
La liste ultime des FAQ sur le Web Scraping a répondu - PromptCloud
Publié: 2019-09-03Le scraping Web a gagné en popularité au cours des 10 dernières années et continue d'attirer les entreprises pour exploiter les données Web pour diverses analyses de rentabilisation. La majorité des entreprises du commerce électronique, des voyages, de l'emploi et de la recherche ont soit mis en place un système d'exploration interne, soit fait appel à un fournisseur de services d'exploration Web dédié. Ici, nous fournissons une FAQ sur le Web Scraping qui vous aidera à dissiper les doutes.
Voici une recherche de tendance Google qui montre un intérêt croissant pour le web scraping :
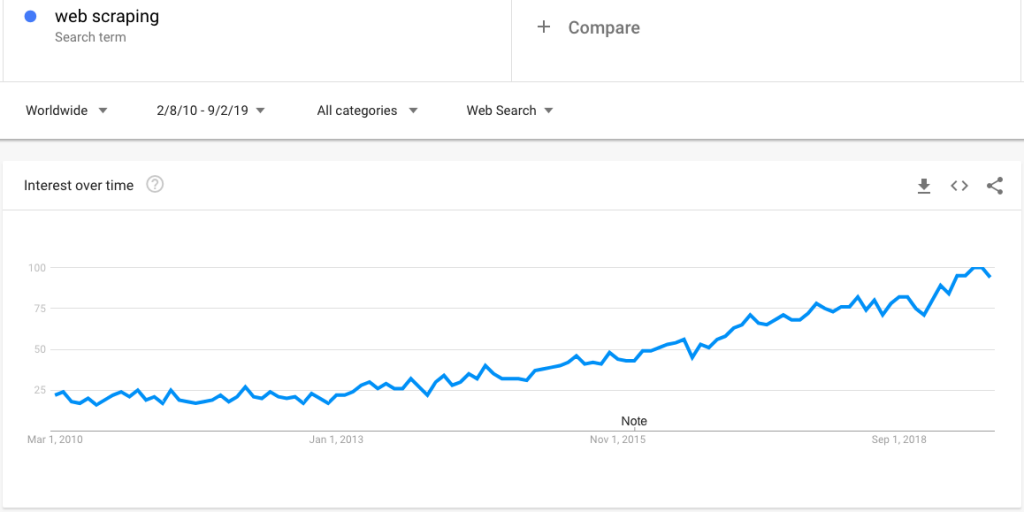
Cependant, avec un intérêt croissant, vient un grand nombre de questions autour du web scraping. Dans cet article, nous clarifions une vaste série de questions :
Q. Qu'est-ce que le scraping Web ?
R. Web Scraping (également connu sous le nom d'extraction de données Web et de moissonnage Web) est la technique qui consiste à automatiser le processus de collecte de données à partir de sites Web via un programme intelligent et à les enregistrer dans un format structuré pour un accès à la demande. Il peut également être programmé pour analyser les données à une certaine fréquence, par exemple quotidiennement, hebdomadairement et mensuellement, ou fournir des données en temps quasi réel.
Q. Quel web scraping est le meilleur ?
A. Il existe plusieurs façons d'extraire du Web - des fournisseurs de services de grattage Web dédiés aux fournisseurs de flux de données spécifiques à la verticale (par exemple, JobsPikr pour les données d'emploi) et aux outils de grattage (peuvent être configurés pour effectuer une collecte de données Web simple et ponctuelle) .
Le choix de la solution et de l'approche dépend vraiment des exigences spécifiques. En règle générale, envisagez un service de grattage Web lorsque vous avez besoin de collecter de grandes quantités de données Web (lit des millions d'enregistrements chaque semaine ou chaque jour).
Q. A quoi sert le web scraping ?
A. Il existe plusieurs cas d'utilisation du web scraping. Voici les plus courants :
- comparaison de produits et de prix
- exploration d'informations et gestion de la réputation via l'extraction de données d'examen
- veille concurrentielle
- catalogage des produits
- algorithme d'apprentissage automatique de formation
- recherche et analyse de certaines industries
Q. Qu'est-ce que le web scraping en python ?
R. Le scraping Web peut être effectué via différents langages de programmation et de script. Cependant, Python est un choix populaire et Beautiful Soup est un package Python fréquemment utilisé pour analyser les documents HTML et XML.
Nous avons écrit quelques tutoriels sur ce sujet - vous pouvez en apprendre davantage à partir de notre article sur les exemples de grattage Web.
Q. Qu'est-ce que le scraping et l'exploration Web ?
A. Le grattage Web peut être considéré comme un sur-ensemble de l'exploration Web - essentiellement l'exploration Web est effectuée pour parcourir les chemins des pages Web afin que différentes étapes de grattage Web puissent être appliquées pour extraire et télécharger des données.
Q. Que sont les outils de scraping Web ?
R. Il s'agit principalement d'outils de bricolage dans lesquels le collecteur de données doit apprendre l'outil et le configurer pour extraire des données. Ces outils conviennent généralement à des projets ponctuels de collecte de données Web à partir de sites simples. Ils échouent généralement lorsqu'il s'agit d'extraire de gros volumes de données ou lorsque les sites cibles sont complexes et dynamiques.
Q. Qu'est-ce que le web scraping Reddit ?
R. Il s'agit simplement du processus d'extraction de données de Reddit, une plate-forme sociale populaire permettant de créer différents types de communautés et de forums. Les données de Reddit peuvent être extraites pour effectuer des recherches sur les consommateurs, des analyses de sentiments, des NLP et des formations en apprentissage automatique.

