
Răspuns la Lista finală de întrebări frecvente despre Web Scraping – PromptCloud
Publicat: 2019-09-03Web scraping a câștigat o popularitate extraordinară în ultimii 10 ani și continuă să atragă companiile să folosească datele web pentru diverse cazuri de afaceri. Majoritatea companiilor din domeniul comerțului electronic, al călătoriilor, al locurilor de muncă și al spațiului de cercetare fie au înființat un sistem intern de crawling, fie se angajează cu un furnizor de servicii de crawling dedicat. Aici, vă oferim întrebări frecvente despre Web Scraping, care vă vor ajuta să curățați îndoielile.
Iată o căutare de tendințe Google care arată un interes tot mai mare pentru web scraping:
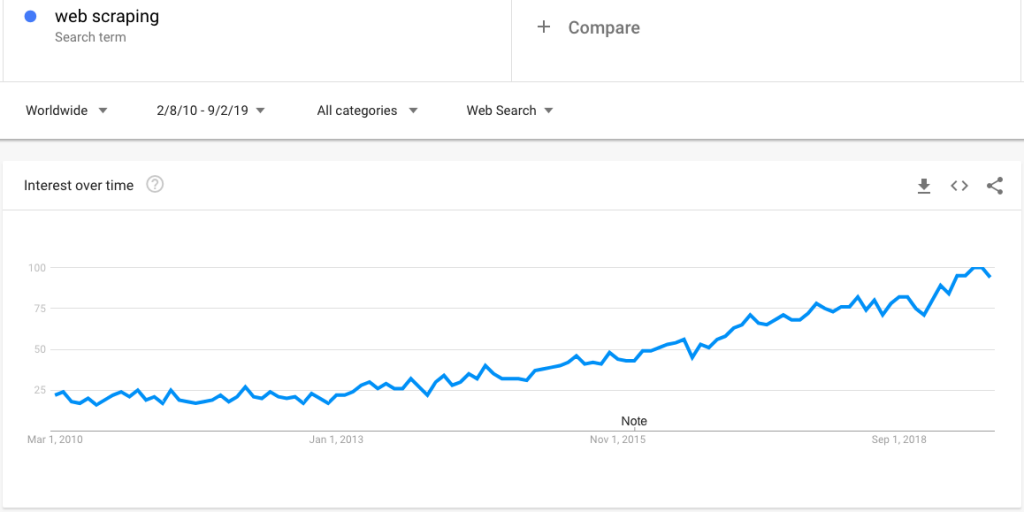
Cu toate acestea, odată cu un interes din ce în ce mai mare, apar un număr mare de întrebări legate de web scraping. În această postare, clarificăm un set extins de întrebări:
Î. Ce este web scraping?
A. Web Scraping (cunoscut și ca extragerea datelor web și recoltarea web) este tehnica de automatizare a procesului de colectare a datelor de pe site-uri web printr-un program inteligent și de salvare a acestora într-un format structurat pentru acces la cerere. De asemenea, poate fi programat să acceseze cu crawlere datele la o anumită frecvență, cum ar fi zilnic, săptămânal și lunar, sau să livreze date aproape în timp real.
Î. Care web scraping este cea mai bună?
R. Există mai multe modalități de extragere de pe web — de la furnizori de servicii de scraping web dedicati la furnizori de flux de date specifici verticali (de exemplu JobsPikr pentru date despre locuri de muncă) și instrumente de scraping (pot fi configurate pentru a realiza colectarea de date web simplă și unică) .
Alegerea soluției și a abordării depinde într-adevăr de cerințele specifice. Ca regulă generală, luați în considerare un serviciu de scraping web atunci când trebuie să colectați cantități mari de date web (citește milioane de înregistrări în fiecare săptămână sau zi).
Î. Pentru ce se folosește web scraping?
A. Există mai multe cazuri de utilizare a web scraping. Iată cele mai comune:
- comparatie produs si pret
- extragerea de informații și gestionarea reputației prin extragerea datelor de revizuire
- inteligenta competitiva
- catalogarea produselor
- antrenament algoritm de învățare automată
- cercetarea si analiza anumitor industrii
Î. Ce este web scraping în python?
A. Web scraping poate fi realizat prin diferite limbaje de programare și scripting. Cu toate acestea, Python este o alegere populară, iar Beautiful Soup este un pachet Python folosit frecvent pentru analizarea documentelor HTML și XML.
Am scris câteva tutoriale pe acest subiect - puteți afla despre ele din postarea noastră despre exemplele de web scraping.
Î. Ce este web scraping și crawling?
A. Web scraping poate fi considerat un superset de web crawling - în esență, web crawling se face pentru a parcurge căile paginilor web, astfel încât diferiți pași de web scraping să poată fi aplicați pentru a extrage și descărca date.
Î. Ce sunt instrumentele de scraping web?
R. Acestea sunt în primul rând instrumente DIY în care colectorul de date trebuie să învețe instrumentul și să îl configureze pentru a extrage date. Aceste instrumente sunt în general bune pentru proiecte unice de colectare a datelor web de pe site-uri simple. În general, ele eșuează atunci când vine vorba de extragerea de date cu volum mare sau când site-urile țintă sunt complexe și dinamice.
Î. Ce este web scraping Reddit?
R. Acesta este pur și simplu procesul de extragere a datelor din Reddit, care este o platformă socială populară pentru a construi diferite tipuri de comunități și forumuri. Datele de la Reddit pot fi răzuite pentru a efectua cercetări asupra consumatorilor, analiză a sentimentelor, NLP și instruire în învățarea automată.

