
Мой веб-сканер данных неисправен — как мне это исправить?
Опубликовано: 2021-07-30В эпоху растущей цифровизации данные являются новой валютой. Это один из многих факторов, которые будут определять, сможете ли вы идти в ногу со своими конкурентами. Чем больше у человека данных, тем выгоднее это будет для него. И один из способов получения данных — через веб-сканер данных.
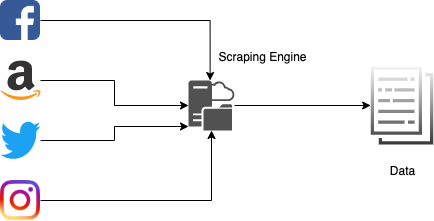
Рис. Веб-скрейпинг нескольких веб-сайтов и агрегирование данных
Веб-сканер данных для бизнеса
Веб-скрапинг относится к процессу, при котором данные извлекаются с веб-сайтов . Боты, используемые для извлечения данных, называются сканерами данных или поисковыми роботами. Это не попиксельное извлечение, а скорее извлечение лежащего в основе HTML-кода и содержащихся в нем данных. Множество компаний полагаются на парсинг данных в Интернете — от компаний, занимающихся исследованиями рынка, которые используют данные социальных сетей для анализа настроений, до сайтов, которые автоматически выбирают цены для веб-сайтов продавцов.
Методы парсинга веб-страниц или поисковых роботов веб-данных
Ручной парсинг
Ручной парсинг — это копирование/вставка соответствующей информации и создание электронной таблицы для отслеживания данных. Как бы просто ни звучало ручное соскребание, оно имеет свои плюсы и минусы:
Плюсы
- Один из самых простых методов парсинга веб-страниц, он не требует каких-либо предварительных знаний или навыков для использования поискового робота веб-данных.
- Существует мало права на ошибку, поскольку это позволяет проводить проверки человеком в процессе извлечения.
- Одна из проблем, связанных с процессом очистки веб-страниц, заключается в том, что быстрое извлечение часто приводит к тому, что веб-сайт блокирует доступ. Поскольку ручной парсинг — медленный процесс, вопрос блокировки не возникает.
Минусы
- Низкая скорость также мешает тайм-менеджменту. Боты справляются со скрейпингом значительно быстрее, чем люди.
Автоматический парсинг
Автоматический веб-скрейпинг или поисковый робот веб-данных можно выполнить, написав свой код и создав собственный механизм веб-скрейпинга своими руками, или используя инструменты на основе подписки, которыми может управлять ваша бизнес-команда после недельного обучения. Множество инструментов без кода стали популярными со временем, поскольку они просты в использовании и экономят время и деньги.
Что касается тех, кто хочет создать свои сканеры веб-данных или парсеры, вы можете собрать себе команду, которая будет кодировать этапы, которые необходимо выполнить для сбора данных с нескольких веб-страниц, а затем автоматизировать весь процесс, развернув сканеры, имеющие эту информацию в облако. Процессы, связанные с автоматическим извлечением данных, обычно включают один или несколько из следующих элементов:
Анализ HTML : анализ HTML использует JavaScript и используется для линейных или вложенных HTML-страниц. Обычно он используется для извлечения ссылок, захвата экрана, извлечения текста, извлечения ресурсов и многого другого.
Анализ DOM: объектная модель документа или DOM используется для понимания стиля, структуры и содержимого в файлах XML. Парсеры DOM используются, когда парсер хочет получить углубленное представление о структуре веб-страницы. Парсер DOM можно использовать для поиска узлов, несущих информацию, а затем с помощью таких инструментов, как XPath, можно очистить веб-страницы. Веб-браузеры, такие как Internet Explorer или Mozilla Firefox, можно использовать вместе с некоторыми подключаемыми модулями для извлечения соответствующих данных с веб-страниц, даже если генерируемое содержимое является динамическим.
Вертикальная агрегация. Платформы вертикальной агрегации создаются компаниями, имеющими доступ к крупномасштабным вычислительным мощностям для работы с определенными вертикалями. Иногда компании также используют облако для запуска этих платформ. Боты создаются и контролируются платформами без необходимости вмешательства человека на основе базы знаний по вертикали. По этой причине эффективность создаваемых ботов зависит от качества извлекаемых ими данных.

XPath: XML Path Language, или XPath, — это язык запросов, который используется в XML-документах. Поскольку XML-документы имеют древовидную структуру, XPath используется для навигации путем выбора узлов на основе множества параметров. XPath вместе с анализом DOM можно использовать для извлечения целых веб-страниц.
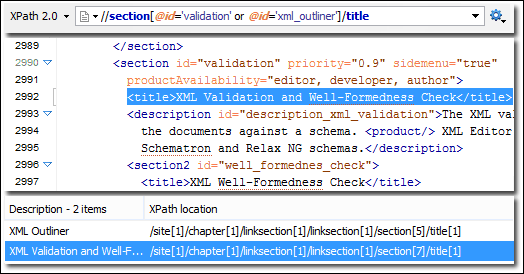
Рис. Извлечение данных с помощью Xpath. Источник: Поддержка XPath (oxygenxml.com)
Google Sheets: Google Sheets — популярный выбор для парсеров. В Таблицах функцию IMPORTXML (,) можно использовать для извлечения данных с веб-сайтов. Это особенно полезно, когда парсер хочет извлечь определенные данные или шаблоны с веб-сайта. Команду также можно использовать для проверки защищенности вашего веб-сайта от царапин.
