
Web Crawling Una guía no convencional
Publicado: 2020-03-26Introducción a Cloud Scraping y Web Crawling:
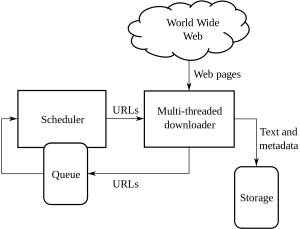
El rastreo web es un método que utilizan las empresas para obtener y extraer información de varios sitios web que tienen información que está disponible públicamente. Es una técnica en la que se extraen datos de páginas web de forma automatizada. Los scripts que se pueden cargar pueden extraer los datos de varias páginas según los requisitos del cliente o del cliente.
Web Crawling o web scraping es una nueva forma de avanzar y ha cambiado la forma en que muchas organizaciones trabajan en todo el mundo. Ha alterado la forma en que las organizaciones piensan y trabajan.
Esta es una guía no convencional para lidiar con el rastreo y el raspado web y las complejidades que plantea:
1. Elegir la herramienta adecuada:
Este paso depende del proyecto emprendido por usted. El código de Python tiene un conjunto de diferentes bibliotecas y marcos listos para la implementación de un rastreo de sitio web. Tiene múltiples funcionalidades y cualquiera lo puede utilizar para extraer información de un sitio web de su elección.
Algunos tipos de pitones que se utilizan en el rastreo web son:
Hermosa Sopa:
Este es un código donde analiza la biblioteca de documentos HTML y XML. Es una combinación de análisis sintáctico y creación de sesiones HTTP.
Scrapy:
Este es un marco y un marco de rastreo web y proporciona una herramienta completa para el raspado.
Selenio:
Para todos los archivos JSON pesados, este es el mejor uso de python, ya que puede analizar toda esa información con facilidad y hacerlo en un período de tiempo más rápido si el tamaño de los datos es pequeño.
Estos son los diversos tipos de códigos de Python que se utilizan para el rastreo web.

2. Páginas Dinámicas o Representación en Nombre del Cliente:
Los sitios web en estos días se están volviendo cada vez más interactivos y son fáciles de usar tanto como sea posible. Esto se hace para que los usuarios tengan una vista rápida y fácil de los productos que se les venden. Los sitios web modernos utilizan muchas prácticas de codificación dinámicas y estáticas que no están relacionadas principalmente con el rastreo de datos.

¿Cómo puedes detectar si es una página dinámica o estática?
Puede detectar que las páginas usan carga asíncrona. Para las páginas dinámicas, debe ver la fuente de la página para saber si es una página dinámica o estática. La mayoría de los sitios web en estos días están renderizados en JavaScript, por lo que el raspado es particularmente difícil a veces.
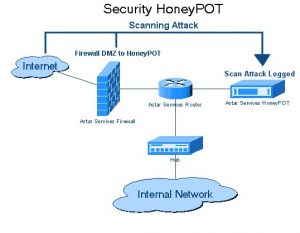
3. Trampas de Honeypot
Los desarrolladores de sitios web utilizan trampas trampa en los sitios web en forma de enlaces. Estos enlaces no son visibles para el usuario típico del sitio web. Cuando un rastreador web intenta extraer datos del enlace, el sitio web lo detecta y activa el bloqueo de la dirección IP de origen.
4. Autenticación:
Cuando rastreamos datos de diferentes sitios web, primero necesitamos obtener una autenticación en el sitio web. Solo después de lo cual podremos rastrear los datos.
Hay 2 tipos de entradas en la autenticación:
Entradas ocultas:
Cuando se proporcionan más datos como CSRF_TOKEN con el nombre de usuario y la contraseña proporcionados.
Más información del encabezado:
Esto le dará un encabezado de publicación antes de realizar la solicitud POST. Para más información sobre el mismo dirigirse a Pluralsight.
5. Captcha:
Este es un tipo de código de desafío-respuesta escrito por desarrolladores. Esto es para autenticar al usuario antes de que dé acceso a ciertos sitios web o características de un sitio web. Cuando los captchas están presentes en los sitios web que desea rastrear o raspar. La configuración fallará ya que los rastreadores web no pueden cruzar las barreras de captcha de los sitios web.
6. Bloqueo de IP:
Este es un método común para los gobiernos de todos los países. Si encuentran algo malicioso o peligroso, pueden cancelar la IP de origen del rastreador. Para evitar el bloqueo de la IP, el desarrollador debe crear y rotar la identidad del rastreador en todas las plataformas y asegurarse de que funcione en todos los navegadores.

7. Cambios frecuentes en la Estructura del Framework de Web Crawling:
HTML pasado a páginas de contenido específico. Los desarrolladores intentan apegarse a la misma estructura pero terminan haciendo cambios en algunas partes de las páginas HTML. Esto es cambiando la ID del sitio web y todos los elementos del código HTML. Los desarrolladores también buscan cómo mejorar la interfaz de usuario del sitio web. Cuando llegan a una idea, el marco generalmente se cambia para brindarle al cliente o al cliente facilidad de uso en el sitio web. También dejan tras de sí datos falsos generados por ellos. Este proceso consiste en dejar atrás a los rastreadores que intentan rastrear sus datos.

Conclusión:
Estos son los diversos métodos no convencionales de rastreo web. El rastreo web no es un proceso ilegal como muchos creen. El rastreo web es la extracción de datos que están disponibles para el público en general desde diferentes sitios web en todo el mundo mediante el uso de una herramienta de raspado web o un servicio de raspado web. Aprovechar al máximo los datos es posible una vez que los tiene con usted. Si bien la creación de su equipo de raspado web puede no ser posible para todas las empresas y el uso de datos internos puede no ser suficiente para un proyecto de ciencia de datos ambicioso. Esa es la razón por la que nuestro equipo en PromptCloud no solo le ofrece datos extraídos de la web, sino también una solución DaaS completa, en la que alimenta sus requisitos.