggioso per lui. E un modo per ottenere i dati è tramite il crawler di dati web.
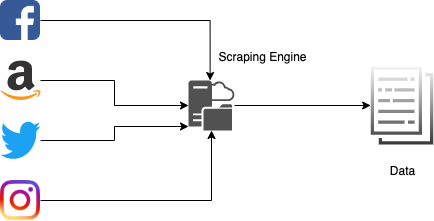
Fig: Web Scraping più siti Web e aggregazione di dati
Crawler di dati Web per le aziende
Il web scraping si riferisce a un processo in cui i dati vengono estratti dai siti web . I bot utilizzati per estrarre i dati sono indicati come crawler di dati o spider. Non è un'estrazione pixel per pixel, ma piuttosto l'estrazione del codice HTML sottostante e dei dati in esso inglobati. Un sacco di aziende si affidano al web scraping per i dati, dalle società di ricerche di mercato che utilizzano i dati dei social media per l'analisi del sentiment a siti che recuperano automaticamente i prezzi per i siti Web dei venditori.
Tecniche di Web Scraping o Web Data Crawler
Raschiamento manuale
Lo scraping manuale consiste nel copiare/incollare informazioni rilevanti e creare un foglio di calcolo per tenere traccia dei dati. Semplice come un suono di raschiamento manuale, ha i suoi pro e contro:
Professionisti
- Uno dei metodi più semplici di scraping web, non richiede alcuna conoscenza o abilità pregressa per l'utilizzo del crawler di dati web.
- C'è poco margine di errore in quanto consente controlli umani durante il processo di estrazione.
- Uno dei problemi che circonda il processo di scraping web è che l'estrazione rapida spesso causa il blocco dell'accesso al sito web. Poiché la raschiatura manuale è un processo lento, la questione del blocco non si pone.
contro
- La bassa velocità è anche una seccatura per la gestione del tempo. I robot sono significativamente più veloci nello scraping rispetto agli umani.
Raschiamento automatizzato
Il web scraping automatizzato o il web data crawler può essere eseguito scrivendo il codice e creando il tuo motore di scraping web fai-da-te, oppure utilizzando strumenti basati su abbonamento che possono essere gestiti dal tuo team aziendale con una settimana di formazione. Più strumenti senza codice sono diventati popolari con il tempo in quanto sono facili da usare e consentono di risparmiare tempo e denaro.
Per quanto riguarda coloro che desiderano creare i propri crawler o scraper di dati Web, è possibile ottenere un team che codifichi le fasi che devono essere eseguite per raccogliere dati da più pagine Web e quindi automatizzare l'intero processo distribuendo crawler con queste informazioni in la nuvola. I processi coinvolti con lo scraping automatizzato di solito includono uno o più dei seguenti:
Analisi HTML: l'analisi HTML utilizza JavaScript e viene utilizzata per pagine HTML lineari o annidate. Viene generalmente utilizzato per l'estrazione di collegamenti, l'acquisizione di schermate, l'estrazione di testo, l'estrazione di risorse e altro ancora.
Analisi DOM: il Document Object Model, o DOM, viene utilizzato per comprendere lo stile, la struttura e il contenuto all'interno dei file XML. I parser DOM vengono utilizzati quando lo scraper desidera ottenere una visione approfondita della struttura di una pagina Web. Un parser DOM può essere utilizzato per trovare i nodi che trasportano informazioni e quindi con l'uso di strumenti come le pagine Web XPath possono essere raschiate. I browser Web come Internet Explorer o Mozilla Firefox possono essere utilizzati insieme a determinati plug-in per estrarre dati rilevanti dalle pagine Web anche quando il contenuto generato è dinamico.
Aggregazione verticale: le piattaforme di aggregazione verticale sono create da aziende che hanno accesso a potenza di calcolo su larga scala per puntare su verticali specifici. A volte, anche le aziende utilizzano il cloud per eseguire queste piattaforme. I bot vengono creati e monitorati dalle piattaforme senza la necessità di alcun intervento umano basato sulla base di conoscenze per la verticale. Per questo motivo, l'efficienza dei bot creati dipende dalla qualità dei dati che estraggono.

XPath: XML Path Language, o XPath, è un linguaggio di query utilizzato sui documenti XML. Poiché i documenti XML hanno una struttura ad albero, XPath viene utilizzato per navigare selezionando i nodi in base a una varietà di parametri. XPath insieme all'analisi DOM possono essere utilizzati per estrarre intere pagine Web.
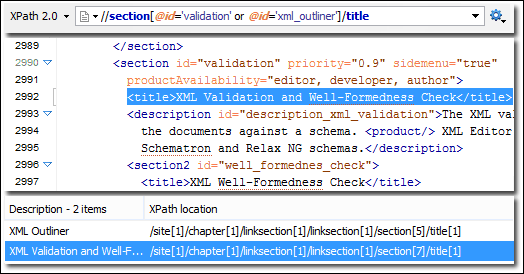
Fig: estrazione di dati utilizzando Xpath. Fonte: supporto XPath (oxygenxml.com)
Fogli Google: Fogli Google è una scelta popolare per gli scraper. Con Fogli, la funzione IMPORTXML (,) può essere utilizzata per raschiare i dati dai siti web. È particolarmente utile quando lo scraper vuole estrarre dati o schemi specifici da un sito web. Il comando può essere utilizzato anche per verificare se il tuo sito Web è a prova di graffio.
