
Web Crawling Ein unkonventioneller Leitfaden
Veröffentlicht: 2020-03-26Einführung in Cloud Scraping und Web Crawling:
Web Crawling ist eine Methode, die von Unternehmen durchgeführt wird, um Informationen von verschiedenen Websites zu beziehen und zu extrahieren, die Informationen enthalten, die öffentlich verfügbar sind. Es ist eine Technik, bei der Daten automatisiert aus Webseiten extrahiert werden. Die Skripte können geladen werden, um die Daten von mehreren Seiten zu extrahieren, basierend auf den Anforderungen des Kunden oder des Kunden.
Web Crawling oder Web Scraping ist ein neuer Weg nach vorne und hat die Arbeitsweise vieler Organisationen auf der ganzen Welt verändert. Sie hat die Denk- und Arbeitsweise von Organisationen verändert.
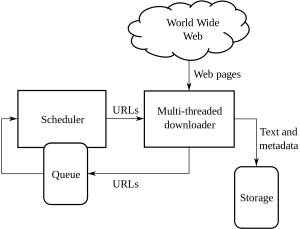
Dies ist ein unkonventioneller Leitfaden zum Umgang mit Web Crawling und Scraping und den damit verbundenen Komplexitäten:
1. Auswahl des richtigen Werkzeugs:
Dieser Schritt hängt von dem von Ihnen in Angriff genommenen Projekt ab. Der Python-Code verfügt über eine Reihe verschiedener Bibliotheken und Frameworks, die für die Bereitstellung eines Website-Crawls bereitstehen. Es hat mehrere Funktionen und wird von jedem verwendet, um Informationen von einer Website Ihrer Wahl zu extrahieren.
Einige Arten von Pythons, die beim Webcrawling verwendet werden, sind:
SchöneSuppe:
Dies ist ein Code, in dem die Bibliothek von HTML- und XML-Dokumenten analysiert wird. Es ist eine Kombination aus Parsen und Erstellen von HTTP-Sitzungen.
Schroff:
Dies ist ein Web-Crawling- und Framework und bietet ein vollständiges Tool zum Scraping.
Selen:
Für all die schweren JSON-gerenderten Dateien ist dies die beste Verwendung von Python, da es all diese Informationen problemlos analysieren kann und dies in einem schnelleren Zeitrahmen tun kann, wenn die Größe der Daten klein ist.
Dies sind die verschiedenen Arten von Python-Codes, die für das Web-Crawling verwendet werden.

2. Dynamische Seiten oder Rendering im Auftrag des Kunden:
Websites werden heutzutage immer interaktiver und so benutzerfreundlich wie möglich. Dies geschieht, damit die Benutzer schnell und einfach einen Blick auf die ihnen verkauften Produkte werfen können. Moderne Websites verwenden viele dynamische und statische Codierungspraktiken, die hauptsächlich nicht mit dem Crawlen von Daten zusammenhängen.

Wie können Sie erkennen, ob es sich um eine dynamische oder statische Seite handelt?
Sie können erkennen, dass die Seiten asynchrones Laden verwenden. Bei dynamischen Seiten müssen Sie die Seitenquelle anzeigen, um herauszufinden, ob es sich um eine dynamische oder statische Seite handelt. Die meisten Websites werden heutzutage mit JavaScript gerendert, sodass das Scraping manchmal besonders schwierig ist.
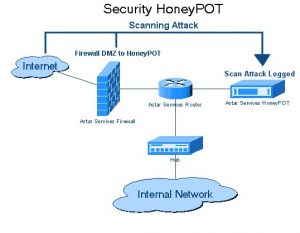
3. Fallen von Honeypot
Website-Entwickler verwenden Honeypot-Fallen auf den Websites in Form von Links. Diese Links sind für den typischen Benutzer der Website nicht sichtbar. Wenn ein Webcrawler versucht, Daten aus dem Link zu extrahieren, erkennt die Website dies und löst die Sperrung der Quell-IP-Adresse aus.
4. Authentifizierung:
Wenn wir Daten von verschiedenen Websites crawlen, müssen wir uns zuerst auf der Website authentifizieren. Erst danach können wir die Daten crawlen.
Es gibt 2 Arten von Eingaben in der Authentifizierung:
Versteckte Eingänge:
Wenn mehr Daten wie CSRF_TOKEN mit Benutzername und Passwort bereitgestellt werden.
Weitere Header-Informationen:
Dadurch wird ein Post-Header ausgegeben, bevor die POST-Anfrage gestellt wird. Weitere Informationen dazu finden Sie auf Pluralsight.
5. Captcha:
Dies ist eine Art Challenge-Response-Code, der von Entwicklern geschrieben wurde. Dies dient dazu, den Benutzer zu authentifizieren, bevor er oder sie Zugriff auf bestimmte Websites oder Funktionen einer Website gewährt. Wenn Captchas auf den Websites vorhanden sind, die Sie crawlen oder scrapen möchten. Die Einrichtung schlägt fehl, da Webcrawler die Captcha-Barrieren von Websites nicht überwinden können.
6. IP-Blockierung:
Dies ist eine gängige Methode der Regierungen aller Länder. Wenn sie etwas Bösartiges oder Gefährliches finden, können sie die Quell-IP des Crawlers löschen. Um das Blockieren der IP zu vermeiden, muss der Entwickler die Identität des Crawlers auf allen Plattformen erstellen und rotieren und sicherstellen, dass er auf allen Browsern funktioniert.

7. Häufige Änderungen in der Struktur des Web-Crawling-Frameworks:
HTML, das an inhaltsspezifische Seiten übergeben wird. Entwickler versuchen, sich an die gleiche Struktur zu halten, nehmen aber am Ende Änderungen an einigen Teilen der HTML-Seiten vor. Dies geschieht durch Ändern der ID der Website und aller Elemente des HTML-Codes. Entwickler suchen auch nach Möglichkeiten, die Benutzeroberfläche der Website zu verbessern. Wenn sie auf eine Idee stoßen, wird das Framework normalerweise geändert, um dem Kunden oder dem Auftraggeber die Nutzung der Website zu erleichtern. Sie hinterlassen auch von ihnen generierte gefälschte Daten. Dieser Prozess soll die Crawler hinter sich lassen, die versuchen, ihre Daten zu crawlen.

Fazit:
Dies sind die verschiedenen unkonventionellen Methoden des Webcrawling. Web-Crawling ist kein illegaler Vorgang, wie viele denken. Web-Crawling ist die Extraktion von Daten, die der Allgemeinheit von verschiedenen Websites auf der ganzen Welt zur Verfügung stehen, indem entweder ein Web-Scraping-Tool oder ein Web-Scraping-Dienst verwendet wird. Das Beste aus Daten herausholen ist möglich, sobald Sie die Daten bei sich haben. Während der Aufbau Ihres Web-Scraping-Teams möglicherweise nicht für jedes Unternehmen möglich ist und die Verwendung interner Daten für ein ehrgeiziges Data-Science-Projekt möglicherweise nicht ausreicht. Aus diesem Grund bietet Ihnen unser Team von PromptCloud nicht nur Daten aus dem Internet, sondern eine vollwertige DaaS-Lösung, in die Sie Ihre Anforderungen einbringen.