
สุดยอดรายการคำถามที่พบบ่อยเกี่ยวกับการขูดเว็บที่ตอบแล้ว – PromptCloud
เผยแพร่แล้ว: 2019-09-03การขูดเว็บได้รับความนิยมอย่างมากในช่วง 10 ปีที่ผ่านมา และยังคงดึงดูดธุรกิจต่างๆ ให้ใช้ประโยชน์จากข้อมูลเว็บสำหรับกรณีธุรกิจต่างๆ บริษัทส่วนใหญ่ในด้านอีคอมเมิร์ซ การท่องเที่ยว งาน และการใช้พื้นที่การวิจัย ได้ตั้งค่าระบบการรวบรวมข้อมูลภายในองค์กร หรือมีส่วนร่วมกับผู้ให้บริการรวบรวมข้อมูลเว็บโดยเฉพาะ ที่นี่ เรามีคำถามที่พบบ่อยเกี่ยวกับ Web Scraping ที่จะช่วยให้คุณไขข้อสงสัยต่างๆ ได้
นี่คือการค้นหาเทรนด์ของ Google ที่แสดงความสนใจเพิ่มขึ้นในการขูดเว็บ:
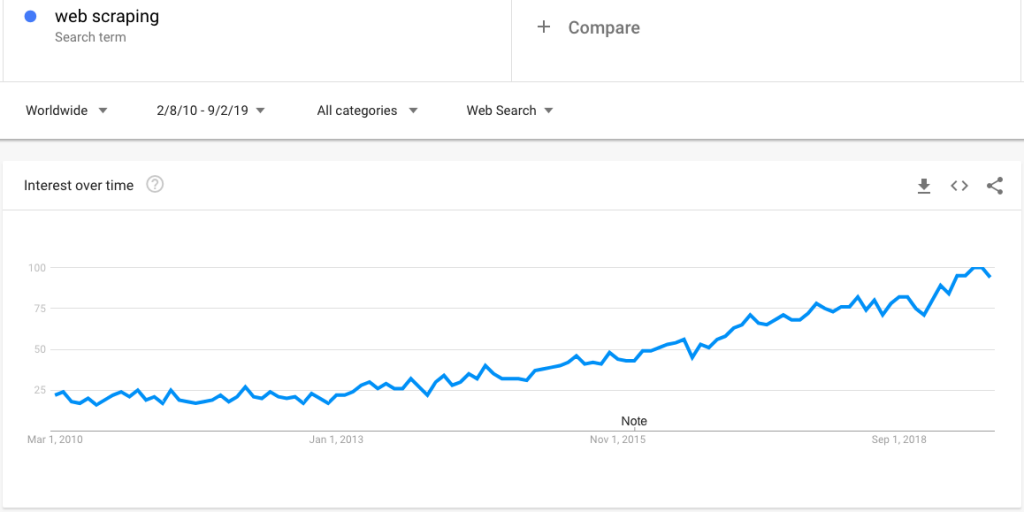
อย่างไรก็ตาม ด้วยความสนใจที่เพิ่มขึ้น มีคำถามมากมายเกี่ยวกับการขูดเว็บ ในโพสต์นี้ เราชี้แจงชุดคำถามมากมาย:
Q. การขูดเว็บคืออะไร?
A. Web Scraping (เรียกอีกอย่างว่าการแยกข้อมูลเว็บและการเก็บเกี่ยวเว็บ) เป็นเทคนิคในการทำให้กระบวนการรวบรวมข้อมูลจากเว็บไซต์เป็นไปอย่างอัตโนมัติผ่านโปรแกรมอัจฉริยะและบันทึกในรูปแบบที่มีโครงสร้างสำหรับการเข้าถึงตามต้องการ นอกจากนี้ยังสามารถตั้งโปรแกรมให้รวบรวมข้อมูลด้วยความถี่ที่แน่นอน เช่น รายวัน รายสัปดาห์ และรายเดือน หรือส่งข้อมูลแบบเกือบเรียลไทม์
ถาม การขูดเว็บใดดีที่สุด?
