
Meu rastreador de dados da Web está quebrado - como faço para corrigi-lo?
Publicados: 2021-07-30Em uma era de digitalização crescente, os dados são a nova moeda. É um dos muitos fatores que decidirão se você pode acompanhar seus concorrentes. Quanto mais dados alguém tiver, mais vantajoso será para ele. E uma maneira de obter os dados é através do rastreador de dados da web.
Fig: Web Scraping de vários sites e agregação de dados
Rastreador de dados da Web para empresas
Web scraping refere-se a um processo em que os dados são extraídos de sites . Os bots usados para extrair os dados são chamados de rastreadores de dados ou aranhas. Não é uma extração pixel a pixel, mas sim a extração do código HTML subjacente e dos dados contidos nele. Muitas empresas dependem de web scraping para obter dados - desde empresas de pesquisa de mercado que usam dados de mídia social para análise de sentimentos até sites que buscam automaticamente preços para sites de vendedores.
Técnicas de Web Scraping ou Web Data Crawler
Raspagem Manual
A raspagem manual é copiar/colar informações relevantes e criar uma planilha para acompanhar os dados. Tão simples quanto sons de raspagem manual, ele vem com seus prós e contras:
Prós
- Um dos métodos mais fáceis de raspagem da web, não requer nenhum conhecimento ou habilidade prévia para usar o rastreador de dados da web.
- Há pouca margem para erro, pois permite verificações humanas durante o processo de extração.
- Um dos problemas que cercam o processo de raspagem da web é que a extração rápida geralmente faz com que o site bloqueie o acesso. Como a raspagem manual é um processo lento, a questão de ficar bloqueado não surge.
Contras
- A velocidade lenta também é um incômodo para o gerenciamento do tempo. Os bots são significativamente mais rápidos na raspagem do que os humanos.
Raspagem Automatizada
O web scraping automatizado ou o web data crawler pode ser feito escrevendo seu código e criando seu próprio mecanismo de web scraping DIY, ou usando ferramentas baseadas em assinatura que podem ser operadas por sua equipe de negócios com uma semana de treinamento. Várias ferramentas sem código tornaram-se populares com o tempo, pois são fáceis de usar e economizam tempo e dinheiro.
Para aqueles que desejam criar seus rastreadores ou raspadores de dados da Web, você pode obter uma equipe que codificaria as etapas que precisam ser executadas para coletar dados de várias páginas da Web e automatizar todo o processo implantando rastreadores com essas informações em a nuvem. Os processos envolvidos com a raspagem automatizada geralmente incluem um ou mais dos seguintes:
Análise HTML: A análise HTML usa JavaScript e é usada para páginas HTML lineares ou aninhadas. Geralmente é usado para extração de links, captura de tela, extração de texto, extração de recursos e muito mais.
DOM Parsing: O Document Object Model, ou DOM, é usado para entender o estilo, a estrutura e o conteúdo dos arquivos XML. Os analisadores DOM são usados quando o raspador deseja obter uma visão detalhada da estrutura de uma página da web. Um analisador DOM pode ser usado para localizar os nós que carregam informações e, em seguida, com o uso de ferramentas como páginas da Web XPath, podem ser raspadas. Navegadores da Web, como Internet Explorer ou Mozilla Firefox, podem ser usados junto com determinados plugins para extrair dados relevantes de páginas da Web, mesmo quando o conteúdo gerado é dinâmico.
Agregação vertical: As plataformas de agregação vertical são criadas por empresas que têm acesso ao poder de computação em larga escala para atingir verticais específicas. Às vezes, as empresas também usam a nuvem para executar essas plataformas. Os bots são criados e monitorados pelas plataformas sem a necessidade de qualquer intervenção humana com base na base de conhecimento da vertical. Por esse motivo, a eficiência dos bots criados depende da qualidade dos dados que eles extraem.
XPath: XML Path Language, ou XPath, é uma linguagem de consulta usada em documentos XML. Como os documentos XML têm uma estrutura semelhante a uma árvore, o XPath é usado para navegar selecionando nós com base em vários parâmetros. O XPath junto com a análise do DOM pode ser usado para extrair páginas da Web inteiras.

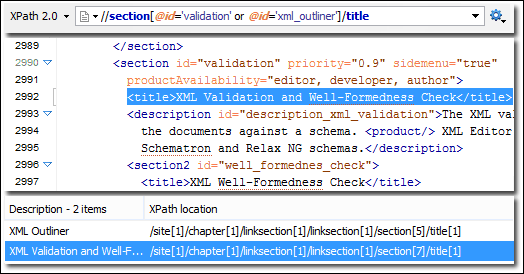
Fig: Extraindo dados usando Xpath. Fonte: Suporte XPath (oxygenxml.com)
Planilhas Google: o Planilhas Google é uma escolha popular para raspadores. Com o Planilhas, a função IMPORTXML (,) pode ser usada para extrair dados de sites. É particularmente útil quando o raspador deseja extrair dados ou padrões específicos de um site. O comando também pode ser usado para verificar se o seu site é à prova de raspagem.