Сопоставление текстового шаблона: это распространенный метод сопоставления выражений, который использует команду UNIX grep и обычно включается в такие языки программирования, как Perl или Python.
Такие инструменты и услуги веб-скрейпинга широко доступны в Интернете, и сами парсеры не должны обладать высокой квалификацией в вышеуказанных методах, если они не хотят выполнять парсинг самостоятельно. Такие инструменты, как CURL, Wget, HTTrack, Import.io, Node.js и другие, высоко автоматизированы. Парсер также может использовать автоматизированные безголовые браузеры, такие как Phantom.js, Slimmer.js, Casper.js.
Плюсы
- Автоматический парсинг или сканер веб-данных могут помочь вам извлечь сотни точек данных с тысяч веб-страниц за несколько секунд.
- Инструменты просты в использовании. Даже неквалифицированный программист или программист-любитель может использовать удобный пользовательский интерфейс для извлечения данных из Интернета.
- Некоторые инструменты можно настроить на запуск по расписанию, а затем доставлять извлеченные данные в таблицу Google или файл JSON.
- Большинство языков, таких как Python, поставляются со специальными библиотеками, такими как BeautifulSoup, которые помогают легко собирать данные из Интернета.
Минусы
- Инструменты требуют обучения, а решения «сделай сам» требуют опыта, поэтому вам нужно либо посвятить немного энергии своей бизнес-команде парсингу веб-страниц, либо нанять техническую команду для обработки парсинга веб-страниц.
- Большинство инструментов имеют некоторые ограничения: один из них может не помочь вам очистить данные, которые находятся за экраном входа в систему, в то время как у других могут возникнуть проблемы со встроенным содержимым.
- Для платных инструментов без кода могут быть запрошены обновления, но исправления могут быть медленными и могут оказаться бесполезными при работе в сжатые сроки.
Данные как услуга (или DaaS)
Как следует из названия, это означает аутсорсинг всего процесса извлечения данных. Ваша инфраструктура, ваш код, обслуживание — обо всем позаботятся. Вы предъявляете требования и получаете результаты.
Процесс парсинга веб-страниц сложен и требует наличия опытных программистов. Инфраструктура вместе с рабочей силой, необходимой для поддержания внутренней настройки сканирования, может стать слишком обременительной, особенно для компаний, у которых еще нет собственной технической команды. В таких случаях лучше воспользоваться внешним сервисом веб-скрейпинга.
Использование DaaS имеет много преимуществ, некоторые из которых:
Сосредоточьтесь на основном бизнесе
Вместо того, чтобы тратить время и усилия на технические аспекты парсинга веб-страниц и создание целой команды, которая будет вращаться вокруг этого, аутсорсинг работы позволяет сосредоточиться на основном бизнесе.
Экономически эффективен по сравнению с самодельным веб-краулером данных
Внутреннее решение для парсинга веб-страниц будет стоить больше, чем услуга DaaS. Веб-скрапинг — непростая работа, и сложности означают, что вам придется нанимать квалифицированных разработчиков, что в конечном итоге будет стоить вам денег. Поскольку большинство решений DaaS взимают плату только за использование, вы будете платить только за извлекаемые точки данных и общий объем данных.
Нет обслуживания
Когда вы создаете собственное решение или используете инструменты веб-скрейпинга, возникают дополнительные накладные расходы, связанные с поломкой бота из-за изменений на веб-сайтах или других технических проблем, которые, возможно, потребуется немедленно исправить. Это может означать, что кому-то или команде всегда нужно следить за неточностями в очищенных данных и следить за общим временем простоя системы. Поскольку веб-сайты могут часто меняться, код необходимо будет обновлять каждый раз, иначе возникнет риск поломки. С провайдерами DaaS вам никогда не придется сталкиваться с дополнительными трудностями, связанными с поддержкой собственного решения для парсинга веб-страниц.
Когда дело доходит до парсинга веб-страниц или поискового робота веб-данных, вы можете выбирать из описанных выше методов в соответствии с вашими конкретными потребностями. Однако, если вам требуется решение DaaS корпоративного уровня, мы в PromptCloud предлагаем полностью управляемую услугу DaaS, которая может предоставить вам очищенные и отформатированные точки данных в соответствии с вашими предпочтениями. Вам нужно указать свои требования, и мы предоставим вам данные, которые вы затем сможете подключить и использовать. С решением DaaS вы можете забыть о неудобствах, связанных с обслуживанием, инфраструктурой, временем и затратами, а также о блокировке при очистке сайта. Мы представляем собой облачный сервис с оплатой по факту использования, который будет удовлетворять ваши потребности и выполнять ваши требования к парсингу.