
Mein Web Data Crawler ist kaputt – wie kann ich das beheben?
Veröffentlicht: 2021-07-30In Zeiten zunehmender Digitalisierung sind Daten die neue Währung. Es ist einer von vielen Faktoren, die darüber entscheiden, ob Sie mit Ihren Konkurrenten mithalten können. Je mehr Daten man hat, desto vorteilhafter wird es für ihn sein. Und eine Möglichkeit, die Daten zu erhalten, ist der Webdaten-Crawler.
Abb.: Web Scraping mehrerer Websites und Aggregation von Daten
Webdaten-Crawler für Unternehmen
Web Scraping bezieht sich auf einen Prozess, bei dem Daten von Websites extrahiert werden . Die zum Extrahieren der Daten verwendeten Bots werden als Daten-Crawler oder Spider bezeichnet. Es handelt sich nicht um eine Pixel-für-Pixel-Extraktion, sondern um die Extraktion des zugrunde liegenden HTML-Codes und der darin enthaltenen Daten. Viele Unternehmen verlassen sich auf Web-Scraping für Daten – von Marktforschungsunternehmen, die Social-Media-Daten für Stimmungsanalysen verwenden, bis hin zu Websites, die Preise für Verkäufer-Websites automatisch abrufen.
Web Scraping oder Web Data Crawler-Techniken
Manuelles Schaben
Beim manuellen Scraping werden relevante Informationen kopiert/eingefügt und eine Tabelle erstellt, um den Überblick über die Daten zu behalten. So einfach wie manuelles Schaben klingt, hat es seine Vor- und Nachteile:
Vorteile
- Als eine der einfachsten Methoden des Web-Scrapings sind keine Vorkenntnisse oder Fähigkeiten zur Verwendung von Webdaten-Crawlern erforderlich.
- Es gibt wenig Spielraum für Fehler, da menschliche Kontrollen während des Extraktionsprozesses möglich sind.
- Eines der Probleme im Zusammenhang mit dem Web-Scraping-Prozess besteht darin, dass eine schnelle Extraktion häufig dazu führt, dass die Website den Zugriff blockiert. Da das manuelle Schaben ein langsamer Prozess ist, stellt sich die Frage nach einer Blockierung nicht.
Nachteile
- Die langsame Geschwindigkeit ist auch ein Ärgernis für das Zeitmanagement. Bots schaben deutlich schneller als Menschen.
Automatisiertes Schaben
Automatisiertes Web-Scraping oder Web-Daten-Crawler können durch das Schreiben Ihres Codes und die Erstellung Ihrer eigenen DIY-Web-Scraping-Engine oder durch die Verwendung abonnementbasierter Tools durchgeführt werden, die von Ihrem Geschäftsteam mit einer Woche Schulung betrieben werden können. Mehrere No-Code-basierte Tools sind mit der Zeit populär geworden, da sie einfach zu bedienen sind und sowohl Zeit als auch Geld sparen.
Für diejenigen, die ihre Webdaten-Crawler oder Scraper erstellen möchten, können Sie sich ein Team zusammenstellen, das die Phasen codiert, die zum Sammeln von Daten von mehreren Webseiten durchgeführt werden müssen, und dann den gesamten Prozess automatisieren, indem Sie Crawler einsetzen, die diese Informationen enthalten die Wolke. Prozesse, die mit automatisiertem Scraping verbunden sind, umfassen normalerweise eines oder mehrere der folgenden:
HTML-Parsing: HTML-Parsing verwendet JavaScript und wird für lineare oder verschachtelte HTML-Seiten verwendet. Es wird im Allgemeinen für die Link-Extraktion, Bildschirmaufnahme, Textextraktion, Ressourcenextraktion und mehr verwendet.
DOM-Parsing: Das Document Object Model oder DOM wird verwendet, um den Stil, die Struktur und den Inhalt in XML-Dateien zu verstehen. DOM-Parser werden verwendet, wenn der Scraper einen detaillierten Einblick in die Struktur einer Webseite erhalten möchte. Ein DOM-Parser kann verwendet werden, um die Knoten zu finden, die Informationen enthalten, und dann können mit Hilfe von Tools wie XPath Webseiten geschabt werden. Webbrowser wie Internet Explorer oder Mozilla Firefox können zusammen mit bestimmten Plugins verwendet werden, um relevante Daten von Webseiten zu extrahieren, selbst wenn der generierte Inhalt dynamisch ist.