A. มีหลายวิธีในการดึงข้อมูลจากเว็บ — ตั้งแต่ผู้ให้บริการขูดเว็บโดยเฉพาะไปจนถึงผู้ให้บริการฟีดข้อมูลเฉพาะประเภท (เช่น JobsPikr สำหรับข้อมูลงาน) และเครื่องมือการขูด (สามารถกำหนดค่าให้ดำเนินการรวบรวมข้อมูลเว็บแบบง่ายและครั้งเดียว) .
การเลือกวิธีแก้ปัญหาและแนวทางขึ้นอยู่กับข้อกำหนดเฉพาะจริงๆ ตามกฎทั่วไป ให้พิจารณาบริการขูดเว็บที่มีให้เมื่อคุณต้องการรวบรวมข้อมูลเว็บจำนวนมาก (อ่านบันทึกนับล้านทุกสัปดาห์หรือวัน)
ถาม: การขูดเว็บมีไว้เพื่ออะไร?
A. มีหลายกรณีการใช้งานของการขูดเว็บ ต่อไปนี้คือรายการที่พบบ่อยที่สุด:
- เปรียบเทียบราคาสินค้า
- การทำเหมืองข้อมูลเชิงลึกและการจัดการชื่อเสียงผ่านการดึงข้อมูลการตรวจสอบ
- ความฉลาดทางการแข่งขัน
- การลงรายการสินค้า
- อัลกอริธึมการเรียนรู้ของเครื่องฝึก
- การวิจัยและวิเคราะห์อุตสาหกรรมบางประเภท
ถาม การขูดเว็บใน python คืออะไร
A. การขูดเว็บสามารถทำได้โดยใช้ภาษาโปรแกรมและภาษาสคริปต์ที่แตกต่างกัน อย่างไรก็ตาม Python เป็นตัวเลือกยอดนิยม และ Beautiful Soup เป็นแพ็คเกจ Python ที่ใช้บ่อยสำหรับการแยกวิเคราะห์เอกสาร HTML และ XML
เราได้เขียนบทช่วยสอนสองสามข้อเกี่ยวกับหัวข้อนี้ — คุณสามารถเรียนรู้เกี่ยวกับพวกเขาได้จากโพสต์ของเราในตัวอย่างการขูดเว็บ
ถาม การขูดและการรวบรวมข้อมูลเว็บคืออะไร
A. Web scraping ถือได้ว่าเป็น superset ของการรวบรวมข้อมูลเว็บ — โดยพื้นฐานแล้วการรวบรวมข้อมูลเว็บจะทำเพื่อสำรวจเส้นทางของหน้าเว็บ เพื่อให้ขั้นตอนต่างๆ ของการขูดเว็บสามารถนำไปใช้ในการดึงข้อมูลและดาวน์โหลดข้อมูลได้
ถาม เครื่องมือขูดเว็บคืออะไร
A. สิ่งเหล่านี้เป็นเครื่องมือ DIY เป็นหลักซึ่งตัวรวบรวมข้อมูลจำเป็นต้องเรียนรู้เครื่องมือและกำหนดค่าให้ดึงข้อมูล เครื่องมือเหล่านี้โดยทั่วไปดีสำหรับโครงการรวบรวมข้อมูลเว็บจากไซต์ทั่วไป โดยทั่วไปแล้วจะล้มเหลวในการดึงข้อมูลปริมาณมากหรือเมื่อไซต์เป้าหมายมีความซับซ้อนและเป็นไดนามิก

ถาม Reddit การขูดเว็บคืออะไร
ตอบ นี่เป็นเพียงกระบวนการดึงข้อมูลจาก Reddit ซึ่งเป็นแพลตฟอร์มโซเชียลยอดนิยมเพื่อสร้างชุมชนและฟอรัมประเภทต่างๆ ข้อมูลจาก Reddit สามารถคัดลอกมาเพื่อทำการวิจัยผู้บริโภค วิเคราะห์ความรู้สึก NLP และฝึกอบรมการเรียนรู้ของเครื่อง
ถาม บริการขูดเว็บคืออะไร?
