
Web スクレイピングに関する FAQ の究極のリスト – PromptCloud
公開: 2019-09-03Web スクレイピングは、過去 10 年間で絶大な人気を博しており、さまざまなビジネス ケースで Web データを活用する企業を引きつけ続けています。 e コマース、旅行、仕事、研究スペースを使用する企業の大半は、社内のクローリング システムをセットアップするか、専用の Web クローリング サービス プロバイダーと提携しています。 ここでは、疑問を解消するのに役立つ Web スクレイピングに関する FAQ を提供します。
以下は、Web スクレイピングへの関心の高まりを示す Google トレンド検索です。
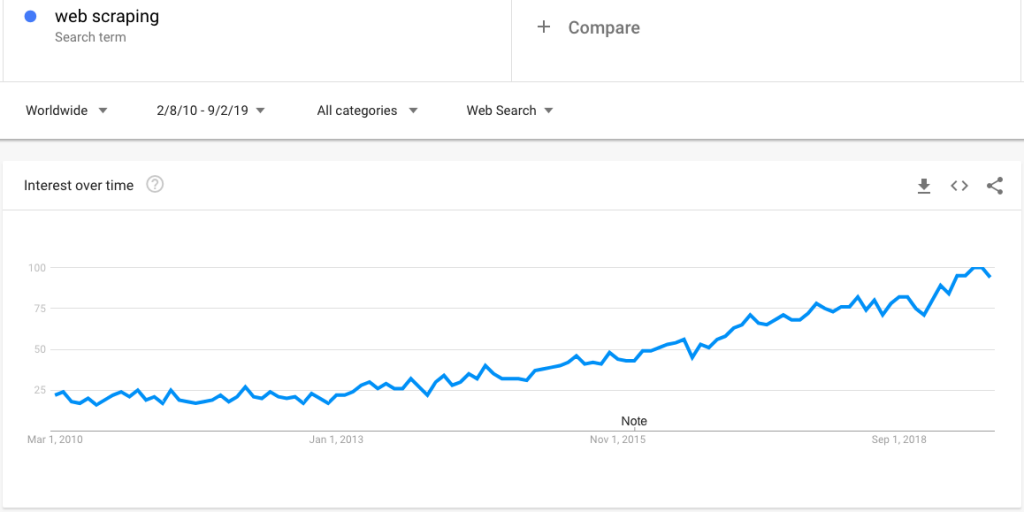
しかし、関心が高まるにつれて、Web スクレイピングに関する多くの質問が寄せられています。 この投稿では、広範な一連の質問を明確にします。
Q. Web スクレイピングとは何ですか?
A. Web スクレイピング (Web データ抽出および Web ハーベスティングとも呼ばれます) は、インテリジェントなプログラムを介して Web サイトからデータを収集するプロセスを自動化し、オンデマンド アクセス用に構造化された形式でデータを保存する技術です。 また、毎日、毎週、毎月などの特定の頻度でデータをクロールしたり、ほぼリアルタイムでデータを配信したりするようにプログラムすることもできます。
Q. どの Web スクレイピングが最適ですか?
A. Web から抽出する方法はいくつかあります。専用の Web スクレイピング サービス プロバイダーから、業界固有のデータ フィード プロバイダー (ジョブ データ用の JobsPikr など) やスクレイピング ツール (シンプルで 1 回限りの Web データ収集を実行するように構成できます) まであります。 .
ソリューションとアプローチの選択は、特定の要件によって異なります。 原則として、大量の Web データを収集する必要がある場合 (毎週または毎日何百万ものレコードを読み取る)、Web スクレイピング サービスの提供を検討してください。
Q. Web スクレイピングは何に使用されますか?
A. Web スクレイピングにはいくつかの使用例があります。 最も一般的なものは次のとおりです。
- 製品と価格の比較
- レビューデータ抽出によるインサイトマイニングと評判管理
- 競争力のある知性
- 製品カタログ
- トレーニング機械学習アルゴリズム
- 特定の業界の調査と分析
Q. Python の Web スクレイピングとは何ですか?
A. Web スクレイピングは、さまざまなプログラミング言語やスクリプト言語を使用して行うことができます。 ただし、Python が一般的な選択肢であり、Beautiful Soup は HTML および XML ドキュメントの解析によく使用される Python パッケージです。
このトピックに関するいくつかのチュートリアルを作成しました。それらについては、Web スクレイピングの例に関する投稿から学ぶことができます。
Q. Web スクレイピングとクローリングとは何ですか?
A. Web スクレイピングは、Web クローリングのスーパーセットと見なすことができます。基本的に、Web クロールは Web ページのパスをトラバースするために行われるため、Web スクレイピングのさまざまなステップを適用してデータを抽出およびダウンロードできます。

Q. Web スクレイピング ツールとは何ですか?
A. これらは主に DIY ツールであり、データ コレクターがツールを学習し、データを抽出するように構成する必要があります。 これらのツールは通常、単純なサイトからの 1 回限りの Web データ収集プロジェクトに適しています。 大量のデータを抽出する場合や、ターゲット サイトが複雑で動的な場合、通常は失敗します。
Q. Web スクレイピング Reddit とは何ですか?
A. これは、さまざまな種類のコミュニティやフォーラムを構築するための人気のあるソーシャル プラットフォームである Reddit からデータを抽出するプロセスにすぎません。 Reddit からのデータをスクレイピングして、消費者調査、感情分析、NLP、および機械学習トレーニングを実行できます。
Q. Webスクレイピングサービスとは何ですか?
A. Web スクレイピング サービスは、単にデータ取得パイプラインの完全な所有権を取得するプロセスです。 クライアントは通常、ターゲット サイト、データ フィールド、ファイル形式、および抽出の頻度に関する要件を提供します。 データ ベンダーは、データ フィードのメンテナンスと品質保証を行いながら、要件に正確に基づいて Web データを配信します。
Q.Web スクレイピング LinkedIn とは何ですか?
