
網絡抓取常見問題解答的終極清單 – PromptCloud
已發表: 2019-09-03Web 抓取在過去 10 年中獲得了極大的普及,並且仍然繼續吸引企業將 Web 數據用於各種業務案例。 電子商務、旅遊、工作和研究領域的大多數公司要么建立了內部爬蟲系統,要么與專門的網絡爬蟲服務提供商合作。 在這裡,我們提供了一個關於 Web Scraping 的常見問題解答,可以幫助您消除疑慮。
這是一個谷歌趨勢搜索,顯示出對網絡抓取越來越感興趣:
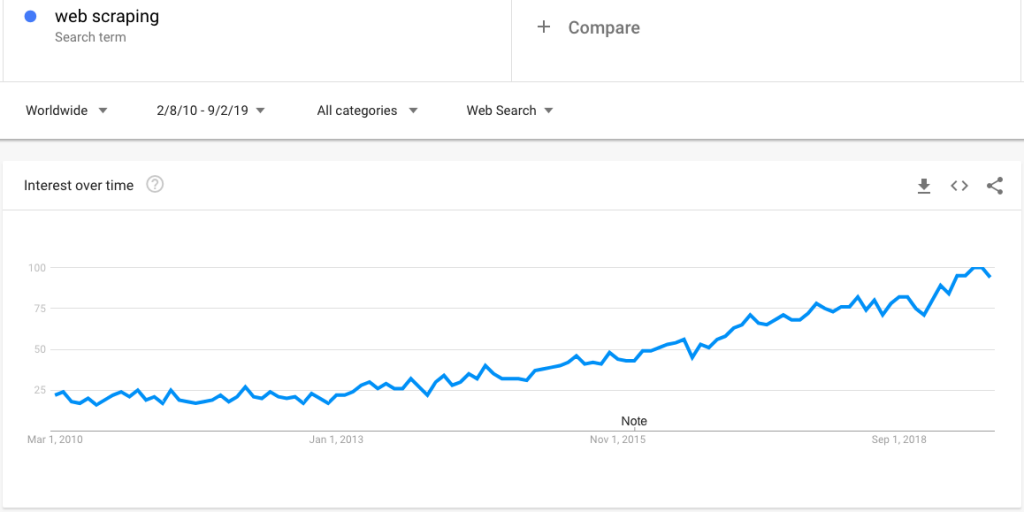
然而,隨著人們的興趣越來越大,關於網絡抓取的大量問題也隨之而來。 在這篇文章中,我們澄清了一系列廣泛的問題:
問:什麼是網頁抓取?
A. Web Scraping(也稱為 Web 數據提取和 Web 收集)是一種通過智能程序從網站收集數據的過程自動化並將其保存為結構化格式以供按需訪問的技術。 它還可以編程為以特定頻率(如每日、每周和每月)抓取數據,或近乎實時地交付數據。
問:哪個網頁抓取最好?
A. 從 Web 中提取數據的方式有多種——從專門的 Web 抓取服務提供商到垂直特定的數據饋送提供商(例如 JobsPikr 用於工作數據)和抓取工具(可以配置為執行簡單的一次性 Web 數據收集) .
解決方案和方法的選擇實際上取決於具體要求。 作為一般規則,當您需要收集大量網絡數據(每週或每天讀取數百萬條記錄)時,請考慮提供網絡抓取服務。
問:網絡抓取有什麼用?
A. 網頁抓取有幾個用例。 以下是最常見的:
- 產品和價格比較
- 通過評論數據提取進行洞察力挖掘和聲譽管理
- 競爭情報
- 產品編目
- 訓練機器學習算法
- 某些行業的研究和分析
問:python 中的網頁抓取是什麼?
A. Web 抓取可以通過不同的編程和腳本語言來完成。 然而,Python 是一個流行的選擇,Beautiful Soup 是一個常用的 Python 包,用於解析 HTML 和 XML 文檔。

我們已經寫了幾個關於這個主題的教程——你可以從我們關於網絡抓取示例的帖子中了解它們。
Q. 什麼是網頁抓取?
A. 網頁抓取可以被認為是網頁抓取的超集——本質上,網頁抓取是為了遍歷網頁的路徑,以便可以應用網頁抓取的不同步驟來提取和下載數據。
問:什麼是網頁抓取工具?
A. 這些主要是 DIY 工具,數據收集者需要在其中學習該工具並對其進行配置以提取數據。 這些工具通常適用於來自簡單站點的一次性 Web 數據收集項目。 當涉及大量數據提取或目標站點複雜且動態時,它們通常會失敗。
問:什麼是網絡抓取 Reddit?
