
Odpowiedzi na ostateczną listę najczęściej zadawanych pytań na temat złomowania sieci — PromptCloud
Opublikowany: 2019-09-03Web scraping zyskał ogromną popularność w ciągu ostatnich 10 lat i nadal przyciąga firmy do wykorzystywania danych internetowych w różnych przypadkach biznesowych. Większość firm zajmujących się handlem elektronicznym, podróżami, pracą i badaniami naukowymi utworzyło własny system indeksowania lub współpracuje z dedykowanym dostawcą usług indeksowania sieci. W tym miejscu udostępniamy często zadawane pytania na temat usuwania danych z sieci, które pomogą Ci rozwiać wątpliwości.
Oto wyszukiwanie trendów Google, które pokazuje rosnące zainteresowanie web scrapingiem:
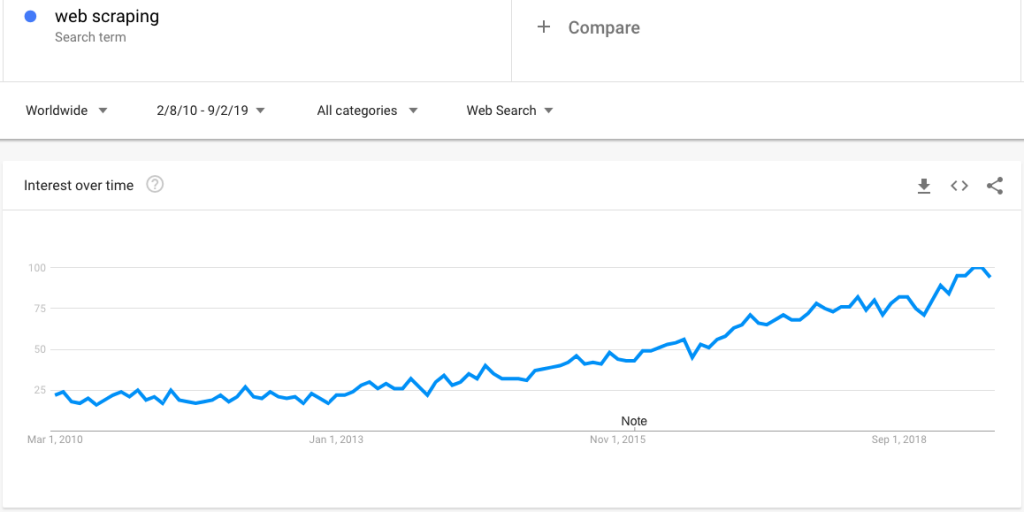
Jednak wraz z rosnącym zainteresowaniem pojawia się duża liczba pytań dotyczących web scrapingu. W tym poście wyjaśniamy obszerny zestaw pytań:
P. Co to jest zbieranie sieci?
O. Web Scraping (znany również jako ekstrakcja danych z sieci i gromadzenie sieci) to technika automatyzacji procesu zbierania danych ze stron internetowych za pomocą inteligentnego programu i zapisywania ich w ustrukturyzowanym formacie w celu uzyskania dostępu na żądanie. Można go również zaprogramować tak, aby przeszukiwał dane z określoną częstotliwością, na przykład codziennie, co tydzień i co miesiąc, lub dostarczał dane w czasie zbliżonym do rzeczywistego.
P. Który skrobak sieciowy jest najlepszy?
A. Istnieje kilka sposobów wyodrębniania z sieci — od dedykowanych dostawców usług web scrapingu po dostawców kanałów danych specyficznych dla danej branży (np. JobsPikr dla danych o pracy) i narzędzia do scrapingu (można skonfigurować tak, aby wykonywać proste i jednorazowe zbieranie danych z sieci) .
Wybór rozwiązania i podejścia tak naprawdę zależy od konkretnych wymagań. Zasadniczo rozważ usługę web scrapingu, gdy musisz zebrać duże ilości danych internetowych (odczytuje miliony rekordów każdego tygodnia lub dnia).
