
Respuesta a la lista definitiva de preguntas frecuentes sobre Web Scraping – PromptCloud
Publicado: 2019-09-03El web scraping ha ganado una gran popularidad en el transcurso de los últimos 10 años y aún continúa atrayendo a las empresas para aprovechar los datos web para varios casos comerciales. La mayoría de las empresas en el comercio electrónico, los viajes, el trabajo y el espacio de investigación han establecido un sistema de rastreo interno o se han comprometido con un proveedor de servicios de rastreo web dedicado. Aquí te proporcionamos unas preguntas frecuentes sobre Web Scraping que te ayudarán a despejar las dudas.
Aquí hay una búsqueda de tendencias de Google que muestra un interés creciente en el web scraping:
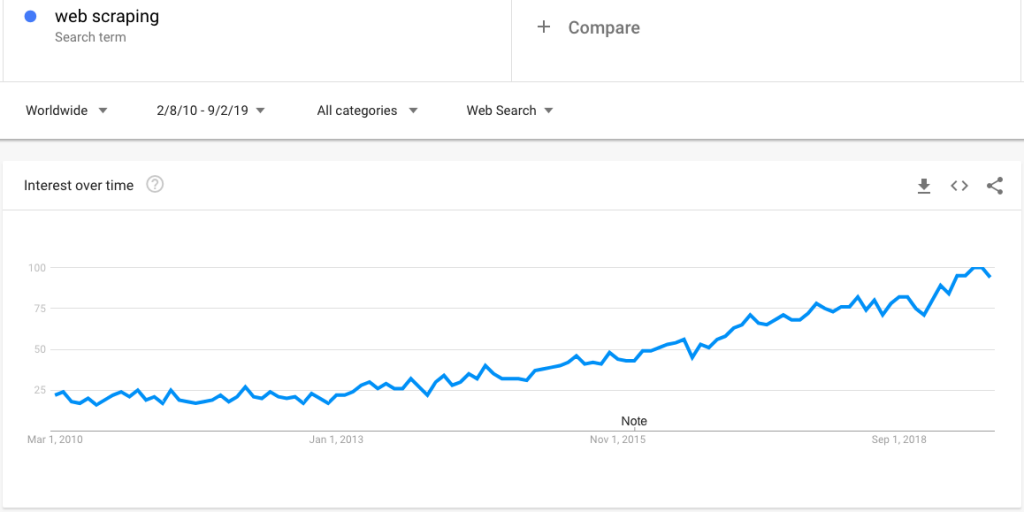
Sin embargo, con un interés creciente, surge una gran cantidad de preguntas sobre el web scraping. En esta publicación, aclaramos un amplio conjunto de preguntas:
P. ¿Qué es el web scraping?
R. Web Scraping (también conocido como extracción de datos web y recolección web) es la técnica de automatizar el proceso de recopilación de datos de sitios web a través de un programa inteligente y guardarlos en un formato estructurado para acceso bajo demanda. También se puede programar para rastrear datos a cierta frecuencia, como diariamente, semanalmente y mensualmente, o entregar datos casi en tiempo real.
P. ¿Qué raspado web es el mejor?
R. Hay varias formas de extraer de la web: desde proveedores de servicios de web scraping dedicados hasta proveedores de alimentación de datos específicos de verticales (por ejemplo, JobsPikr para datos de trabajos) y herramientas de scraping (se pueden configurar para realizar una recopilación de datos web simple y única) .
La elección de la solución y el enfoque realmente depende de los requisitos específicos. Como regla general, considere un servicio de raspado web cuando necesite recopilar grandes cantidades de datos web (lee millones de registros cada semana o día).
P. ¿Para qué se utiliza el web scraping?
R. Hay varios casos de uso de web scraping. Aquí están los más comunes:
- comparacion de productos y precios
- Minería de conocimientos y gestión de la reputación a través de la extracción de datos de revisión.
- inteligencia competitiva
- catalogación de productos
- algoritmo de aprendizaje automático de entrenamiento
- investigación y análisis de ciertas industrias
P. ¿Qué es el web scraping en python?
R. El web scraping se puede realizar a través de diferentes lenguajes de programación y secuencias de comandos. Sin embargo, Python es una opción popular y Beautiful Soup es un paquete de Python de uso frecuente para analizar documentos HTML y XML.
Hemos escrito un par de tutoriales sobre este tema; puede aprender sobre ellos en nuestra publicación sobre ejemplos de web scraping.
P. ¿Qué es raspado y rastreo web?
R. El web scraping se puede considerar como un superconjunto del rastreo web: esencialmente, el rastreo web se realiza para recorrer las rutas de las páginas web, de modo que se puedan aplicar diferentes pasos de web scraping para extraer y descargar datos.
P. ¿Qué son las herramientas de web scraping?
R. Estas son principalmente herramientas de bricolaje en las que el recopilador de datos necesita aprender la herramienta y configurarla para extraer datos. Estas herramientas son generalmente buenas para proyectos únicos de recopilación de datos web desde sitios simples. Por lo general, fallan cuando se trata de la extracción de datos de gran volumen o cuando los sitios de destino son complejos y dinámicos.
