
网络爬取非常规指南
已发表: 2020-03-26云抓取和网络爬虫简介:
Web Crawling 是公司从具有公开可用信息的各种网站中获取和提取信息的一种方法。 这是一种以自动方式从网页中提取数据的技术。 可以加载的脚本可以根据客户或客户的要求从多个页面中提取数据。
网络抓取或网络抓取是一种新的前进方式,它改变了全球许多组织的工作方式。 它改变了组织的思考和工作方式。
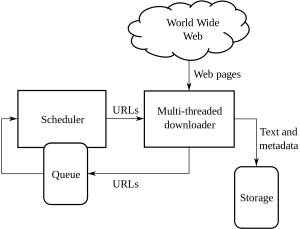
这是处理网络爬取和抓取及其带来的复杂性的非常规指南:
1. 选择正确的工具:
这一步取决于您所从事的项目。 Python 代码具有一组不同的库和框架,可用于部署网站爬网。 它具有多种功能,任何人都可以使用它从您选择的网站中提取信息。
网络爬虫中使用的一些 Python 类型是:
美丽汤:
这是一个解析 HTML 和 XML 文档库的代码。 它是解析和制作 HTTP 会话的组合。

刮擦:
这是一个网络爬虫和框架,它完全提供了一个抓取工具。
硒:
对于所有繁重的 JSON 渲染文件,这是 python 的最佳用途,因为它可以轻松解析所有信息,如果数据量很小,它可以在更快的时间内完成。
这些是用于网络爬虫的各种类型的 Python 代码。

2.动态页面或代表客户呈现:
这些天来,网站变得越来越互动,并且尽可能地对用户友好。 这样做是为了让用户可以快速轻松地查看出售给他们的产品。 现代网站使用大量动态和静态编码实践,主要与数据抓取无关。
如何检测它是动态页面还是静态页面?
您可以检测页面使用异步加载。 对于动态页面,您必须查看页面源以了解它是动态页面还是静态页面。 如今,大多数网站都是 JavaScript 渲染的,因此有时抓取它们特别困难。
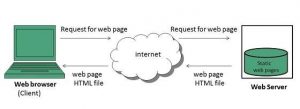
三、蜜罐陷阱
网站开发人员以链接的形式在网站上使用蜜罐陷阱。 这些链接对网站的典型用户是不可见的。 当网络爬虫试图从链接中提取数据时,网站会检测到相同的内容并触发源 IP 地址的阻止。
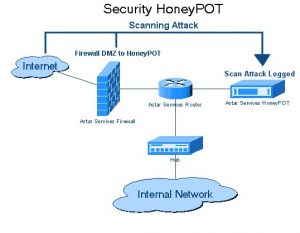
4. 认证:
当我们从不同的网站爬取数据时,我们需要先对网站进行身份验证。 只有在这之后我们才能抓取数据。
身份验证中有两种类型的输入:
隐藏输入:
当提供更多数据时,如 CSRF_TOKEN 提供的用户名和密码。
更多标题信息:
这将在发出 POST 请求之前给出一个 post 标头。 有关同一头的更多信息,请访问 Pluralsight。
5. 验证码:
这是一种由开发人员编写的质询-响应代码。 这是在用户访问某些网站或网站功能之前对用户进行身份验证。 当您要抓取或抓取的网站上存在验证码时。 由于网络爬虫无法跨越网站的验证码障碍,设置将失败。
6. IP 封锁:
这是各国政府普遍采用的方法。 如果他们发现恶意或危险的东西,那么他们可能会取消爬虫的源 IP。 为了避免 IP 的阻塞,开发人员必须在所有平台上创建和轮换爬虫的身份,并确保它在所有浏览器上都能正常工作。

7.网络爬虫框架结构的频繁变化:
HTML 传递到特定于内容的页面。 开发人员试图坚持相同的结构,但最终对 HTML 页面的某些部分进行了更改。 这是通过更改网站的 ID 和 HTML 代码的所有元素。 开发人员还寻求如何改进网站的用户界面。 当他们想到一个想法时,通常会更改框架以使客户或客户在网站上易于使用。 他们还留下了他们生成的虚假数据。 这个过程是为了留下试图爬取数据的爬虫。

结论:
这些是各种非常规的网络爬取方法。 网络爬取并不是许多人认为的非法过程。 Web 抓取是通过使用 Web 抓取工具或 Web 抓取服务从全球不同网站提取可供公众使用的数据。 一旦您拥有数据,就可以充分利用数据。 虽然并非每家公司都可以建立网络抓取团队,但对于雄心勃勃的数据科学项目来说,使用内部数据可能还不够。 这就是为什么我们在 PromptCloud 的团队不仅为您提供从网络上抓取的数据,而且为您提供完整的 DaaS 解决方案,您可以在其中满足您的需求。