
A lista definitiva de perguntas frequentes sobre Web Scraping respondidas – PromptCloud
Publicados: 2019-09-03A raspagem da Web ganhou enorme popularidade ao longo dos últimos 10 anos e ainda continua a atrair empresas para aproveitar os dados da Web para vários casos de negócios. A maioria das empresas no uso de e-commerce, viagens, trabalho e espaço de pesquisa ou configuraram um sistema de rastreamento interno ou se envolveram com um provedor de serviços de rastreamento da Web dedicado. Aqui, disponibilizamos um FAQ sobre Web Scraping que o ajudará a tirar as dúvidas.
Aqui está uma pesquisa de tendências do Google que mostra um interesse crescente em web scraping:
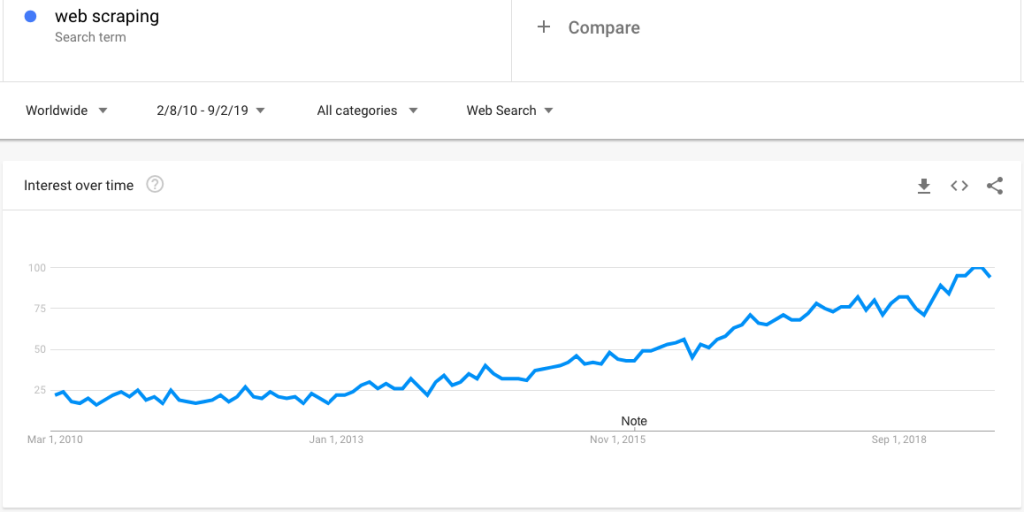
No entanto, com o crescente interesse, surge um grande número de perguntas sobre web scraping. Neste post, esclarecemos um extenso conjunto de perguntas:
P. O que é web scraping?
R. Web Scraping (também conhecido como extração de dados da web e coleta da web) é a técnica de automatizar o processo de coleta de dados de sites por meio de um programa inteligente e salvá-los em um formato estruturado para acesso sob demanda. Ele também pode ser programado para rastrear dados em uma determinada frequência, como diariamente, semanalmente e mensalmente, ou entregar dados quase em tempo real.
P. Qual web scraping é o melhor?
A. Existem várias maneiras de extrair da web — desde provedores de serviços de web scraping dedicados a provedores de feed de dados específicos da vertical (por exemplo, JobsPikr para dados de trabalho) e ferramentas de scraping (podem ser configuradas para realizar coleta de dados da web simples e única) .
A escolha da solução e abordagem realmente depende dos requisitos específicos. Como regra geral, considere um serviço de web scraping quando precisar coletar grandes quantidades de dados da web (lê milhões de registros toda semana ou dia).
P. Para que serve o web scraping?
R. Existem vários casos de uso de web scraping. Aqui estão os mais comuns:
- comparação de produtos e preços
- mineração de insights e gerenciamento de reputação por meio da extração de dados de revisão
- inteligencia competitiva
- catalogação de produtos
- algoritmo de aprendizado de máquina de treinamento
- pesquisa e análise de certas indústrias
P. O que é web scraping em python?
R. O web scraping pode ser feito por meio de diferentes linguagens de programação e script. No entanto, o Python é uma escolha popular e o Beautiful Soup é um pacote Python usado com frequência para analisar documentos HTML e XML.
Escrevemos alguns tutoriais sobre este tópico – você pode aprender sobre eles em nosso post sobre exemplos de web scraping.
P. O que é web scraping e crawling?
R. O web scraping pode ser considerado como um superconjunto de web crawling — essencialmente o web crawling é feito para percorrer caminhos de páginas da web para que diferentes etapas de web scraping possam ser aplicadas para extrair e baixar dados.
P. O que são ferramentas de web scraping?
R. Essas são principalmente ferramentas de bricolage nas quais o coletor de dados precisa aprender a ferramenta e configurá-la para extrair dados. Essas ferramentas geralmente são boas para projetos de coleta de dados da Web de sites simples. Eles geralmente falham quando se trata de extração de dados de grande volume ou quando os sites de destino são complexos e dinâmicos.