A. 多くの企業が LinkedIn からデータにアクセスしたいと考えていますが、robots.txt ファイルと利用規約に基づいて法的に許可されていません。
Q.いつ Web クロールするのですか?
A. 企業として、上記のユース ケースのいずれかを実行する必要があり、包括的な代替データ セットを使用して内部データを増強したい場合は、Web クロールを行う必要があります。
Q. Web スクレイピングは合法ですか?
A. robots.txt ファイルに設定されたディレクティブ、使用条件、パブリックおよびプライベート コンテンツへのアクセスに関するガイドラインに従っている限り、合法です。 合法性についてもっと学びましょう。
Q. Web スクレイピングはデータマイニングですか?
A. データ マイニングは、機械学習、統計、およびデータベース システムの交差点に技術を展開することによって、大規模なデータ セットから洞察を明らかにするプロセスです。 したがって、Webスクレイピング技術によって抽出されたデータは、さまざまな分析によって処理され、データ取得から洞察マイニングまでの完全なプロセスは、データマイニングと呼ばれます。
Q. Web スクレイピング BeautifulSoup とは何ですか?
A. Beautiful Soup は、Web ページの HTML および XML ドキュメント (閉じられていないタグまたはタグ スープおよびその他の不正な形式のマークアップを含むドキュメントを含む) から解析ツリーを作成することにより、プログラマーが Web スクレイピング プロジェクトに迅速に取り組めるようにする Python ライブラリです。
Beautiful Soup 4 の現在のバージョンは、Python 2.7 と Python 3 の両方と互換性があります。
Q. Web データの収集方法 – Web スクレイピング vs. API?
A. API またはアプリケーション プログラミング インターフェイスは、あるソフトウェアが別のソフトウェアと対話できるようにする仲介者です。 API を使用してデータを収集する場合、一連のルールによって厳密に管理され、取得できる特定のデータ フィールドがいくつかあります。
ただし、Web スクレイピングの場合、クライアントはアクセス速度、データ フィールド (Web 上に存在するものはすべてダウンロード可能)、カスタマイズ オプション、およびメンテナンスによって制限されません。
Q.R の Web スクレイピングとは何ですか?
A. Pythonと同様に、 R (統計分析に使用される言語) も Web からデータを収集するために使用できます。 rvestはRエコシステムで人気のあるパッケージであることに注意してください。
ただし、Web スクレイピングに関しては、 PythonやRubyほど強力ではありません。
Q. Web スクレイピングが重要な理由は何ですか?
A. Web スクレイピングは、これまでで最大かつ包括的なデータ リポジトリである Web データに世界中の企業や人々がアクセスできるようにするために重要です。 以前の質問でいくつかの使用例について言及しました。
詳細については、ケース スタディのページをご覧ください。
Q. Web スクレイピングのしくみを教えてください。
A. 一般に、Web スクレイピングはいくつかのステップで動作します。 PromptCloud が高レベルで従う手順は次のとおりです。
- シーディング– これは、クローラーが最初にシード URL またはベース URL を調べてから、シード URL からフェッチされたデータ内の次の URL を探すなど、ツリー トラバーサルのような手順です。
- クローラーの方向を設定する – シード URL からのデータが抽出されて一時メモリに保存されたら、データ内に存在するハイパーリンクをポインターに与える必要があり、システムはそれらからのデータの抽出に集中する必要があります。
- キューイング– クローラーが解析するすべてのページを抽出して保存し、単一のリポジトリを HTML ファイルとしてトラバースします。
- 重複排除– 重複したレコードまたはデータを削除します。
- 正規化– クライアントの要件 (合計、標準偏差、通貨の書式設定など) に基づいてデータを正規化します。
- 構造化– 非構造化データは、データベースで使用できる構造化形式に変換されます。
- データ統合– クライアントは REST API を使用して、必要なカスタム データを取得できます。 PromptCloud は、必要な FTP、S3、またはその他のクラウド ストレージにデータをプッシュして、会社のプロセスにデータを簡単に統合することもできます。
Q. Facebookのクロールはできますか??
A. Facebook で生成されたデータには大きな需要があります。 感情の監視や評判の管理から、トレンドの発見や株式市場の予測まで、あらゆる用途に使用できます。 ただし、Facebook からのデータのクロールと抽出は、robots.txt ファイルと利用規約によって禁止されています。
質疑応答シリーズはこれにて終了です。 さらに議論したい場合や、ここで取り上げていない質問がある場合は、コメントに質問を投稿してください。