
ウェブクロール型破りなガイド
公開: 2020-03-26クラウド スクレイピングと Web クロールの概要:
Web クロールは、公開されている情報を含むさまざまな Web サイトから情報を入手して抽出するために企業が行う方法です。 Webページから自動でデータを抽出する技術です。 ロードできるスクリプトは、クライアントまたは顧客の要件に基づいて、複数のページからデータを抽出できます。
Web クロールまたは Web スクレイピングは新しい方法であり、世界中の多くの組織の働き方を変えました。 組織の考え方や働き方が変わりました。
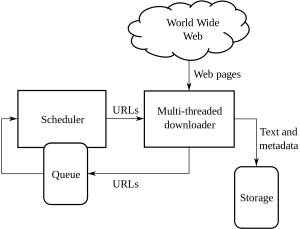
これは、Web クロールとスクレイピング、およびそれがもたらす複雑さに対処するための型破りなガイドです。
1. 適切なツールの選択:
この手順は、担当するプロジェクトによって異なります。 Python コードには、Web サイト クロールの展開に備えた一連のさまざまなライブラリとフレームワークがあります。 複数の機能があり、選択した Web サイトから情報を抽出するために誰でも使用できます。
Web クロールで使用される Python のいくつかのタイプは次のとおりです。
美しいスープ:
これは、HTML および XML ドキュメントのライブラリを解析するコードです。 これは、HTTP セッションの解析と作成を組み合わせたものです。
スクレイピー:
これは Web クローリングおよびフレームワークであり、スクレイピング用のツールを完全に提供します。
セレン:
すべての重い JSON レンダリング ファイルの場合、これは Python の最適な使用方法です。データのサイズが小さい場合は、すべての情報を簡単に解析し、より短時間で実行できるからです。

これらは、Web クロールに使用されるさまざまな種類の Python コードです。

2. クライアントに代わって動的ページまたはレンダリング:
最近の Web サイトはますますインタラクティブになり、可能な限りユーザー フレンドリーになっています。 これは、ユーザーが販売された製品をすばやく簡単に確認できるようにするために行われています。 最新の Web サイトでは、主にデータ クロールに関連しない動的および静的コーディング手法が多数使用されています。
動的ページか静的ページかをどのように検出できますか?
ページが非同期読み込みを使用していることを検出できます。 動的ページの場合、ページ ソースを表示して、動的ページか静的ページかを確認する必要があります。 最近のほとんどの Web サイトは JavaScript でレンダリングされているため、スクレイピングが特に困難な場合があります。
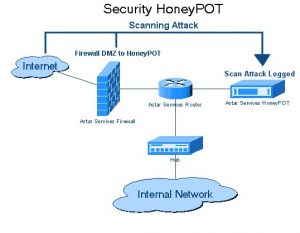
3. ハニーポットの罠
Web サイトの開発者は、Web サイトでハニーポット トラップをリンクの形で使用します。 これらのリンクは、Web サイトの一般的なユーザーには表示されません。 Web クローラーがリンクからデータを抽出しようとすると、Web サイトは同じことを検出し、送信元 IP アドレスのブロックをトリガーします。
4. 認証:
さまざまな Web サイトからデータをクロールする場合、最初に Web サイトへの認証を取得する必要があります。 その後、データをクロールできます。
認証には 2 種類の入力があります。
隠された入力:
ユーザー名とパスワードが提供された CSRF_TOKEN などの追加データが提供された場合。
詳細ヘッダー情報:
これにより、POST リクエストを行う前にポスト ヘッダーが提供されます。 同じ頭の詳細については、Pluralsight を参照してください。
5. キャプチャ:
これは、開発者が作成するチャレンジ/レスポンス コードの一種です。 これは、ユーザーが特定の Web サイトまたは Web サイトの機能へのアクセスを許可する前に、ユーザーを認証するためです。 クロールまたはスクレイピングする Web サイトにキャプチャが存在する場合。 Web クローラーは Web サイトのキャプチャ バリアを越えることができないため、セットアップは失敗します。
6. IP ブロッキング:
これは、すべての国の政府に共通の方法です。 悪意のあるものや危険なものを見つけた場合、クローラーのソース IP をキャンセルする可能性があります。 IP のブロックを回避するために、開発者はすべてのプラットフォームでクローラーの ID を作成およびローテーションし、すべてのブラウザーで動作することを確認する必要があります。

7. Web クロールのフレームワークの構造の頻繁な変更:
コンテンツ固有のページに渡される HTML。 開発者は同じ構造に固執しようとしますが、HTML ページの一部を変更することになります。 これは、Web サイトの ID と HTML コードのすべての要素を変更することによって行われます。 開発者は、Web サイトのユーザー インターフェイスを改善する方法についても探求しています。 彼らがアイデアにたどり着くと、フレームワークは通常、顧客やクライアントが Web サイトで使いやすくなるように変更されます。 また、彼らが生成した偽のデータも残します。 このプロセスは、データをクロールしようとしているクローラーを置き去りにすることです。

結論:
これらは、Web クローリングのさまざまな型にはまらない方法です。 多くの人が考えているように、Web クローリングは違法なプロセスではありません。 Web クロールとは、Web スクレイピング ツールまたは Web スクレイピング サービスを使用して、世界中のさまざまな Web サイトから一般に公開されているデータを抽出することです。 データが手元にあれば、データを最大限に活用できます。 Web スクレイピング チームを構築することは、すべての企業で可能であるとは限らず、野心的なデータ サイエンス プロジェクトでは内部データを使用するだけでは不十分な場合があります。 PromptCloud のチームが Web からスクレイピングしたデータを提供するだけでなく、要件をフィードする本格的な DaaS ソリューションを提供するのはそのためです。