
Web Crawling Un guide non conventionnel
Publié: 2020-03-26Introduction au Cloud Scraping et au Web Crawling :
Web Crawling est une méthode utilisée par les entreprises pour rechercher et extraire des informations de divers sites Web contenant des informations accessibles au public. Il s'agit d'une technique dans laquelle les données sont extraites de pages Web de manière automatisée. Les scripts peuvent charger peuvent extraire les données de plusieurs pages en fonction des exigences du client ou du client.
L'exploration Web ou le grattage Web est une nouvelle voie à suivre et a changé la façon dont de nombreuses organisations travaillent à travers le monde. Cela a modifié la façon dont les organisations pensent et travaillent.
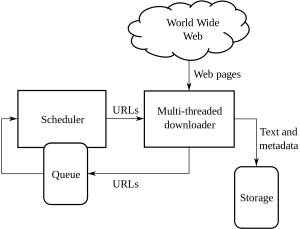
Ceci est un guide non conventionnel pour gérer l'exploration et le grattage Web et les complexités qu'il soulève :
1. Choisir le bon outil :
Cette étape dépend du projet porté par vous. Le code Python dispose d'un ensemble de bibliothèques et de frameworks différents prêts pour le déploiement d'un crawl de site Web. Il a de multiples fonctionnalités et est utilisé par n'importe qui pour extraire des informations d'un site Web de votre choix.
Certains types de Pythons utilisés dans l'exploration Web sont :
Belle soupe :
Il s'agit d'un code où il analyse la bibliothèque de documents HTML et XML. C'est une combinaison d'analyse et de création de sessions HTTP.
Scrapy :
Il s'agit d'un crawling et d'un framework Web et il fournit complètement un outil de grattage.
Sélénium:
Pour tous les fichiers rendus JSON lourds, il s'agit de la meilleure utilisation de python car il peut analyser facilement toutes ces informations et le faire dans un délai plus rapide si la taille des données est petite.
Ce sont les différents types de codes Python utilisés pour l'exploration Web.

2. Pages dynamiques ou rendu au nom du client :
De nos jours, les sites Web deviennent de plus en plus interactifs et conviviaux autant que possible. Ceci est fait pour que les utilisateurs aient un aperçu rapide et facile des produits qui leur sont vendus. Les sites Web modernes utilisent de nombreuses pratiques de codage dynamiques et statiques utilisées principalement sans rapport avec l'exploration de données.

Comment pouvez-vous détecter s'il s'agit d'une page dynamique ou statique ?
Vous pouvez détecter que les pages utilisent le chargement asynchrone. Pour les pages dynamiques, vous devez afficher la source de la page pour savoir s'il s'agit d'une page dynamique ou statique. De nos jours, la plupart des sites Web sont rendus en JavaScript, de sorte qu'il est parfois particulièrement difficile de gratter.
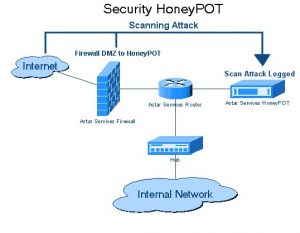
3. Pièges de Honeypot
Les développeurs de sites Web utilisent des pièges à pots de miel sur les sites Web sous la forme de liens. Ces liens ne sont pas visibles pour l'utilisateur typique du site Web. Lorsqu'un robot d'exploration Web tente d'extraire des données du lien, le site Web le détecte et déclenche le blocage de l'adresse IP source.
4. Authentification :
Lorsque nous explorons des données provenant de différents sites Web, nous devons d'abord obtenir une authentification sur le site Web. Seulement après quoi nous pourrons explorer les données.
Il existe 2 types d'entrées dans l'authentification :
Entrées masquées :
Lorsque plus de données sont fournies comme CSRF_TOKEN avec le nom d'utilisateur et le mot de passe fournis.
Plus d'informations d'en-tête :
Cela donnera un en-tête de message avant de faire la demande POST. Pour plus d'informations sur le même rendez-vous sur Pluralsight.
5. Captcha :
Il s'agit d'un type de code défi-réponse écrit par les développeurs. Il s'agit d'authentifier l'utilisateur avant qu'il ne donne accès à certains sites Web ou fonctionnalités d'un site Web. Lorsque des captchas sont présents sur les sites Web que vous souhaitez crawler ou gratter. La configuration échouera car les robots d'exploration Web ne peuvent pas franchir les barrières captcha des sites Web.
6. Blocage IP :
Il s'agit d'une méthode commune aux gouvernements de tous les pays. S'ils trouvent quelque chose de malveillant ou de dangereux, ils peuvent annuler l'adresse IP source du robot d'exploration. Pour éviter le blocage de l'adresse IP, le développeur doit créer et faire pivoter l'identité du robot d'exploration sur toutes les plates-formes et s'assurer qu'il fonctionne sur tous les navigateurs.

7. Changements fréquents dans la Structure du Framework de Web Crawling :
HTML passé dans des pages spécifiques au contenu. Les développeurs essaient de s'en tenir à la même structure mais finissent par apporter des modifications à certaines parties des pages HTML. C'est en changeant l'ID du site Web et tous les éléments du code HTML. Les développeurs cherchent également à améliorer l'interface utilisateur du site Web. Lorsqu'ils atterrissent sur une idée, le cadre est généralement modifié pour donner au client ou au client une facilité d'utilisation sur le site Web. Ils laissent également de fausses données générées par eux. Ce processus consiste à laisser derrière les robots qui tentent d'explorer leurs données.

Conclusion:
Ce sont les différentes méthodes non conventionnelles d'exploration du Web. L'exploration Web n'est pas un processus illégal comme beaucoup le pensent. L'exploration Web est l'extraction de données accessibles au grand public à partir de différents sites Web à travers le monde en utilisant un outil de grattage Web ou un service de grattage Web. Tirer le meilleur parti des données est possible une fois que vous les avez avec vous. Bien que la constitution de votre équipe de scraping Web ne soit pas possible pour toutes les entreprises et que l'utilisation de données internes ne soit pas suffisante pour un projet de science des données ambitieux. C'est la raison pour laquelle notre équipe de PromptCloud vous propose non seulement des données extraites du Web, mais également une solution DaaS complète, dans laquelle vous intégrez vos besoins.