A. บริการดึงข้อมูลเว็บเป็นเพียงกระบวนการในการเป็นเจ้าของไปป์ไลน์การรับข้อมูลอย่างสมบูรณ์ โดยทั่วไปลูกค้าจะจัดเตรียมข้อกำหนดในแง่ของไซต์เป้าหมาย ฟิลด์ข้อมูล รูปแบบไฟล์ และความถี่ของการแยกข้อมูล ผู้จำหน่ายข้อมูลส่งข้อมูลเว็บโดยอิงตามข้อกำหนดในขณะที่ดูแลการบำรุงรักษาฟีดข้อมูลและการประกันคุณภาพ
ถาม LinkedIn ขูดเว็บคืออะไร
A. แม้ว่าบริษัทจำนวนมากต้องการเข้าถึงข้อมูลจาก LinkedIn แต่ก็ไม่ได้รับอนุญาตตามกฎหมายตามไฟล์ robots.txt และข้อกำหนดการใช้งาน
ถาม เมื่อใดควรรวบรวมข้อมูลเว็บ
A. ในฐานะบริษัท คุณควรรวบรวมข้อมูลเว็บเมื่อคุณต้องการดำเนินการตามกรณีการใช้งานที่กล่าวถึงข้างต้น และต้องการเสริมข้อมูลภายในของคุณด้วยชุดข้อมูลทางเลือกที่ครอบคลุม
ถาม การขูดเว็บถูกกฎหมายหรือไม่
ตอบ: ถูกต้องตามกฎหมายตราบใดที่คุณปฏิบัติตามหลักเกณฑ์เกี่ยวกับคำสั่งที่กำหนดไว้ในไฟล์ robots.txt เงื่อนไขการใช้งาน การเข้าถึงเนื้อหาสาธารณะและส่วนตัว เรียนรู้เพิ่มเติมเกี่ยวกับความถูกต้องตามกฎหมาย
ถาม: การทำเหมืองข้อมูลทางเว็บเป็นการทำเหมืองข้อมูลหรือไม่?
ก. การทำเหมืองข้อมูลเป็นกระบวนการในการเปิดเผยข้อมูลเชิงลึกจากชุดข้อมูลขนาดใหญ่โดยใช้เทคนิคที่จุดตัดกันของการเรียนรู้ของเครื่อง สถิติ และระบบฐานข้อมูล ดังนั้นข้อมูลที่ดึงออกมาด้วยเทคนิคการขูดเว็บจะถูกประมวลผลผ่านการวิเคราะห์ต่างๆ และกระบวนการที่สมบูรณ์ของการเก็บข้อมูลเพื่อทำเหมืองข้อมูลเชิงลึกสามารถเรียกได้ว่าการทำเหมืองข้อมูล
ถาม BeautifulSoup การขูดเว็บคืออะไร
A. Beautiful Soup เป็นไลบรารี Python ที่ช่วยให้โปรแกรมเมอร์ทำงานได้อย่างรวดเร็วในโครงการขูดเว็บโดยการสร้าง parse tree จากเอกสาร HTML และ XML (รวมถึงเอกสารที่มีแท็กไม่ปิดหรือ tag soup และมาร์กอัปอื่นๆ ที่มีรูปแบบไม่ถูกต้อง) สำหรับหน้าเว็บ
เวอร์ชันปัจจุบันของ Beautiful Soup 4 เข้ากันได้กับทั้ง Python 2.7 และ Python 3
ถาม วิธีรวบรวมข้อมูลเว็บ – การคัดลอกเว็บเทียบกับ API
A. API หรือ Application Programming Interfaces เป็นตัวกลางที่ช่วยให้ซอฟต์แวร์หนึ่งสามารถสื่อสารกับอีกซอฟต์แวร์หนึ่งได้ เมื่อใช้ API เพื่อรวบรวมข้อมูล คุณจะถูกควบคุมโดยชุดของกฎอย่างเคร่งครัด และมีเพียงฟิลด์ข้อมูลบางฟิลด์ที่คุณจะได้รับเท่านั้น
แต่ในกรณีของการขูดเว็บ ไคลเอนต์จะไม่ถูกจำกัดด้วยอัตราการเข้าถึง ฟิลด์ข้อมูล (ทุกสิ่งที่มีอยู่บนเว็บสามารถดาวน์โหลดได้) ตัวเลือกการปรับแต่งและการบำรุงรักษา
ถาม การขูดเว็บใน R คืออะไร