Vertikale Aggregation: Vertikale Aggregationsplattformen werden von Unternehmen erstellt, die Zugang zu umfangreicher Rechenleistung haben, um auf bestimmte Branchen abzuzielen. Manchmal nutzen Unternehmen auch die Cloud, um diese Plattformen zu betreiben. Bots werden von den Plattformen erstellt und überwacht, ohne dass ein menschliches Eingreifen erforderlich ist, basierend auf der Wissensbasis für die Vertikale. Aus diesem Grund hängt die Effizienz der erstellten Bots von der Qualität der extrahierten Daten ab.

XPath: XML Path Language oder XPath ist eine Abfragesprache, die für XML-Dokumente verwendet wird. Da XML-Dokumente eine baumartige Struktur haben, wird XPath zum Navigieren verwendet, indem Knoten basierend auf einer Vielzahl von Parametern ausgewählt werden. XPath zusammen mit DOM-Parsing kann verwendet werden, um ganze Webseiten zu extrahieren.
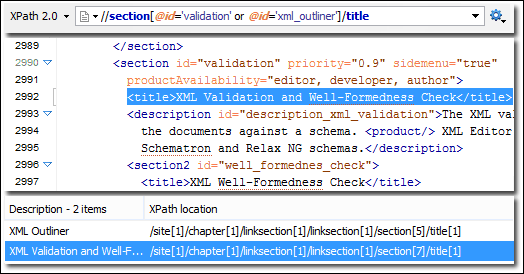
Abb.: Datenextraktion mit Xpath. Quelle: XPath-Unterstützung (oxygenxml.com)
Google Sheets: Google Sheets ist eine beliebte Wahl für Scraper. Bei Sheets kann die Funktion IMPORTXML (,) verwendet werden, um Daten von Websites zu scrapen. Es ist besonders nützlich, wenn der Scraper bestimmte Daten oder Muster von einer Website extrahieren möchte. Der Befehl kann auch verwendet werden, um zu überprüfen, ob Ihre Website kratzfest ist.
Textmusterabgleich: Dies ist eine gängige Technik zum Abgleich von Ausdrücken, die den UNIX-Befehl grep verwendet und normalerweise in Programmiersprachen wie Perl oder Python integriert ist.
Solche Web-Scraping-Tools und -Dienste sind online weit verbreitet, und die Scraper selbst müssen in den oben genannten Techniken nicht hochqualifiziert sein, wenn sie das Scraping nicht selbst durchführen möchten. Tools wie CURL, Wget, HTTrack, Import.io, Node.js und mehr sind hochgradig automatisiert. Automatisierte Headless-Browser wie Phantom.js, Slimmer.js, Casper.js können auch vom Web Scraper verwendet werden.
Vorteile
- Automatisiertes Scraping oder Webdaten-Crawler können Ihnen helfen, Hunderte von Datenpunkten aus Tausenden von Webseiten in wenigen Sekunden zu extrahieren.
- Die Werkzeuge sind einfach zu bedienen. Selbst ein unerfahrener Programmierer oder Amateur-Programmierer kann benutzerfreundliche UIs verwenden, um Daten aus dem Internet zu kratzen.
- Einige der Tools können so eingestellt werden, dass sie nach einem Zeitplan ausgeführt werden und die extrahierten Daten dann in einer Google-Tabelle oder einer JSON-Datei liefern.
- Die meisten Sprachen wie Python verfügen über dedizierte Bibliotheken wie BeautifulSoup, die dabei helfen können, Daten einfach aus dem Internet zu kratzen.
Nachteile
- Die Tools erfordern Schulungen und die DIY-Lösungen erfordern Erfahrung. Sie müssen also entweder etwas Energie Ihres Geschäftsteams für das Web-Scraping aufwenden oder ein Tech-Team beauftragen, sich um die Web-Scraping-Bemühungen zu kümmern.