答:這只是從 Reddit 中提取數據的過程,Reddit 是一個流行的社交平台,用於構建不同類型的社區和論壇。 可以從 Reddit 抓取數據以執行消費者研究、情緒分析、NLP 和機器學習訓練。
問:什麼是網頁抓取服務?
A. Web 抓取服務只是獲取數據採集管道的全部所有權的過程。 客戶通常會根據目標站點、數據字段、文件格式和提取頻率提出要求。 數據供應商準確地根據要求提供 Web 數據,同時負責數據饋送的維護和質量保證。
問:什麼是網絡抓取 LinkedIn?
答:雖然很多公司都想從 LinkedIn 訪問數據,但根據 robots.txt 文件和使用條款,這是法律上不允許的。
問:何時進行網絡爬取?
答:作為一家公司,當您需要執行上述任何用例並希望使用全面的替代數據集來擴充您的內部數據時,您應該進行網絡爬網。
問:網絡抓取合法嗎?
A. 只要您遵循 robots.txt 文件中設置的指令、使用條款、訪問公共和私人內容的指導方針,這確實是合法的。 了解更多關於合法性的信息。
Q. 網頁抓取是數據挖掘嗎?
A. 數據挖掘是通過在機器學習、統計和數據庫系統的交叉點部署技術,從大規模數據集中發現見解的過程。 因此,通過網絡抓取技術提取的數據將經過各種分析處理,從數據獲取到洞察力挖掘的完整過程可以稱為數據挖掘。
Q. 什麼是網頁抓取 BeautifulSoup?
A. Beautiful Soup 是一個 Python 庫,它允許程序員通過從 HTML 和 XML 文檔(包括帶有非封閉標籤或標籤湯和其他格式錯誤的標記的文檔)為網頁創建解析樹來快速處理 Web 抓取項目。
Beautiful Soup 4 的當前版本兼容 Python 2.7 和 Python 3。
問:如何收集網絡數據——網絡抓取與 API?
A. API 或應用程序編程接口是允許一個軟件與另一個軟件對話的中介。 在使用 API 收集數據時,您將受到一組規則的嚴格約束,並且您只能獲取一些特定的數據字段。
但是,在網絡抓取的情況下,客戶端不受訪問速率、數據字段(網絡上存在的任何內容都可以下載)、自定義選項和維護的限制。
問:什麼是 R 中的網頁抓取?
A. 與Python類似, R (一種用於統計分析的語言)也可用於從 Web 收集數據。 請注意, rvest是R生態系統中的一個流行包。
但是,它在網絡抓取方面不如Python或Ruby強大。
問:為什麼網頁抓取很重要?
答:網絡抓取很重要,因為它允許全球的企業和個人訪問網絡數據,這是迄今為止最大和最全面的數據存儲庫。 我們在前面的問題中提到了幾個用例。
查看案例研究頁面以了解更多信息。
問:網絡抓取如何工作?
A. 一般來說,網頁抓取有幾個步驟。 以下是 PromptCloud 在高層次上遵循的步驟:
- 播種——這是一個類似樹遍歷的過程,其中爬蟲首先遍歷種子 URL 或基本 URL,然後在從種子 URL 獲取的數據中查找下一個 URL,依此類推。
- 設置爬蟲的方向——一旦從種子 URL 中提取數據並將其存儲在臨時內存中,數據中存在的超鏈接需要提供給指針,然後系統應該專注於從中提取數據。
- 排隊- 提取和存儲爬蟲解析的所有頁面,同時作為 HTML 文件在單個存儲庫中遍歷。
- 重複數據刪除——刪除重複的記錄或數據。
- 規範化——根據客戶要求(總和、標準偏差、貨幣格式等)對數據進行規範化
- 結構化——非結構化數據被轉換為數據庫可以使用的結構化格式。
- 數據集成——客戶端可以使用 REST API 來獲取所需的自定義數據。 PromptCloud 還可以將數據推送到所需的 FTP、S3 或任何其他雲存儲,以便在公司流程中輕鬆集成數據。
Q. 你能抓取 Facebook 嗎?
A. 對 Facebook 上生成的數據有巨大的需求。 它可用於從情緒監控和聲譽管理到趨勢發現和股市預測的任何事情。 但是,robots.txt 文件和服務條款已禁止從 Facebook 抓取和提取數據。
問答系列到此結束。 如果您想討論更多或有我們未在此處解決的問題,請在評論中發表您的問題。