A. เช่นเดียวกับ Python R (ภาษาที่ใช้สำหรับการวิเคราะห์ทางสถิติ) สามารถใช้เพื่อรวบรวมข้อมูลจากเว็บได้เช่นกัน โปรดทราบว่า rvest เป็นแพ็คเกจยอดนิยมในระบบนิเวศ R
อย่างไรก็ตาม มันไม่มีประสิทธิภาพเท่ากับ Python หรือ Ruby สำหรับการขูดเว็บ
ถาม ทำไมการขูดเว็บจึงมีความสำคัญ
A. การขูดเว็บมีความสำคัญ เนื่องจากช่วยให้ธุรกิจและผู้คนทั่วโลกสามารถเข้าถึงข้อมูลเว็บซึ่งเป็นที่เก็บข้อมูลที่ใหญ่ที่สุดและครอบคลุมจนถึงปัจจุบัน เราได้กล่าวถึงกรณีการใช้งานหลายกรณีในคำถามก่อนหน้านี้
ตรวจสอบหน้ากรณีศึกษาเพื่อเรียนรู้เพิ่มเติม
ถาม การขูดเว็บทำงานอย่างไร
ก. การขูดเว็บโดยทั่วไปมีขั้นตอนหลายขั้นตอน นี่คือขั้นตอนที่ PromptCloud ติดตามในระดับสูง:
- Seeding – เป็นกระบวนการที่คล้ายกับ Tree Traversal ซึ่งโปรแกรมรวบรวมข้อมูลต้องผ่าน Seed URL หรือ URL ฐานก่อน จากนั้นจึงค้นหา URL ถัดไปในข้อมูลที่ดึงมาจาก URL เริ่มต้นเป็นต้น
- การตั้งค่า ทิศทาง สำหรับโปรแกรมรวบรวมข้อมูล – เมื่อข้อมูลจาก URL เริ่มต้นได้รับการแยกและเก็บไว้ในหน่วยความจำชั่วคราว ไฮเปอร์ลิงก์ที่มีอยู่ในข้อมูลจะต้องถูกกำหนดให้กับตัวชี้ จากนั้นระบบควรเน้นที่การแยกข้อมูลจากสิ่งเหล่านั้น
- การจัดคิว – แยกและจัดเก็บหน้าทั้งหมดที่โปรแกรมรวบรวมข้อมูลแยกวิเคราะห์ ในขณะที่สำรวจในที่เก็บเดียวเป็นไฟล์ HTML
- Deduplication – การลบบันทึกหรือข้อมูลที่ซ้ำกัน
- การทำให้เป็น มาตรฐาน – การปรับข้อมูลให้เป็นมาตรฐานตามความต้องการของลูกค้า (ผลรวม ส่วนเบี่ยงเบนมาตรฐาน การจัดรูปแบบสกุลเงิน ฯลฯ)
- โครงสร้าง – ข้อมูลที่ไม่มีโครงสร้างจะถูกแปลงเป็นรูปแบบที่มีโครงสร้างที่ฐานข้อมูลสามารถใช้ได้
- การ รวม ข้อมูล – ลูกค้าสามารถใช้ REST API เพื่อดึงข้อมูลที่กำหนดเองที่จำเป็น PromptCloud ยังสามารถส่งข้อมูลไปยัง FTP, S3 หรือที่เก็บข้อมูลบนคลาวด์อื่น ๆ ที่ต้องการเพื่อให้รวมข้อมูลในกระบวนการของบริษัทได้ง่าย
Q. เว็บรวบรวมข้อมูล Facebook ได้ไหม??
A. มีความต้องการข้อมูลที่สร้างขึ้นบน Facebook เป็นจำนวนมาก สามารถใช้สำหรับอะไรก็ได้ตั้งแต่การตรวจสอบความเชื่อมั่นและการจัดการชื่อเสียงไปจนถึงการค้นพบแนวโน้มและการคาดการณ์ตลาดหุ้น อย่างไรก็ตาม การรวบรวมข้อมูลและดึงข้อมูลจาก Facebook ถูกห้ามผ่านไฟล์ robots.txt และข้อกำหนดในการให้บริการ
นี้สรุปชุดคำถามและคำตอบ โพสต์คำถามของคุณในความคิดเห็นหากคุณต้องการพูดคุยเพิ่มเติมหรือมีคำถามที่เราไม่ได้กล่าวถึงที่นี่