- Die meisten Tools haben einige Einschränkungen, eines kann Ihnen möglicherweise nicht dabei helfen, Daten zu kratzen, die sich hinter einem Anmeldebildschirm befinden, während andere möglicherweise Probleme mit eingebetteten Inhalten haben.
- Für kostenpflichtige No-Code-Tools können Upgrades angefordert werden, aber Patches können langsam sein und sich bei der Arbeit mit engen Fristen als nicht hilfreich erweisen.
Daten als Service (oder DaaS)
Wie der Name schon sagt, bedeutet dies, dass Sie Ihren gesamten Datenextraktionsprozess auslagern. Ihre Infrastruktur, Ihr Code, Wartung, alles ist erledigt. Sie stellen die Anforderungen und Sie erhalten die Ergebnisse.
Der Prozess des Web Scraping ist kompliziert und erfordert erfahrene Programmierer. Die Infrastruktur zusammen mit der Arbeitskraft, die erforderlich ist, um ein internes Crawling-Setup aufrechtzuerhalten, kann zu belastend werden, insbesondere für Unternehmen, die noch kein internes Technologieteam haben. In solchen Fällen ist es besser, auf einen externen Web-Scraping-Dienst zurückzugreifen.
Es gibt viele Vorteile bei der Verwendung eines DaaS, von denen einige sind:
Konzentration auf das Kerngeschäft
Anstatt Zeit und Mühe auf die technischen Aspekte des Web Scraping und den Aufbau eines ganzen Teams zu verwenden, das sich darum dreht, ermöglicht die Auslagerung der Arbeit, dass der Fokus auf dem Kerngeschäft bleibt.
Kostengünstig im Vergleich zu DIY Web Data Crawler
Eine interne Web-Scraping-Lösung kostet mehr als die Anschaffung eines DaaS-Dienstes. Web Scraping ist keine leichte Aufgabe und die Komplexität bedeutet, dass Sie qualifizierte Entwickler finden müssen, was Sie auf lange Sicht kosten wird. Da Ihnen die meisten DaaS-Lösungen nur nach Nutzung berechnet werden, zahlen Sie nur für die extrahierten Datenpunkte und die Gesamtdatengröße.
Keine Wartung
Wenn Sie eine interne Lösung erstellen oder Web-Scraping-Tools verwenden, entsteht ein zusätzlicher Overhead, wenn ein Bot aufgrund von Änderungen an den Websites oder anderen technischen Problemen, die möglicherweise sofort behoben werden müssen, ausfällt. Dies könnte bedeuten, dass jemand oder ein Team immer nach Ungenauigkeiten in den gekratzten Daten Ausschau halten und die Gesamtausfallzeit des Systems im Auge behalten müsste. Da sich Websites häufig ändern können, muss der Code jedes Mal aktualisiert werden, da sonst die Gefahr eines Zusammenbruchs besteht. Mit DaaS-Anbietern müssen Sie sich nie um den zusätzlichen Aufwand kümmern, eine interne Web-Scraping-Lösung zu warten.
Wenn es um Web Scraping oder Web Data Crawler geht, können Sie aus den oben beschriebenen Methoden entsprechend Ihren spezifischen Anforderungen auswählen. Wenn Sie jedoch eine DaaS-Lösung der Enterprise-Klasse benötigen, bieten wir bei PromptCloud einen vollständig verwalteten DaaS-Service an, der Ihnen bereinigte und formatierte Datenpunkte basierend auf Ihren Präferenzen bereitstellen kann. Sie müssen Ihre Anforderungen spezifizieren und wir liefern Ihnen die Daten, die Sie dann Plug-and-Play verwenden können. Mit einer DaaS-Lösung können Sie die Unannehmlichkeiten von Wartung, Infrastruktur, Zeit und Kosten vergessen oder beim Scrapen von einer Website blockiert werden. Wir sind ein Cloud-basierter Pay-per-Use-Service, der Ihren Anforderungen gerecht wird und Ihre Scraping-Anforderungen erfüllt.