P. O que é web scraping Reddit?
R. Este é simplesmente o processo de extração de dados do Reddit, que é uma plataforma social popular para construir diferentes tipos de comunidades e fóruns. Os dados do Reddit podem ser extraídos para realizar pesquisas de consumidores, análise de sentimentos, PNL e treinamento de aprendizado de máquina.

P. O que são serviços de web scraping?
R. O serviço de web scraping é simplesmente o processo de apropriação total do pipeline de aquisição de dados. Os clientes geralmente fornecem o requisito em termos de sites de destino, campos de dados, formato de arquivo e frequência de extração. O fornecedor de dados entrega os dados da Web exatamente com base no requisito, enquanto cuida da manutenção do feed de dados e da garantia de qualidade.
P. O que é web scraping LinkedIn?
R. Embora muitas empresas queiram acessar dados do LinkedIn, isso não é permitido legalmente com base no arquivo robots.txt e nos termos de uso.
P. Quando rastrear a web?
R. Como empresa, você deve rastrear a Web quando precisar executar qualquer um dos casos de uso mencionados acima e quiser aumentar seus dados internos com conjuntos de dados alternativos abrangentes.
P. O web scraping é legal?
R. É realmente legal, desde que você siga as diretrizes em torno das diretivas definidas no arquivo robots.txt, termos de uso, acesso a conteúdo público e privado. Saiba mais sobre a legalidade.
P. O web scraping é mineração de dados?
R. A mineração de dados é o processo de descoberta de insights de conjuntos de dados em grande escala por meio da implantação de técnicas na interseção de aprendizado de máquina, estatísticas e sistemas de banco de dados. Assim, os dados extraídos através da técnica de web scraping serão processados por meio de diversas análises e o processo completo de aquisição de dados para mineração de insights pode ser chamado de mineração de dados.
P. O que é a raspagem da web BeautifulSoup?
R. Beautiful Soup é uma biblioteca Python que permite aos programadores trabalhar rapidamente em projetos de web scraping criando uma árvore de análise a partir de documentos HTML e XML (incluindo documentos com tags não fechadas ou tag soup e outras marcações malformadas) para as páginas da web.
A versão atual do Beautiful Soup 4 é compatível com Python 2.7 e Python 3.
P. Como coletar dados da web – web scraping vs. API?
R. APIs ou Interfaces de Programação de Aplicativos é um intermediário que permite que um software converse com outro. Ao usar uma API para coletar dados, você será estritamente regido por um conjunto de regras e existem apenas alguns campos de dados específicos que você pode obter.
Mas, no caso de web scraping, os clientes não ficam restritos pela taxa de acesso, campos de dados (tudo o que está presente na web, pode ser baixado), opções de customização e manutenção.
P. O que é web scraping em R?
A. Semelhante ao Python , o R (uma linguagem usada para análise estatística) também pode ser usado para coletar dados da web. Observe que rvest é um pacote popular para o ecossistema R
No entanto, não é tão poderoso quanto Python ou Ruby para web scraping.
P. Por que o web scraping é importante?
R. A raspagem da Web é importante, pois permite que empresas e pessoas em todo o mundo acessem os dados da Web, que é o maior e abrangente repositório de dados até hoje. Mencionamos vários casos de uso em uma pergunta anterior.
Confira a página de estudo de caso para saber mais.
P. Como funciona a raspagem da web?
A. Web scraping, em geral, opera com várias etapas. Aqui estão as etapas que o PromptCloud segue em alto nível:
- Semeadura – É um procedimento de passagem de árvore, em que o rastreador primeiro passa pela URL de semente ou pela URL base e, em seguida, procura a próxima URL nos dados que são buscados na URL de semente e assim por diante.
- Definindo a direção do rastreador – Uma vez que os dados da URL de semente foram extraídos e armazenados na memória temporária, os hiperlinks presentes nos dados precisam ser fornecidos ao ponteiro e, em seguida, o sistema deve se concentrar na extração de dados deles.
- Enfileiramento – Extraindo e armazenando todas as páginas que o rastreador analisa, enquanto percorre em um único repositório como arquivos HTML.
- Desduplicação – Remoção de registros ou dados duplicados.
- Normalização – Normalização dos dados com base nos requisitos do cliente (soma, desvio padrão, formatação de moeda, etc.)
- Estruturação – Os dados não estruturados são convertidos em um formato estruturado que pode ser consumido pelo banco de dados.
- Integração de dados – A API REST pode ser usada por clientes para buscar os dados personalizados necessários. O PromptCloud também pode enviar os dados para o FTP, S3 ou qualquer outro armazenamento em nuvem desejado para facilitar a integração dos dados no processo da empresa.
P. Você pode rastrear o Facebook?
R. Há uma grande demanda por dados gerados no Facebook. Ele pode ser usado para qualquer coisa, desde monitoramento de sentimentos e gerenciamento de reputação até descoberta de tendências e previsões do mercado de ações. No entanto, rastrear e extrair dados do Facebook foi proibido por meio do arquivo robots.txt e dos termos de serviço.
Isso conclui a série de perguntas e respostas. Poste suas perguntas nos comentários se quiser discutir mais ou tiver perguntas que não abordamos aqui.