
Indeksowanie sieci Niekonwencjonalny przewodnik
Opublikowany: 2020-03-26Wprowadzenie do Cloud Scraping i indeksowania sieci:
Indeksowanie sieci to metoda stosowana przez firmy w celu pozyskiwania i wydobywania informacji z różnych witryn internetowych, które zawierają informacje dostępne publicznie. Jest to technika polegająca na automatycznym pobieraniu danych ze stron internetowych. Skrypty, które można załadować, mogą wyodrębnić dane z wielu stron w oparciu o wymagania klienta lub klienta.
Web Crawling lub web scraping to nowa droga do przodu i zmieniła sposób, w jaki działa wiele organizacji na całym świecie. Zmienił sposób myślenia i działania organizacji.
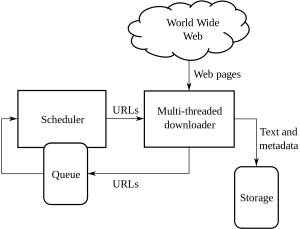
To jest niekonwencjonalny przewodnik dotyczący radzenia sobie z indeksowaniem i skrobaniem sieci oraz złożonością, którą to ujawnia:
1. Wybór odpowiedniego narzędzia:
Ten krok zależy od podjętego przez Ciebie projektu. Kod Pythona zawiera zestaw różnych bibliotek i struktur gotowych do wdrożenia indeksowania witryny. Ma wiele funkcji i jest używany przez każdego do wydobywania informacji z wybranej strony internetowej.
Niektóre typy Pythonów używane w indeksowaniu sieci to:
PięknaZupa:
To jest kod, w którym analizuje bibliotekę dokumentów HTML i XML. Jest to połączenie parsowania i wykonywania sesji HTTP.
Zadrapania:
Jest to przeszukiwanie sieci i framework, który całkowicie zapewnia narzędzie do skrobania.
Selen:
W przypadku wszystkich ciężkich plików renderowanych w formacie JSON jest to najlepsze wykorzystanie Pythona, ponieważ może on z łatwością przeanalizować wszystkie te informacje i zrobić to w krótszym czasie, jeśli rozmiar danych jest niewielki.
Oto różne typy kodów Pythona używanych do przeszukiwania sieci.

2. Strony dynamiczne lub renderowanie w imieniu klienta:
Strony internetowe w dzisiejszych czasach stają się coraz bardziej interaktywne i są jak najbardziej przyjazne dla użytkownika. Ma to na celu umożliwienie użytkownikom szybkiego i łatwego obejrzenia sprzedawanych im produktów. Nowoczesne strony internetowe wykorzystują wiele dynamicznych i statycznych praktyk kodowania, stosowanych głównie niezwiązanych z indeksowaniem danych.

Jak wykryć, czy jest to strona dynamiczna czy statyczna?
Możesz wykryć, że strony używają ładowania asynchronicznego. W przypadku stron dynamicznych musisz wyświetlić źródło strony, aby dowiedzieć się, czy jest to strona dynamiczna, czy statyczna. Obecnie większość stron internetowych jest renderowana w języku JavaScript, więc czasami skrobanie jest szczególnie trudne.
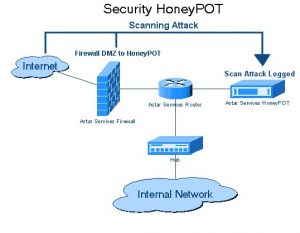
3. Pułapki Honeypot
Twórcy stron internetowych używają pułapek typu honeypot na stronach internetowych w postaci linków. Linki te nie są widoczne dla typowego użytkownika serwisu. Gdy robot sieciowy próbuje wyodrębnić dane z łącza, witryna wykrywa to samo i blokuje źródłowy adres IP.
4. Uwierzytelnianie:
Kiedy indeksujemy dane z różnych witryn, musimy najpierw uzyskać uwierzytelnienie w witrynie. Dopiero po czym możemy zindeksować dane.
W uwierzytelnianiu występują 2 rodzaje wejść:
Ukryte wejścia:
Gdy dostarczono więcej danych, takich jak CSRF_TOKEN, z podaną nazwą użytkownika i hasłem.
Więcej informacji nagłówka:
Spowoduje to wyświetlenie nagłówka wiadomości przed wysłaniem żądania POST. Więcej informacji na ten temat znajdziesz w Pluralsight.
5. Captcha:
Jest to rodzaj kodu typu wyzwanie-odpowiedź napisany przez programistów. Ma to na celu uwierzytelnienie użytkownika, zanim udostępni on określone witryny lub funkcje witryny. Gdy w witrynach, które chcesz zindeksować lub zeskrobać, znajdują się obrazy captcha. Konfiguracja nie powiedzie się, ponieważ roboty sieciowe nie mogą przekroczyć barier captcha na stronach internetowych.
6. Blokowanie IP:
Jest to powszechna metoda stosowana przez rządy wszystkich krajów. Jeśli znajdą coś, co jest złośliwe lub niebezpieczne, mogą anulować źródłowy adres IP robota. Aby uniknąć blokowania adresu IP, programista musi utworzyć i zmienić tożsamość robota indeksującego na wszystkich platformach i upewnić się, że działa we wszystkich przeglądarkach.

7. Częste zmiany w strukturze struktury indeksowania sieci:
HTML przekazywany do stron o określonej treści. Deweloperzy starają się trzymać tej samej struktury, ale w końcu wprowadzają zmiany w niektórych częściach stron HTML. Dzieje się tak poprzez zmianę identyfikatora strony internetowej i wszystkich elementów kodu HTML. Deweloperzy pytają również, jak ulepszyć interfejs użytkownika serwisu. Kiedy trafiają na pomysł, framework zwykle ulega zmianie, aby zapewnić klientowi lub klientowi łatwość korzystania z witryny. Pozostawiają również wygenerowane przez siebie fałszywe dane. Ten proces polega na pozostawieniu robotów indeksujących, które próbują zindeksować swoje dane.

Wniosek:
Oto różne niekonwencjonalne metody indeksowania sieci. Indeksowanie sieci nie jest nielegalnym procesem, jak wielu uważa. Indeksowanie sieci to wyodrębnianie danych, które są dostępne dla ogółu społeczeństwa z różnych witryn na całym świecie za pomocą narzędzia do zgarniania sieci lub usługi zgarniania sieci. Maksymalne wykorzystanie danych jest możliwe, gdy masz je przy sobie. Podczas gdy budowanie zespołu web scrapingu może nie być możliwe dla każdej firmy, a wykorzystanie danych wewnętrznych może nie wystarczyć do ambitnego projektu data science. To jest powód, dla którego nasz zespół w PromptCloud oferuje nie tylko dane zeskrobane z sieci, ale także kompleksowe rozwiązanie DaaS, w którym zasilasz swoje wymagania.