
网页抓取——数据科学的一个组成部分
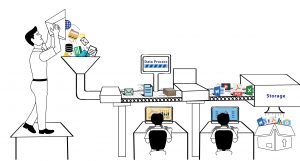
已发表: 2020-02-21Web Scraping 已经成为数据科学的一个组成部分,它本身就是一个生态系统,这个术语最终经常被用作机器学习、人工智能等的替代品。 数据科学生态系统由五个不同的阶段组成,它们共同构成了整个生命周期。 每个步骤都包含用于完成该步骤的多个选项-
网页抓取方法:
数据抓取
- 使用网络抓取等过程进行数据提取。
- 手动数据输入。
- 数据采集——通过购买数据集。
- 从物联网设备捕获信号。

数据处理
- 数据挖掘。
- 对原始数据进行分类或聚类。
- 数据清洗和规范化。
- 数据建模。
维护
- 数据仓库和数据湖。
- 构建基础架构来管理和存储数据并提供最大的可用性。
交流调查结果
- 使用图表可视化结果。
- 将调查结果总结成文本报告。
- 商业智能和决策。
分析
- 探索性和验证性分析。
- 预测分析。
- 回归。
- 文本挖掘。
- 情绪和定性分析。

正如我们从上面的列表中看到的那样,如果没有数据捕获,数据科学领域就不会发生任何事情,数据捕获就是拥有您想要在其上运行算法的数据。 这第一步至关重要,是主要的组成部分。 除非您的系统每天都会生成数 TB 的可用数据,否则您可能的选择是从网络上抓取数据并将它们存储在数据库中,您可以在这些数据库上运行算法并构建预测引擎。
数据科学家可以使用哪些工具进行网络抓取?
如果您是数据科学家并且需要通过编写代码从互联网上抓取数据,您可以使用Python编写代码。 它不仅具有更轻松的学习曲线,而且还允许您通过代码以自动方式与网站进行交互。 通过您的代码,您可以与网站进行交互,使网站像使用网络浏览器时一样接收您的请求。 您可以自动化您的抓取要求,运行及时的脚本,甚至保持稳定的数据源(来自 Twitter 等社交媒体网站)来为您的数据科学项目构建数据集。 以下是 Python 中可用的一些库,可帮助您解决人们在为项目抓取数据时面临的不同挑战 -

要求
当您想通过代码从网络上抓取数据时,首要目标是使用代码访问网站。 这就是requests库的用武之地。它是 Python 社区的最爱,因为您可以轻松地调用网页和 API。 这抽象了许多样板代码,并使 HTTP 请求比使用内置 URLLib 库时更简单。 它包括多种功能,例如浏览器风格的 SSL 验证、无头请求、自动内容解码、代理支持等。

美丽的汤
一旦你有一个从网络上抓取的网页,你需要从 HTML 页面上的标签和属性中提取数据。 为此,您需要解析 HTML 内容,以便所有数据都可以轻松访问。 BeautifulSoup允许以使导航、搜索和修改简单的方式轻松解析 HTML 和 XML 文档。 它将文档视为树,您可以像导航树数据结构一样导航。

机械汤
与更复杂的网站交互时。 可能需要有助于抓取许多网页的扩展功能。 Mechanical Soup有助于存储和发送 cookie 的自动化,允许重定向,并且可以跟踪链接甚至提交表单。

刮擦
作为最强大的基于 Python 的 Web 抓取库之一, Scrapy提供了一个开源和协作框架。 它是一个高级抓取库,用于设置数据挖掘操作、自动爬虫、定期抓取网络。 Scrapy 使用一种叫做 Spiders 的东西。 它们是用户定义的类,用于从网页中提取信息。

硒
Selenium通常用于测试网页及其功能,也可用于自动手动任务,例如使用屏幕截图从网络上抓取数据、自动点击和抓取暴露的数据等等。

网页抓取与其他数据源:
尽管当今有多种数据源可用,但网络抓取已成为公司采购数据(最终得到处理并转换为可用信息)的最受欢迎的流程之一。 这背后的最大原因之一是,当您从事数据科学项目时,您希望拥有新的未使用数据,您可以使用这些数据来构建论文或预测结果,这是以前没有得到的。 尽管数据是新的石油,但数据的价值会随着时间的推移而降低。 这样,网络抓取是天赐之物,因为网络上的数据每秒都会更新。 它只有在没有被新数据替换的情况下才有效。 例如,网站上某件商品的价格可能为 1000 美元。
您可以寻求报告以从来源获取价目表。 当价目表达到 1000 美元时,该商品的价格可能已降至 900 美元。 因此,您根据手头的价格做出的决定将被证明是错误的。 相反,如果您现在抓取某件商品的价格,您将获得当前的价格。 然后,您可以让刮板以固定频率运行,以每 10 秒捕获一次价格变化。 因此,当您坐在数据中做出决定时,您将拥有更新的和历史数据,这可以改善结果。 网络抓取提供了源源不断的源源不断的数据。 这是数据科学的主要原因,无论是营销经理还是研究科学家。
在数据科学中使用抓取数据的挑战:
虽然您通过网络抓取获得的数据是大量且有规律的。 一个重要的事实是,从 Web 中提取的数据通常包含大量不干净和非结构化的数据。 还可以看到重复数据和未经验证的数据点的存在。 正确获取数据源很重要,因此应始终从经过验证的已知网站抓取数据。 同时,许多数据源用于确认数据。 使用一些智能编码清理数据并确保不存在重复项。 但是,将非结构化数据转换为结构化数据仍然是最棘手的网络抓取问题之一,并且解决方案因情况而异。
另一个主要问题来自安全性、合法性和隐私。 随着越来越多的国家对数据隐私和数据访问的限制越来越高,如今越来越多的网站只能通过登录页面访问。 除非您抓取数据,否则可能会受到处罚。 它可以从您的 IP 被阻止到对您提起诉讼开始。
结论:
每一个机会都伴随着挑战。 挑战越大,奖励越高。 因此,网络抓取需要集成到您的业务工作流程中,并且数据科学项目需要从该数据中生成可用信息。 但是,如果您需要帮助为您的公司或初创公司从网站上抓取数据,我们 PromptCloud 的团队会提供一个完全托管的DaaS解决方案,您可以在其中告诉我们要求,我们会设置您的抓取引擎。