Q. Qu'est-ce qu'un service de scraping Web ?
R. Le service de grattage Web est simplement le processus de prise en charge complète du pipeline d'acquisition de données. Les clients fournissent généralement les exigences en termes de sites cibles, de champs de données, de format de fichier et de fréquence d'extraction. Le fournisseur de données fournit les données Web exactement en fonction des besoins tout en s'occupant de la maintenance du flux de données et de l'assurance qualité.
Q. Qu'est-ce que le web scraping LinkedIn ?
R. Bien que de nombreuses entreprises souhaitent accéder aux données de LinkedIn, cela n'est pas autorisé par la loi en raison du fichier robots.txt et des conditions d'utilisation.
Q. Quand explorer le Web ?
R. En tant qu'entreprise, vous devez explorer le Web lorsque vous avez besoin d'effectuer l'un des cas d'utilisation mentionnés ci-dessus et que vous souhaitez augmenter vos données internes avec des ensembles de données alternatifs complets.
Q. Le web scraping est-il légal ?
R. C'est en effet légal tant que vous suivez les directives concernant les directives définies dans le fichier robots.txt, les conditions d'utilisation, l'accès au contenu public et privé. En savoir plus sur la légalité.
Q. Le web scraping est-il de l'exploration de données ?
R. L'exploration de données est le processus de découverte d'informations à partir d'ensembles de données à grande échelle en déployant des techniques à l'intersection de l'apprentissage automatique, des statistiques et des systèmes de base de données. Ainsi, les données extraites via la technique de grattage Web seront traitées via diverses analyses et le processus complet d'acquisition de données pour l'exploration d'informations peut être appelé exploration de données.
Q. Qu'est-ce que le web scraping BeautifulSoup ?
A. Beautiful Soup est une bibliothèque Python qui permet aux programmeurs de travailler rapidement sur des projets de grattage Web en créant un arbre d'analyse à partir de documents HTML et XML (y compris des documents avec des balises non fermées ou une soupe de balises et d'autres balisages malformés) pour les pages Web.
La version actuelle de Beautiful Soup 4 est compatible avec Python 2.7 et Python 3.
Q. Comment collecter des données Web - Web scraping vs. API ?
A. Les API ou interfaces de programmation d'applications sont un intermédiaire qui permet à un logiciel de communiquer avec un autre. Lorsque vous utilisez une API pour collecter des données, vous serez strictement régi par un ensemble de règles, et vous ne pouvez obtenir que certains champs de données spécifiques.
Mais, dans le cas du web scraping, les clients ne sont pas limités par le taux d'accès, les champs de données (tout ce qui est présent sur le web, peut être téléchargé), les options de personnalisation et la maintenance.
Q. Qu'est-ce que le web scraping dans R ?
R. Semblable à Python , R (un langage utilisé pour l'analyse statistique) peut également être utilisé pour collecter des données sur le Web. Notez que rvest est un package populaire dans l'écosystème R
Cependant, il n'est pas aussi puissant que Python ou Ruby pour le scraping Web.
Q. Pourquoi le scraping Web est-il important ?
R. Le scraping Web est important car il permet aux entreprises et aux personnes du monde entier d'accéder aux données Web, qui constituent le référentiel de données le plus vaste et le plus complet à ce jour. Nous avons mentionné plusieurs cas d'utilisation dans une question précédente.
Consultez la page des études de cas pour en savoir plus.
Q. Comment fonctionne le web scraping ?
A. Web scraping, en général, fonctionne en plusieurs étapes. Voici les étapes suivies par PromptCloud à un niveau élevé :
- Seeding - Il s'agit d'une procédure semblable à une traversée d'arbre, où le robot d'exploration passe d'abord par l'URL de départ ou l'URL de base, puis recherche l'URL suivante dans les données extraites de l'URL de départ, etc.
- Définition de la direction du robot d'exploration - Une fois que les données de l'URL de départ ont été extraites et stockées dans la mémoire temporaire, les hyperliens présents dans les données doivent être donnés au pointeur, puis le système doit se concentrer sur l'extraction des données à partir de ceux-ci.
- Mise en file d'attente - Extraction et stockage de toutes les pages analysées par le robot d'exploration, tout en les parcourant dans un référentiel unique sous forme de fichiers HTML.
- Déduplication – Suppression des enregistrements ou des données en double.
- Normalisation - Normalisation des données en fonction des exigences du client (somme, écart type, formatage des devises, etc.)
- Structuration – Les données non structurées sont converties dans un format structuré pouvant être consommé par la base de données.
- Intégration des données – L'API REST peut être utilisée par les clients pour récupérer les données personnalisées requises. PromptCloud peut également pousser les données vers le FTP, S3 ou tout autre stockage cloud souhaité pour une intégration facile des données dans le processus de l'entreprise.
Q. Pouvez-vous parcourir Facebook ? ?
R. Il existe une énorme demande de données générées sur Facebook. Il peut être utilisé pour tout, de la surveillance des sentiments et de la gestion de la réputation à la découverte des tendances et aux prévisions boursières. Cependant, l'exploration et l'extraction de données de Facebook ont été interdites via le fichier robots.txt et les conditions d'utilisation.
Ceci conclut la série de questions et réponses. Postez vos questions dans les commentaires si vous souhaitez en discuter davantage ou si vous avez des questions que nous n'avons pas abordées ici.