
網絡爬取非常規指南
已發表: 2020-03-26雲抓取和網絡爬蟲簡介:
Web Crawling 是公司從具有公開可用信息的各種網站中獲取和提取信息的一種方法。 這是一種以自動方式從網頁中提取數據的技術。 可以加載的腳本可以根據客戶或客戶的要求從多個頁面中提取數據。
網絡抓取或網絡抓取是一種新的前進方式,它改變了全球許多組織的工作方式。 它改變了組織的思考和工作方式。
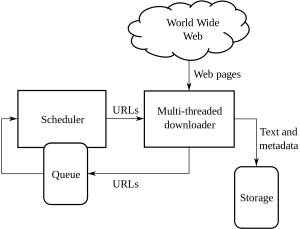
這是處理網絡爬取和抓取及其帶來的複雜性的非常規指南:
1. 選擇正確的工具:
這一步取決於您所從事的項目。 Python 代碼具有一組不同的庫和框架,可用於部署網站爬網。 它具有多種功能,任何人都可以使用它從您選擇的網站中提取信息。
網絡爬蟲中使用的一些 Python 類型是:
美麗湯:
這是一個解析 HTML 和 XML 文檔庫的代碼。 它是解析和製作 HTTP 會話的組合。

刮擦:
這是一個網絡爬蟲和框架,它完全提供了一個抓取工具。
硒:
對於所有繁重的 JSON 渲染文件,這是 python 的最佳用途,因為它可以輕鬆解析所有信息,如果數據量很小,它可以在更快的時間內完成。
這些是用於網絡爬蟲的各種類型的 Python 代碼。

2.動態頁面或代表客戶呈現:
這些天來,網站變得越來越互動,並且盡可能地對用戶友好。 這樣做是為了讓用戶可以快速輕鬆地查看出售給他們的產品。 現代網站使用大量動態和靜態編碼實踐,主要與數據抓取無關。
如何檢測它是動態頁面還是靜態頁面?
您可以檢測頁面使用異步加載。 對於動態頁面,您必須查看頁面源以了解它是動態頁面還是靜態頁面。 如今,大多數網站都是 JavaScript 渲染的,因此有時抓取它們特別困難。
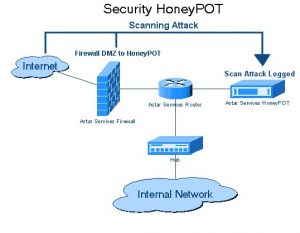
三、蜜罐陷阱
網站開發人員以鏈接的形式在網站上使用蜜罐陷阱。 這些鏈接對網站的典型用戶是不可見的。 當網絡爬蟲試圖從鏈接中提取數據時,網站會檢測到相同的內容並觸發源 IP 地址的阻止。
4. 認證:
當我們從不同的網站爬取數據時,我們需要先對網站進行身份驗證。 只有在這之後我們才能抓取數據。
身份驗證中有兩種類型的輸入:
隱藏輸入:
當提供更多數據時,如 CSRF_TOKEN 提供的用戶名和密碼。
更多標題信息:
這將在發出 POST 請求之前給出一個 post 標頭。 有關同一頭的更多信息,請訪問 Pluralsight。
5. 驗證碼:
這是一種由開發人員編寫的質詢-響應代碼。 這是在用戶訪問某些網站或網站功能之前對用戶進行身份驗證。 當您要抓取或抓取的網站上存在驗證碼時。 由於網絡爬蟲無法跨越網站的驗證碼障礙,設置將失敗。
6. IP 封鎖:
這是各國政府普遍採用的方法。 如果他們發現惡意或危險的東西,那麼他們可能會取消爬蟲的源 IP。 為了避免 IP 的阻塞,開發人員必須在所有平台上創建和輪換爬蟲的身份,並確保它在所有瀏覽器上都能正常工作。

7.網絡爬蟲框架結構的頻繁變化:
HTML 傳遞到特定於內容的頁面。 開發人員試圖堅持相同的結構,但最終對 HTML 頁面的某些部分進行了更改。 這是通過更改網站的 ID 和 HTML 代碼的所有元素。 開發人員還尋求如何改進網站的用戶界面。 當他們想到一個想法時,通常會更改框架以使客戶或客戶在網站上易於使用。 他們還留下了他們生成的虛假數據。 這個過程是為了留下試圖爬取數據的爬蟲。

結論:
這些是各種非常規的網絡爬取方法。 網絡爬取並不是許多人認為的非法過程。 Web 抓取是通過使用 Web 抓取工具或 Web 抓取服務從全球不同網站提取可供公眾使用的數據。 一旦您擁有數據,就可以充分利用數據。 雖然並非每家公司都可以建立網絡抓取團隊,但對於雄心勃勃的數據科學項目來說,使用內部數據可能還不夠。 這就是為什麼我們在 PromptCloud 的團隊不僅為您提供從網絡上抓取的數據,而且為您提供完整的 DaaS 解決方案,您可以在其中滿足您的需求。