P. Do czego służy web scraping?
O. Istnieje kilka przypadków użycia skrobania sieci. Oto najczęstsze:
- porównanie produktów i cen
- eksploracja wglądu i zarządzanie reputacją poprzez ekstrakcję danych przeglądowych
- inteligencja konkurencyjna
- katalogowanie produktów
- algorytm uczenia maszynowego
- badania i analizy wybranych branż
P. Co to jest web scraping w Pythonie?
A. Web scraping można wykonać za pomocą różnych języków programowania i skryptów. Jednak Python jest popularnym wyborem, a Beautiful Soup jest często używanym pakietem Pythona do analizowania dokumentów HTML i XML.
Napisaliśmy kilka samouczków na ten temat — możesz dowiedzieć się o nich z naszego postu na przykładach web scrapingu.
P. Co to jest zbieranie i indeksowanie stron internetowych?
A. Web scraping można uznać za nadzbiór indeksowania sieci — zasadniczo indeksowanie sieci odbywa się w celu przechodzenia przez ścieżki stron internetowych, dzięki czemu można zastosować różne etapy skrobania sieci w celu wyodrębnienia i pobrania danych.
P. Czym są narzędzia do skrobania sieci?
O. Są to przede wszystkim narzędzia typu „zrób to sam”, w których zbieracz danych musi poznać narzędzie i skonfigurować je, aby wyodrębnić dane. Narzędzia te są zazwyczaj dobre dla jednorazowych projektów zbierania danych internetowych z prostych witryn. Zwykle zawodzą, jeśli chodzi o ekstrakcję dużych ilości danych lub gdy docelowe witryny są złożone i dynamiczne.
P. Co to jest Reddit do zgarniania stron internetowych?
O. Jest to po prostu proces wydobywania danych z Reddit, który jest popularną platformą społecznościową do budowania różnego rodzaju społeczności i forów. Dane z Reddit można zeskrobać, aby przeprowadzić badania konsumenckie, analizę sentymentu, NLP i szkolenia z uczenia maszynowego.

P. Co to są usługi web scrapingu?
Usługa Web scraping to po prostu proces przejmowania pełnej własności potoku akwizycji danych. Klienci zazwyczaj dostarczają wymagania w zakresie witryn docelowych, pól danych, formatu pliku i częstotliwości ekstrakcji. Dostawca danych dostarcza dane internetowe dokładnie w oparciu o wymagania, dbając jednocześnie o utrzymanie strumienia danych i zapewnienie jakości.
P. Co to jest web scraping LinkedIn?
O. Chociaż wiele firm chciałoby uzyskać dostęp do danych z LinkedIn, jest to prawnie zabronione na podstawie pliku robots.txt i warunków użytkowania.
P. Kiedy indeksować sieć?
O. Jako firma powinieneś przeszukiwać sieć, gdy musisz wykonać którykolwiek z wymienionych powyżej przypadków użycia i chcesz rozszerzyć swoje dane wewnętrzne o kompleksowe alternatywne zestawy danych.
P. Czy skrobanie stron internetowych jest legalne?
O. Jest to rzeczywiście legalne, o ile przestrzegasz wytycznych dotyczących dyrektyw zawartych w pliku robots.txt, warunków użytkowania, dostępu do treści publicznych i prywatnych. Dowiedz się więcej o legalności.
P. Czy web scraping jest eksploracją danych?
O. Eksploracja danych to proces odkrywania spostrzeżeń z zestawów danych o dużej skali poprzez wdrażanie technik na styku uczenia maszynowego, statystyk i systemów baz danych. Tak więc dane wyodrębnione za pomocą techniki web scrapingu będą przetwarzane za pomocą różnych analiz, a pełny proces pozyskiwania danych do eksploracji wglądu można nazwać eksploracją danych.
