
Accesarea cu crawlere web Un ghid neconvențional
Publicat: 2020-03-26Introducere în cloud scraping și crawling web:
Web crawling este o metodă realizată de companii pentru a sursa și extrage informații de pe diverse site-uri web care au informații disponibile public. Este o tehnică prin care datele sunt extrase din pagini web într-un mod automat. Scripturile care se pot încărca pot extrage datele din mai multe pagini în funcție de cerințele clientului sau ale clientului.
Web crawling sau web scraping este o nouă cale de urmat și a schimbat modul în care multe organizații lucrează de pe tot globul. A modificat modul în care organizațiile gândesc și lucrează.
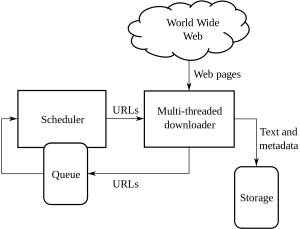
Acesta este un ghid neconvențional pentru a face față cu crawling și răzuire pe web și cu complexitățile pe care le aduce:
1. Alegerea instrumentului potrivit:
Acest pas depinde de proiectul asumat de tine. Codul Python are un set de biblioteci și cadre diferite pregătite pentru implementarea unui acces cu crawlere a site-ului web. Are mai multe funcționalități și este folosit de oricine pentru a extrage informații de pe un site web la alegere.
Unele tipuri de Python care sunt utilizate în crawling-ul web sunt:
BeautifulSup:
Acesta este un cod în care analizează biblioteca de documente HTML și XML. Este o combinație de analiză și creare de sesiuni HTTP.
Scrapy:
Acesta este un cadru de crawling web și oferă complet un instrument pentru răzuire.
Seleniu:
Pentru toate fișierele redate JSON grele, aceasta este cea mai bună utilizare a python, deoarece poate analiza toate acele informații cu ușurință și poate face acest lucru într-un interval de timp mai rapid dacă dimensiunea datelor este mică.
Acestea sunt diferitele tipuri de coduri Python utilizate pentru accesarea cu crawlere pe web.

2. Pagini dinamice sau redare în numele clientului:
Site-urile web în prezent devin din ce în ce mai interactive și sunt cât mai ușor de utilizat. Acest lucru se face astfel încât utilizatorii să aibă o privire rapidă și ușoară asupra produselor vândute. Site-urile web moderne folosesc o mulțime de practici de codare dinamice și statice, utilizate în principal care nu sunt legate de accesarea cu crawlere a datelor.

Cum puteți detecta dacă este o pagină dinamică sau statică?
Puteți detecta paginile care utilizează încărcare asincronă. Pentru paginile dinamice, trebuie să vizualizați sursa paginii pentru a afla dacă este o pagină dinamică sau statică. Cele mai multe site-uri web din zilele noastre sunt redate cu JavaScript, astfel încât răzuirea este deosebit de dificilă uneori.
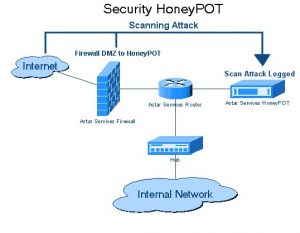
3. Capcane de Honeypot
Dezvoltatorii de site-uri web folosesc capcane honeypot pe site-uri web sub formă de link-uri. Aceste link-uri nu sunt vizibile pentru utilizatorul obișnuit al site-ului. Când un crawler web încearcă să extragă date din link, site-ul web detectează același lucru și declanșează blocarea adresei IP sursei.
4. Autentificare:
Când accesăm cu crawlere date de pe site-uri web diferite, trebuie să obținem mai întâi o autentificare pe site. Doar după care vom putea să accesăm cu crawlere datele.
Există 2 tipuri de intrări în autentificare:
Intrări ascunse:
Când sunt furnizate mai multe date, cum ar fi CSRF_TOKEN, cu numele de utilizator și parola furnizate.
Mai multe informații despre antet:
Acest lucru va oferi un antet de postare înainte de a face cererea POST. Pentru mai multe informații despre același acces la Pluralsight.
5. Captcha:
Acesta este un tip de cod de răspuns la provocare scris de dezvoltatori. Aceasta este pentru a autentifica utilizatorul înainte ca acesta să dea acces la anumite site-uri web sau caracteristici ale unui site web. Când captch-urile sunt prezente pe site-urile web pe care doriți să le accesați cu crawlere sau să le răzuiți. Configurarea va eșua, deoarece crawlerele web nu pot depăși barierele captcha ale site-urilor web.
6. Blocarea IP:
Aceasta este o metodă comună de către guvernele tuturor țărilor. Dacă găsesc ceva rău intenționat sau ceva periculos, atunci ar putea anula IP-ul sursă al crawler-ului. Pentru a evita blocarea IP-ului, dezvoltatorul trebuie să creeze și să rotească identitatea crawler-ului pe toate platformele și să se asigure că funcționează pe toate browserele.

7. Schimbări frecvente în structura cadrului de crawling pe web:
HTML transmis în pagini specifice conținutului. Dezvoltatorii încearcă să rămână la aceeași structură, dar ajung să facă modificări în unele părți ale paginilor HTML. Aceasta se face prin schimbarea ID-ului site-ului web și a tuturor elementelor codului HTML. Dezvoltatorii caută, de asemenea, cum să îmbunătățească interfața cu utilizatorul a site-ului web. Când ajung la o idee, cadrul este de obicei schimbat pentru a oferi clientului sau clientului ușurință de utilizare pe site. De asemenea, lasă în urmă date false generate de ei. Acest proces este de a lăsa în urmă crawlerele care încearcă să își acceseze cu crawlere datele.

Concluzie:
Acestea sunt diferitele metode neconvenționale de crawling pe web. Accesarea cu crawlere web nu este un proces ilegal așa cum cred mulți. Crawling-ul web este extragerea de date care sunt disponibile publicului larg de pe diferite site-uri web de pe tot globul, fie folosind un instrument de scraping web, fie un serviciu de web scraping. Este posibil să profitați la maximum de date odată ce aveți datele cu dvs. În timp ce construirea echipei dvs. de web scraping ar putea să nu fie posibilă pentru fiecare companie, iar utilizarea datelor interne ar putea să nu fie suficientă pentru un proiect ambițios de știință a datelor. Acesta este motivul pentru care echipa noastră de la PromptCloud nu vă oferă doar date răzuite de pe web, ci și o soluție DaaS completă, în care vă alimentați cerințele.