P. ¿Qué es el raspado web de Reddit?
R. Este es simplemente el proceso de extracción de datos de Reddit, que es una plataforma social popular para construir diferentes tipos de comunidades y foros. Los datos de Reddit se pueden extraer para realizar investigaciones de consumidores, análisis de sentimientos, NLP y capacitación de aprendizaje automático.

P. ¿Qué son los servicios de web scraping?
R. El servicio de web scraping es simplemente el proceso de tomar la propiedad completa de la canalización de adquisición de datos. Los clientes generalmente proporcionan el requisito en términos de sitios de destino, campos de datos, formato de archivo y frecuencia de extracción. El proveedor de datos entrega los datos web exactamente en función de los requisitos mientras se encarga del mantenimiento de la alimentación de datos y la garantía de calidad.
P. ¿Qué es el web scraping de LinkedIn?
R. Aunque a muchas empresas les gustaría acceder a los datos de LinkedIn, no está legalmente permitido según el archivo robots.txt y los términos de uso.
P. ¿Cuándo rastrear la web?
R. Como empresa, debe rastrear la web cuando necesite realizar cualquiera de los casos de uso mencionados anteriormente y desee aumentar sus datos internos con conjuntos de datos alternativos integrales.
P. ¿Es legal el web scraping?
R. De hecho, es legal siempre que siga las pautas que rodean las directivas establecidas en el archivo robots.txt, los términos de uso, el acceso a contenido público y privado. Obtenga más información sobre la legalidad.
P. ¿El web scraping es minería de datos?
R. La minería de datos es el proceso de descubrir información de conjuntos de datos a gran escala mediante la implementación de técnicas en la intersección del aprendizaje automático, las estadísticas y los sistemas de bases de datos. Por lo tanto, los datos extraídos a través de la técnica de raspado web se procesarán a través de varios análisis y el proceso completo de adquisición de datos para la minería de información se puede llamar minería de datos.
P. ¿Qué es el web scraping BeautifulSoup?
R. Beautiful Soup es una biblioteca de Python que permite a los programadores trabajar rápidamente en proyectos de web scraping mediante la creación de un árbol de análisis a partir de documentos HTML y XML (incluidos documentos con etiquetas no cerradas o sopa de etiquetas y otras marcas mal formadas) para las páginas web.
La versión actual de Beautiful Soup 4 es compatible con Python 2.7 y Python 3.
P. ¿Cómo recopilar datos web: web scraping vs. API?
R. Las API o interfaces de programación de aplicaciones son un intermediario que permite que un software se comunique con otro. Cuando utilice una API para recopilar datos, se regirá estrictamente por un conjunto de reglas y solo podrá obtener algunos campos de datos específicos.
Pero, en el caso del web scraping, los clientes no están restringidos por la tasa de acceso, los campos de datos (cualquier cosa que esté presente en la web, se puede descargar), las opciones de personalización y el mantenimiento.
P. ¿Qué es el web scraping en R?
R. Al igual que Python , R (un lenguaje utilizado para el análisis estadístico) también se puede utilizar para recopilar datos de la web. Tenga en cuenta que rvest es un paquete popular en el ecosistema R
Sin embargo, no es tan potente como Python o Ruby para el web scraping.
P. ¿Por qué es importante el web scraping?
R. El web scraping es importante ya que permite a las empresas y personas de todo el mundo acceder a los datos web, que es el repositorio de datos más grande y completo hasta la fecha. Hemos mencionado varios casos de uso en una pregunta anterior.
Consulte la página de casos prácticos para obtener más información.
P. ¿Cómo funciona el web scraping?
R. Web scraping, en general, opera con varios pasos. Estos son los pasos que PromptCloud sigue en un alto nivel:
- Siembra : es un procedimiento similar a un árbol transversal, donde el rastreador primero pasa por la URL inicial o la URL base y luego busca la siguiente URL en los datos que se obtienen de la URL inicial y así sucesivamente.
- Establecimiento de la dirección del rastreador: una vez que los datos de la URL semilla se han extraído y almacenado en la memoria temporal, los hipervínculos presentes en los datos deben proporcionarse al puntero y luego el sistema debe concentrarse en extraer datos de ellos.
- Cola : extracción y almacenamiento de todas las páginas que analiza el rastreador, mientras se recorre en un solo repositorio como archivos HTML.
- Deduplicación : eliminación de registros o datos duplicados.
- Normalización : normalización de los datos en función de los requisitos del cliente (suma, desviación estándar, formato de moneda, etc.)
- Estructuración : los datos no estructurados se convierten en un formato estructurado que puede consumir la base de datos.
- Integración de datos : los clientes pueden utilizar la API REST para obtener los datos personalizados necesarios. PromptCloud también puede enviar los datos al FTP, S3 o cualquier otro almacenamiento en la nube deseado para una fácil integración de los datos en el proceso de la empresa.
P. ¿Se puede rastrear la web de Facebook?
R. Hay una gran demanda de datos generados en Facebook. Se puede usar para cualquier cosa, desde el control de sentimientos y la gestión de la reputación hasta el descubrimiento de tendencias y las predicciones del mercado de valores. Sin embargo, se ha prohibido rastrear y extraer datos de Facebook a través del archivo robots.txt y los términos de servicio.
Esto concluye la serie de preguntas y respuestas. Publique sus preguntas en los comentarios si desea discutir más o si tiene preguntas que no hemos abordado aquí.