P. Co to jest zbieranie sieci Web BeautifulSoup?
O. Beautiful Soup to biblioteka Pythona, która umożliwia programistom szybką pracę nad projektami web scrapingu, tworząc drzewo analizy z dokumentów HTML i XML (w tym dokumentów z niezamkniętymi znacznikami lub zupą znaczników i innymi zniekształconymi znacznikami) dla stron internetowych.
Aktualna wersja Beautiful Soup 4 jest kompatybilna zarówno z Pythonem 2.7, jak i Pythonem 3.
P. Jak zbierać dane z sieci – web scraping vs. API?
A. API lub interfejsy programowania aplikacji to pośrednik, który umożliwia komunikację między jednym oprogramowaniem a drugim. Podczas korzystania z interfejsu API do zbierania danych będziesz ściśle kontrolowany przez zestaw reguł, a dostępne są tylko niektóre określone pola danych.
Ale w przypadku web scrapingu klienci nie są ograniczeni szybkością dostępu, polami danych (wszystko, co jest obecne w sieci, można pobrać), opcje dostosowywania i konserwację.
P. Co to jest web scraping w R?
O. Podobnie jak Python , R (język używany do analizy statystycznej) może być również używany do zbierania danych z sieci. Zauważ, że rvest jest popularnym pakietem w ekosystemie R
Jednak nie jest tak potężny jak Python czy Ruby w przypadku web scrapingu.
P. Dlaczego skrobanie sieci jest ważne?
Odp. Web scraping jest ważny, ponieważ umożliwia firmom i ludziom na całym świecie dostęp do danych internetowych, które są jak dotąd największym i wszechstronnym repozytorium danych. W poprzednim pytaniu wspomnieliśmy o kilku przypadkach użycia.
Sprawdź stronę studium przypadku, aby dowiedzieć się więcej.
P. Jak działa skrobanie sieci?
A. Skrobanie sieci na ogół działa w kilku krokach. Oto kroki, które PromptCloud wykonuje na wysokim poziomie:
- Seding – Jest to procedura podobna do przechodzenia przez drzewo, w której robot najpierw przechodzi przez początkowy adres URL lub podstawowy adres URL, a następnie szuka następnego adresu URL w danych pobranych z początkowego adresu URL i tak dalej.
- Ustalanie kierunku dla robota indeksującego – Po wyodrębnieniu danych z początkowego adresu URL i zapisaniu ich w pamięci tymczasowej, hiperłącza obecne w danych należy podać wskaźnikowi, a następnie system powinien skoncentrować się na wyodrębnianiu z nich danych.
- Kolejkowanie — wyodrębnianie i przechowywanie wszystkich stron analizowanych przez robota podczas przechodzenia w jednym repozytorium jako pliki HTML.
- Deduplikacja — usuwanie zduplikowanych rekordów lub danych.
- Normalizacja – Normalizacja danych w oparciu o wymagania klienta (suma, odchylenie standardowe, formatowanie waluty itp.)
- Strukturyzacja — nieustrukturyzowane dane są konwertowane na ustrukturyzowany format, który może być używany przez bazę danych.
- Integracja danych — REST API może być używany przez klientów do pobierania wymaganych danych niestandardowych. PromptCloud może również przesyłać dane do żądanego FTP, S3 lub dowolnego innego magazynu w chmurze w celu łatwej integracji danych w procesie firmy.
P. Czy możesz indeksować Facebooka?
O. Istnieje ogromne zapotrzebowanie na dane generowane na Facebooku. Może być używany do wszystkiego, od monitorowania nastrojów i zarządzania reputacją po odkrywanie trendów i prognozy giełdowe. Jednak indeksowanie i wydobywanie danych z Facebooka zostało zabronione za pośrednictwem pliku robots.txt i warunków korzystania z usługi.
Na tym kończy się seria pytań i odpowiedzi. Opublikuj swoje pytania w komentarzach, jeśli chcesz omówić więcej lub masz pytania, na które nie odpowiedzieliśmy tutaj.