Î. Ce sunt serviciile web scraping?
A. Serviciul de web scraping este pur și simplu procesul de preluare a proprietății complete asupra conductei de achiziție de date. Clienții oferă, în general, cerințele în ceea ce privește site-urile țintă, câmpurile de date, formatul fișierului și frecvența extragerii. Furnizorul de date furnizează datele web exact pe baza cerințelor, având grijă, în același timp, de întreținerea fluxului de date și de asigurarea calității.
Î. Ce este web scraping LinkedIn?
R. Deși multe companii ar dori să acceseze date de pe LinkedIn, acest lucru nu este permis din punct de vedere legal pe baza fișierului robots.txt și a termenilor de utilizare.
Î. Când să accesați cu crawlere web?
R. În calitate de companie, ar trebui să accesați cu crawlere web atunci când trebuie să efectuați oricare dintre cazurile de utilizare menționate mai sus și doriți să vă măriți datele interne cu seturi alternative cuprinzătoare de date.
Î. Este legală web scraping?
R. Este într-adevăr legal atâta timp cât urmați liniile directoare referitoare la directivele stabilite în fișierul robots.txt, termenii de utilizare, accesul la conținut public și privat. Aflați mai multe despre legalitate.
Î. Web scraping este minarea de date?
A. Miningul de date este procesul de descoperire a perspectivelor din seturi de date la scară largă prin implementarea tehnicilor la intersecția sistemelor de învățare automată, statistici și baze de date. Deci, datele extrase prin tehnica web scraping vor fi procesate prin diverse analize, iar procesul complet de achiziție a datelor până la minarea insight poate fi numit data mining.
Î. Ce este web scraping BeautifulSoup?
A. Beautiful Soup este o bibliotecă Python care permite programatorilor să lucreze rapid la proiecte web scraping prin crearea unui arbore de analiză din documente HTML și XML (inclusiv documente cu etichete neînchise sau supă de etichete și alte markupuri malformate) pentru paginile web.
Versiunea actuală a Beautiful Soup 4 este compatibilă atât cu Python 2.7, cât și cu Python 3.
Î. Cum se colectează date web – web scraping vs. API?
A. API-urile sau interfețele de programare a aplicațiilor sunt un intermediar care permite unui software să vorbească cu altul. Când utilizați un API pentru a colecta date, veți fi strict guvernat de un set de reguli și există doar câteva câmpuri de date specifice pe care le puteți obține.
Dar, în cazul web scraping-ului, clienții nu sunt restricționați de rata de acces, câmpurile de date (tot ce este prezent pe web, poate fi descărcat), opțiunile de personalizare și întreținere.
Î. Ce este web scraping în R?
A. Similar cu Python , R (un limbaj folosit pentru analiza statistică) poate fi folosit și pentru a colecta date de pe web. Rețineți că rvest este un pachet popular pentru ecosistemul R
Cu toate acestea, nu este la fel de puternic ca Python sau Ruby pentru web scraping.
Î. De ce este importantă web scraping?
A. Web scraping este important, deoarece permite companiilor și oamenilor din întreaga lume să acceseze datele web, care este cel mai mare și cuprinzător depozit de date până în prezent. Am menționat mai multe cazuri de utilizare într-o întrebare anterioară.
Consultați pagina de studiu de caz pentru a afla mai multe.
Î. Cum funcționează web scraping?
A. Web scraping, în general, operează cu mai mulți pași. Iată pașii pe care PromptCloud îi urmează la un nivel înalt:
- Seeding – Este o procedură asemănătoare cu traversarea arborelui, în care crawler-ul parcurge mai întâi adresa URL de bază sau URL-ul de bază și apoi caută următoarea adresă URL din datele care sunt preluate de la adresa URL de bază și așa mai departe.
- Setarea direcției pentru crawler – Odată ce datele din URL-ul de bază au fost extrase și stocate în memoria temporară, hyperlinkurile prezente în date trebuie să fie date pointerului și apoi sistemul ar trebui să se concentreze pe extragerea datelor din acestea.
- Queuing – Extragerea și stocarea tuturor paginilor pe care crawlerul le analizează, în timp ce parcurge într-un singur depozit ca fișiere HTML.
- Deduplicare – Eliminarea înregistrărilor sau datelor duplicate.
- Normalizare – Normalizarea datelor pe baza cerințelor clientului (suma, abaterea standard, formatarea monedei etc.)
- Structurare – Datele nestructurate sunt convertite într-un format structurat care poate fi consumat de baza de date.
- Integrarea datelor – API-ul REST poate fi folosit de clienți pentru a prelua datele personalizate necesare. PromptCloud poate, de asemenea, să împingă datele către FTP-ul dorit, S3 sau orice alt spațiu de stocare în cloud pentru o integrare ușoară a datelor în procesul companiei.
Î. Puteți accesa cu crawlere pe internet Facebook?
A. Există o cerere uriașă de date generate pe Facebook. Poate fi folosit pentru orice, de la monitorizarea sentimentului și gestionarea reputației până la descoperirea tendințelor și predicțiile bursiere. Cu toate acestea, accesarea cu crawlere și extragerea datelor de pe Facebook a fost interzisă prin fișierul robots.txt și prin termenii și condițiile.
Aceasta încheie seria de întrebări și răspunsuri. Postați întrebările dvs. în comentarii dacă doriți să discutați mai multe sau aveți întrebări pe care nu le-am abordat aici.