
網頁抓取——數據科學的一個組成部分
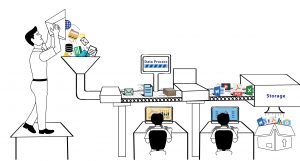
已發表: 2020-02-21Web Scraping 已經成為數據科學的一個組成部分,它本身就是一個生態系統,這個術語最終經常被用作機器學習、人工智能等的替代品。 數據科學生態系統由五個不同的階段組成,它們共同構成了整個生命週期。 每個步驟都包含用於完成該步驟的多個選項-
網頁抓取方法:
數據抓取
- 使用網絡抓取等過程進行數據提取。
- 手動數據輸入。
- 數據採集——通過購買數據集。
- 從物聯網設備捕獲信號。

數據處理
- 數據挖掘。
- 對原始數據進行分類或聚類。
- 數據清洗和規範化。
- 數據建模。
維護
- 數據倉庫和數據湖。
- 構建基礎架構來管理和存儲數據並提供最大的可用性。
交流調查結果
- 使用圖表可視化結果。
- 將調查結果總結成文本報告。
- 商業智能和決策。
分析
- 探索性和驗證性分析。
- 預測分析。
- 回歸。
- 文本挖掘。
- 情緒和定性分析。

正如我們從上面的列表中看到的那樣,如果沒有數據捕獲,數據科學領域就不會發生任何事情,數據捕獲就是擁有您想要在其上運行算法的數據。 這第一步至關重要,是主要的組成部分。 除非您的系統每天都會生成數 TB 的可用數據,否則您可能的選擇是從網絡上抓取數據並將它們存儲在數據庫中,您可以在這些數據庫上運行算法並構建預測引擎。
數據科學家可以使用哪些工具進行網絡抓取?
如果您是數據科學家並且需要通過編寫代碼從互聯網上抓取數據,您可以使用Python編寫代碼。 它不僅具有更輕鬆的學習曲線,而且還允許您通過代碼以自動方式與網站進行交互。 通過您的代碼,您可以與網站進行交互,使網站像使用網絡瀏覽器時一樣接收您的請求。 您可以自動化您的抓取要求,運行及時的腳本,甚至保持穩定的數據源(來自 Twitter 等社交媒體網站)來為您的數據科學項目構建數據集。 以下是 Python 中可用的一些庫,可幫助您解決人們在為項目抓取數據時面臨的不同挑戰 -

要求
當您想通過代碼從網絡上抓取數據時,首要目標是使用代碼訪問網站。 這就是requests庫的用武之地。它是 Python 社區的最愛,因為您可以輕鬆地調用網頁和 API。 這抽象了許多樣板代碼,並使 HTTP 請求比使用內置 URLLib 庫時更簡單。 它包括多種功能,例如瀏覽器風格的 SSL 驗證、無頭請求、自動內容解碼、代理支持等。

美麗的湯
一旦你有一個從網絡上抓取的網頁,你需要從 HTML 頁面上的標籤和屬性中提取數據。 為此,您需要解析 HTML 內容,以便所有數據都可以輕鬆訪問。 BeautifulSoup允許以使導航、搜索和修改簡單的方式輕鬆解析 HTML 和 XML 文檔。 它將文檔視為樹,您可以像導航樹數據結構一樣導航。

機械湯
與更複雜的網站交互時。 可能需要有助於抓取許多網頁的擴展功能。 Mechanical Soup有助於存儲和發送 cookie 的自動化,允許重定向,並且可以跟踪鏈接甚至提交表單。

刮擦
作為最強大的基於 Python 的 Web 抓取庫之一, Scrapy提供了一個開源和協作框架。 它是一個高級抓取庫,用於設置數據挖掘操作、自動爬蟲、定期抓取網絡。 Scrapy 使用一種叫做 Spiders 的東西。 它們是用戶定義的類,用於從網頁中提取信息。

硒
Selenium通常用於測試網頁及其功能,也可用於自動手動任務,例如使用屏幕截圖從網絡上抓取數據、自動點擊和抓取暴露的數據等等。

網頁抓取與其他數據源:
儘管當今有多種數據源可用,但網絡抓取已成為公司採購數據(最終得到處理並轉換為可用信息)的最受歡迎的流程之一。 這背後的最大原因之一是,當您從事數據科學項目時,您希望擁有新的未使用數據,您可以使用這些數據來構建論文或預測結果,這是以前沒有得到的。 儘管數據是新的石油,但數據的價值會隨著時間的推移而降低。 這樣,網絡抓取是天賜之物,因為網絡上的數據每秒都會更新。 它只有在沒有被新數據替換的情況下才有效。 例如,網站上某件商品的價格可能為 1000 美元。
您可以尋求報告以從來源獲取價目表。 當價目表達到 1000 美元時,該商品的價格可能已降至 900 美元。 因此,您根據手頭的價格做出的決定將被證明是錯誤的。 相反,如果您現在抓取某件商品的價格,您將獲得當前的價格。 然後,您可以讓刮板以固定頻率運行,以每 10 秒捕獲一次價格變化。 因此,當您坐在數據中做出決定時,您將擁有更新的和歷史數據,這可以改善結果。 網絡抓取提供了源源不斷的源源不斷的數據。 這是數據科學的主要原因,無論是營銷經理還是研究科學家。
在數據科學中使用抓取數據的挑戰:
雖然您通過網絡抓取獲得的數據是大量且有規律的。 一個重要的事實是,從 Web 中提取的數據通常包含大量不干淨和非結構化的數據。 還可以看到重複數據和未經驗證的數據點的存在。 正確獲取數據源很重要,因此應始終從經過驗證的已知網站抓取數據。 同時,許多數據源用於確認數據。 使用一些智能編碼清理數據並確保不存在重複項。 但是,將非結構化數據轉換為結構化數據仍然是最棘手的網絡抓取問題之一,並且解決方案因情況而異。
另一個主要問題來自安全性、合法性和隱私。 隨著越來越多的國家對數據隱私和數據訪問的限制越來越高,如今越來越多的網站只能通過登錄頁面訪問。 除非您抓取數據,否則可能會受到處罰。 它可以從您的 IP 被阻止到對您提起訴訟開始。
結論:
每一個機會都伴隨著挑戰。 挑戰越大,獎勵越高。 因此,網絡抓取需要集成到您的業務工作流程中,並且數據科學項目需要從該數據中生成可用信息。 但是,如果您需要幫助為您的公司或初創公司從網站上抓取數據,我們 PromptCloud 的團隊會提供一個完全託管的DaaS解決方案,您可以在其中告訴我們要求,我們會設置您的抓取引擎。