
网络抓取常见问题解答的终极清单 – PromptCloud
已发表: 2019-09-03Web 抓取在过去 10 年中获得了极大的普及,并且仍然继续吸引企业将 Web 数据用于各种业务案例。 电子商务、旅游、工作和研究领域的大多数公司要么建立了内部爬虫系统,要么与专门的网络爬虫服务提供商合作。 在这里,我们提供了一个关于 Web Scraping 的常见问题解答,可以帮助您消除疑虑。
这是一个谷歌趋势搜索,显示出对网络抓取越来越感兴趣:
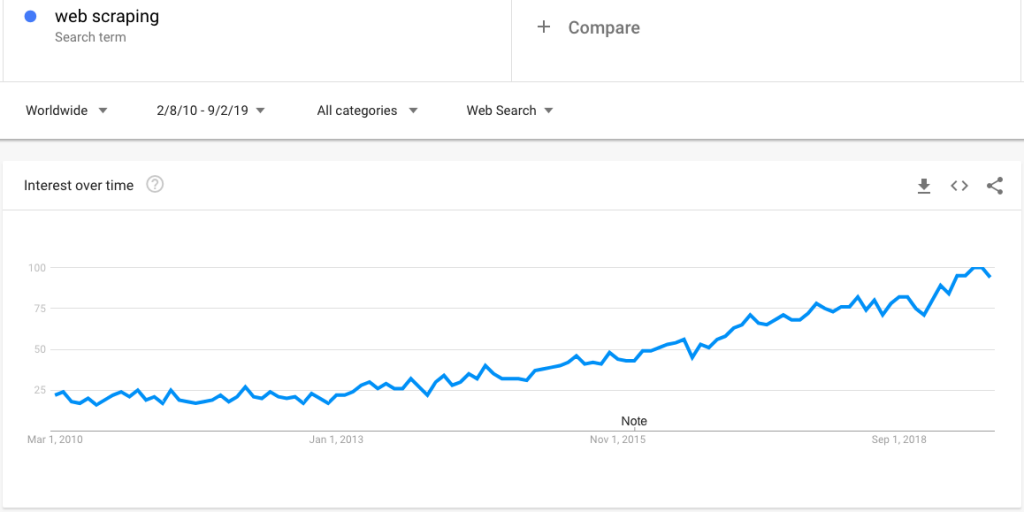
然而,随着人们的兴趣越来越大,关于网络抓取的大量问题也随之而来。 在这篇文章中,我们澄清了一系列广泛的问题:
问:什么是网页抓取?
A. Web Scraping(也称为 Web 数据提取和 Web 收集)是一种通过智能程序从网站收集数据的过程自动化并将其保存为结构化格式以供按需访问的技术。 它还可以编程为以特定频率(如每日、每周和每月)抓取数据,或近乎实时地交付数据。
问:哪个网页抓取最好?
A. 从 Web 中提取数据的方式有多种——从专门的 Web 抓取服务提供商到垂直特定的数据馈送提供商(例如 JobsPikr 用于工作数据)和抓取工具(可以配置为执行简单的一次性 Web 数据收集) .
解决方案和方法的选择实际上取决于具体要求。 作为一般规则,当您需要收集大量网络数据(每周或每天读取数百万条记录)时,请考虑提供网络抓取服务。
问:网络抓取有什么用?
A. 网页抓取有几个用例。 以下是最常见的:
- 产品和价格比较
- 通过评论数据提取进行洞察力挖掘和声誉管理
- 竞争情报
- 产品编目
- 训练机器学习算法
- 某些行业的研究和分析
问:python 中的网页抓取是什么?
A. Web 抓取可以通过不同的编程和脚本语言来完成。 然而,Python 是一个流行的选择,Beautiful Soup 是一个常用的 Python 包,用于解析 HTML 和 XML 文档。

我们已经写了几个关于这个主题的教程——你可以从我们关于网络抓取示例的帖子中了解它们。
Q. 什么是网页抓取?
A. 网页抓取可以被认为是网页抓取的超集——本质上,网页抓取是为了遍历网页的路径,以便可以应用网页抓取的不同步骤来提取和下载数据。
问:什么是网页抓取工具?
A. 这些主要是 DIY 工具,数据收集者需要在其中学习该工具并对其进行配置以提取数据。 这些工具通常适用于来自简单站点的一次性 Web 数据收集项目。 当涉及大量数据提取或目标站点复杂且动态时,它们通常会失败。
问:什么是网络抓取 Reddit?