Correspondência de padrão de texto: essa é uma técnica comum de correspondência de expressão que faz uso do comando grep do UNIX e geralmente é incorporada a linguagens de programação como Perl ou Python.
Essas ferramentas e serviços de raspagem da web estão amplamente disponíveis on-line, e os próprios raspadores não precisam ser altamente qualificados nas técnicas acima se não quiserem fazer a raspagem eles mesmos. Ferramentas como CURL, Wget, HTTrack, Import.io, Node.js e outras são altamente automatizadas. Os navegadores headless automatizados, como Phantom.js, Slimmer.js, Casper.js, também podem ser usados pelo web scraper.
Prós
- A raspagem automatizada ou o rastreador de dados da Web podem ajudá-lo a extrair centenas de pontos de dados de milhares de páginas da Web em poucos segundos.
- As ferramentas são fáceis de usar. Mesmo um programador não qualificado ou amador pode usar interfaces de usuário amigáveis para extrair dados da Internet.
- Algumas das ferramentas podem ser configuradas para serem executadas em um cronograma e, em seguida, entregar os dados extraídos em uma planilha do Google ou em um arquivo JSON.
- A maioria das linguagens como Python vem com bibliotecas dedicadas como BeautifulSoup que podem ajudar a extrair dados da web facilmente.
Contras
- As ferramentas exigem treinamento e as soluções de bricolage exigem experiência - portanto, você precisa dedicar parte da energia de sua equipe de negócios à raspagem da web ou obter uma equipe de tecnologia para lidar com os esforços de raspagem da web.
- A maioria das ferramentas vem com algumas limitações, uma pode não ser capaz de ajudá-lo a extrair dados que estão atrás de uma tela de login, enquanto outras podem ter problemas com conteúdo incorporado.
- Para ferramentas pagas sem código, as atualizações podem ser solicitadas, mas os patches podem ser lentos e podem não ser úteis ao trabalhar com prazos difíceis.
Dados como um serviço (ou DaaS)
Como o nome sugere, isso se traduz em terceirizar seu processo completo de extração de dados. Sua infra, seu código, manutenção, tudo é cuidado. Você fornece os requisitos e obtém os resultados.
O processo de raspagem da web é complicado e requer codificadores qualificados. A infraestrutura, juntamente com a mão de obra necessária para sustentar uma configuração interna de rastreamento, pode se tornar muito onerosa, especialmente para empresas que ainda não possuem uma equipe de tecnologia interna. Nesses casos, é melhor usar um serviço externo de web-scraping.
Há muitos benefícios em usar um DaaS, alguns dos quais são:
Foco no Core Business
Em vez de gastar tempo e esforço nos aspectos técnicos do web scraping e na criação de uma equipe inteira para girá-lo, a terceirização do trabalho permite que o foco permaneça no negócio principal.
Econômico em comparação com o rastreador de dados da Web DIY
Uma solução interna de web scraping custará mais do que obter um serviço DaaS. A raspagem da Web não é uma tarefa fácil e as complexidades significam que você terá que obter desenvolvedores qualificados, o que custará a longo prazo. Como a maioria das soluções de DaaS cobrará apenas com base no uso, você pagará apenas pelos pontos de dados extraídos e pelo tamanho total dos dados.
Sem manutenção
Quando você cria uma solução interna ou usa ferramentas de web scraping, há uma sobrecarga adicional de falha de um bot devido a alterações nos sites ou outros problemas técnicos que podem precisar ser corrigidos imediatamente. Isso pode significar que alguém ou uma equipe sempre precisaria estar atento a imprecisões nos dados raspados e verificar o tempo de inatividade geral do sistema. Como os sites podem mudar com frequência, o código precisará ser atualizado sempre que isso acontecer ou haverá o risco de falha. Com os provedores de DaaS, você nunca terá que arcar com as dificuldades adicionais de manter uma solução interna de web scraping.
Quando se trata de raspagem da web ou rastreador de dados da web, você pode escolher entre os métodos discutidos acima de acordo com suas necessidades específicas. No entanto, se você precisar de uma solução DaaS de nível empresarial, nós, na PromptCloud, oferecemos um serviço DaaS totalmente gerenciado que pode fornecer pontos de dados raspados limpos e formatados com base em suas preferências. Você precisa especificar seus requisitos e forneceremos os dados que você pode conectar e usar. Com uma solução DaaS, você pode esquecer as inconveniências de manutenção, infraestrutura, tempo e custo, ou ficar bloqueado ao extrair de um site. Somos um serviço baseado em nuvem de pagamento por uso que atenderá às suas demandas e atenderá aos seus requisitos de raspagem.