Corrispondenza di modelli di testo: questa è una tecnica comune di corrispondenza di espressioni che utilizza il comando UNIX grep e di solito è incorporata con linguaggi di programmazione come Perl o Python.
Tali strumenti e servizi di scraping web sono ampiamente disponibili online e gli scraper stessi non devono essere altamente qualificati nelle tecniche di cui sopra se non vogliono eseguire lo scraping da soli. Strumenti come CURL, Wget, HTTrack, Import.io, Node.js e altri sono altamente automatizzati. Anche i browser headless automatizzati come Phantom.js, Slimmer.js, Casper.js possono essere utilizzati dal web scraper.
Professionisti
- Lo scraping automatizzato o il crawler di dati Web possono aiutarti a estrarre centinaia di punti dati da migliaia di pagine Web in pochi secondi.
- Gli strumenti sono facili da usare. Anche un programmatore inesperto o dilettante può utilizzare interfacce utente intuitive per acquisire dati da Internet.
- Alcuni degli strumenti possono essere impostati per essere eseguiti in base a una pianificazione e quindi fornire i dati estratti in un foglio Google o in un file JSON.
- La maggior parte dei linguaggi come Python viene fornita con librerie dedicate come BeautifulSoup che possono aiutare a raccogliere facilmente i dati dal Web.
contro
- Gli strumenti richiedono formazione e le soluzioni fai-da-te richiedono esperienza, quindi devi dedicare un po' di energia del tuo team aziendale allo scraping web o affidarti a un team tecnico per gestire gli sforzi di scraping web.
- La maggior parte degli strumenti presenta alcune limitazioni, uno potrebbe non essere in grado di aiutarti a raschiare i dati che si trovano dietro una schermata di accesso, mentre altri potrebbero avere problemi con i contenuti incorporati.
- Per gli strumenti senza codice a pagamento, potrebbero essere richiesti aggiornamenti, ma le patch possono essere lente e potrebbero non rivelarsi utili quando si lavora con scadenze difficili.
Data as a Service (o DaaS)
Come suggerisce il nome, questo si traduce nell'esternalizzare il processo completo di estrazione dei dati. La tua infra, il tuo codice, la manutenzione, tutto è curato. Fornisci i requisiti e ottieni i risultati.
Il processo di web scraping è complicato e richiede programmatori esperti. L'infrastruttura e la manodopera necessaria per sostenere una configurazione di scansione interna possono diventare troppo onerose, soprattutto per le aziende che non dispongono già di un team tecnico interno. In questi casi è meglio avvalersi di un servizio di web scraping esterno.
Ci sono molti vantaggi nell'usare un DaaS, alcuni dei quali sono:
Concentrati sul core business
Invece di dedicare tempo e fatica agli aspetti tecnici del web scraping e alla creazione di un intero team che ruota attorno ad esso, l'outsourcing del lavoro consente di mantenere l'attenzione sul core business.
Economico rispetto al crawler di dati Web fai-da-te
Una soluzione di web scraping interna costerà di più rispetto a ottenere un servizio DaaS. Il web scraping non è un lavoro facile e le complessità significano che dovrai ottenere sviluppatori esperti che a lungo termine ti costeranno. Poiché la maggior parte delle soluzioni DaaS ti addebiterà solo in base all'utilizzo, pagherai solo per i punti dati estratti e la dimensione totale dei dati.
Nessuna manutenzione
Quando crei una soluzione interna o utilizzi strumenti di scraping web, c'è un sovraccarico aggiuntivo di un bot che si interrompe a causa di modifiche ai siti Web o altri problemi tecnici che potrebbero dover essere risolti immediatamente. Ciò potrebbe significare che qualcuno o un team dovrebbe sempre prestare attenzione alle imprecisioni nei dati raschiati e tenere sotto controllo i tempi di inattività complessivi del sistema. Poiché i siti Web possono cambiare spesso, il codice dovrà essere aggiornato ogni volta che lo fa o ci sarà il rischio di un guasto. Con i provider DaaS, non dovrai mai sopportare le seccature aggiuntive legate alla manutenzione di una soluzione di web scraping interna.
Quando si tratta di web scraping o web data crawler, puoi scegliere tra i metodi discussi sopra in base alle tue esigenze specifiche. Tuttavia, se hai bisogno di una soluzione DaaS di livello aziendale, noi di PromptCloud offriamo un servizio DaaS completamente gestito in grado di fornire punti dati raschiati puliti e formattati in base alle tue preferenze. Devi specificare le tue esigenze e ti forniremo i dati che potrai quindi collegare e riprodurre. Con una soluzione DaaS, puoi dimenticare gli inconvenienti di manutenzione, infrastruttura, tempi e costi o rimanere bloccato durante lo scraping da un sito. Siamo un servizio basato su cloud pay-per-use che soddisferà le tue esigenze e soddisferà i tuoi requisiti di scraping.