答:这只是从 Reddit 中提取数据的过程,Reddit 是一个流行的社交平台,用于构建不同类型的社区和论坛。 可以从 Reddit 抓取数据以执行消费者研究、情绪分析、NLP 和机器学习训练。
问:什么是网页抓取服务?
A. Web 抓取服务只是获取数据采集管道的全部所有权的过程。 客户通常会根据目标站点、数据字段、文件格式和提取频率提出要求。 数据供应商准确地根据要求提供 Web 数据,同时负责数据馈送的维护和质量保证。
问:什么是网络抓取 LinkedIn?
答:虽然很多公司都想从 LinkedIn 访问数据,但根据 robots.txt 文件和使用条款,这是法律上不允许的。
问:何时进行网络爬取?
答:作为一家公司,当您需要执行上述任何用例并希望使用全面的替代数据集来扩充您的内部数据时,您应该进行网络爬网。
问:网络抓取合法吗?
A. 只要您遵循 robots.txt 文件中设置的指令、使用条款、访问公共和私人内容的指导方针,这确实是合法的。 了解更多关于合法性的信息。
Q. 网页抓取是数据挖掘吗?
A. 数据挖掘是通过在机器学习、统计和数据库系统的交叉点部署技术,从大规模数据集中发现见解的过程。 因此,通过网络抓取技术提取的数据将经过各种分析处理,从数据获取到洞察力挖掘的完整过程可以称为数据挖掘。
Q. 什么是网页抓取 BeautifulSoup?
A. Beautiful Soup 是一个 Python 库,它允许程序员通过从 HTML 和 XML 文档(包括带有非封闭标签或标签汤和其他格式错误的标记的文档)为网页创建解析树来快速处理 Web 抓取项目。
Beautiful Soup 4 的当前版本兼容 Python 2.7 和 Python 3。
问:如何收集网络数据——网络抓取与 API?
A. API 或应用程序编程接口是允许一个软件与另一个软件对话的中介。 在使用 API 收集数据时,您将受到一组规则的严格约束,并且您只能获取一些特定的数据字段。
但是,在网络抓取的情况下,客户端不受访问速率、数据字段(网络上存在的任何内容都可以下载)、自定义选项和维护的限制。
问:什么是 R 中的网页抓取?
A. 与Python类似, R (一种用于统计分析的语言)也可用于从 Web 收集数据。 请注意, rvest是R生态系统中的一个流行包。
但是,它在网络抓取方面不如Python或Ruby强大。
问:为什么网页抓取很重要?
答:网络抓取很重要,因为它允许全球的企业和个人访问网络数据,这是迄今为止最大和最全面的数据存储库。 我们在前面的问题中提到了几个用例。
查看案例研究页面以了解更多信息。
问:网络抓取如何工作?
A. 一般来说,网页抓取有几个步骤。 以下是 PromptCloud 在高层次上遵循的步骤:
- 播种——这是一个类似树遍历的过程,其中爬虫首先遍历种子 URL 或基本 URL,然后在从种子 URL 获取的数据中查找下一个 URL,依此类推。
- 设置爬虫的方向——一旦从种子 URL 中提取数据并将其存储在临时内存中,数据中存在的超链接需要提供给指针,然后系统应该专注于从中提取数据。
- 排队- 提取和存储爬虫解析的所有页面,同时作为 HTML 文件在单个存储库中遍历。
- 重复数据删除——删除重复的记录或数据。
- 规范化——根据客户要求(总和、标准偏差、货币格式等)对数据进行规范化
- 结构化——非结构化数据被转换为数据库可以使用的结构化格式。
- 数据集成——客户端可以使用 REST API 来获取所需的自定义数据。 PromptCloud 还可以将数据推送到所需的 FTP、S3 或任何其他云存储,以便在公司流程中轻松集成数据。
Q. 你能抓取 Facebook 吗?
A. 对 Facebook 上生成的数据有巨大的需求。 它可用于从情绪监控和声誉管理到趋势发现和股市预测的任何事情。 但是,robots.txt 文件和服务条款已禁止从 Facebook 抓取和提取数据。
问答系列到此结束。 如果您想讨论更多或有我们未在此处解决的问题,请在评论中发表您的问题。