
Scansione del Web Una guida non convenzionale
Pubblicato: 2020-03-26Introduzione al cloud scraping e al web crawling:
Il Web Crawling è un metodo utilizzato dalle aziende per reperire ed estrarre informazioni da vari siti Web che dispongono di informazioni disponibili pubblicamente. È una tecnica in cui i dati vengono estratti dalle pagine web in modo automatizzato. Gli script possono essere caricati in grado di estrarre i dati da più pagine in base alle esigenze del cliente o del cliente.
Web Crawling o web scraping è un nuovo modo di procedere e ha cambiato il modo in cui molte organizzazioni lavorano in tutto il mondo. Ha alterato il modo in cui le organizzazioni pensano e lavorano.
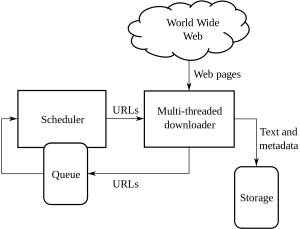
Questa è una guida non convenzionale per gestire la scansione e lo scraping del Web e le complessità che ne derivano:
1. Scegliere lo strumento giusto:
Questo passaggio dipende dal progetto che hai intrapreso. Il codice Python ha un insieme di diverse librerie e framework pronti per l'implementazione di una scansione di un sito web. Ha molteplici funzionalità e viene utilizzato da chiunque per estrarre informazioni da un sito Web di tua scelta.
Alcuni tipi di Python utilizzati nella scansione del Web sono:
Bella zuppa:
Questo è un codice in cui analizza la libreria di documenti HTML e XML. È una combinazione di analisi e creazione di sessioni HTTP.
graffiante:
Questo è un framework e una scansione del Web e fornisce completamente uno strumento per lo scraping.
Selenio:
Per tutti i file di rendering JSON pesanti questo è l'uso migliore di Python in quanto può analizzare tutte quelle informazioni con facilità e farlo in un lasso di tempo più rapido se la dimensione dei dati è piccola.
Questi sono i vari tipi di codici Python utilizzati per la scansione del web.

2. Pagine dinamiche o rendering per conto del cliente:
I siti Web in questi giorni stanno diventando sempre più interattivi e sono il più facili da usare possibile. Questo viene fatto in modo che gli utenti abbiano un'occhiata facile e veloce ai prodotti loro venduti. I siti Web moderni utilizzano molte pratiche di codifica dinamiche e statiche utilizzate principalmente non correlate alla scansione dei dati.

Come puoi rilevare se è una pagina dinamica o statica?
È possibile rilevare che le pagine utilizzano il caricamento asincrono. Per le pagine dinamiche, devi visualizzare l'origine della pagina per scoprire se si tratta di una pagina dinamica o statica. La maggior parte dei siti Web al giorno d'oggi sono visualizzati in JavaScript, quindi a volte lo scraping è particolarmente difficile.
3. Trappole di Honeypot
Gli sviluppatori di siti Web utilizzano le trappole honeypot sui siti Web sotto forma di collegamenti. Questi collegamenti non sono visibili all'utente tipico del sito web. Quando un web crawler tenta di estrarre i dati dal collegamento, il sito Web rileva lo stesso e attiva il blocco dell'indirizzo IP di origine.
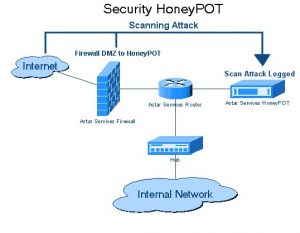
4. Autenticazione:
Quando eseguiamo la scansione dei dati da diversi siti Web, dobbiamo prima ottenere un'autenticazione nel sito Web. Solo dopo di che possiamo essere in grado di eseguire la scansione dei dati.
Ci sono 2 tipi di Input nell'Autenticazione:
Ingressi nascosti:
Quando vengono forniti più dati come CSRF_TOKEN con il nome utente e la password forniti.
Ulteriori informazioni sull'intestazione:
Questo darà un'intestazione del post prima di effettuare la richiesta POST. Per maggiori informazioni sulla stessa testa a Pluralsight.
5. Captcha:
Questo è un tipo di codice challenge-response scritto dagli sviluppatori. Questo serve per autenticare l'utente prima che dia accesso a determinati siti Web o funzionalità di un sito Web. Quando i captcha sono presenti sui siti Web di cui desideri eseguire la scansione o lo scraping. La configurazione fallirà poiché i web crawler non possono superare le barriere captcha dei siti web.
6. Blocco IP:
Questo è un metodo comune ai governi di tutti i paesi. Se trovano qualcosa di dannoso o pericoloso, potrebbero annullare l'IP di origine del crawler. Per evitare il blocco dell'IP, lo sviluppatore deve creare e ruotare l'identità del crawler su tutte le piattaforme e assicurarsi che funzioni su tutti i browser.

7. Cambiamenti frequenti nella struttura del framework del web crawling:
HTML passato a pagine specifiche del contenuto. Gli sviluppatori cercano di attenersi alla stessa struttura ma finiscono per apportare modifiche ad alcune parti delle pagine HTML. Ciò avviene modificando l'ID del sito web e tutti gli elementi del codice HTML. Gli sviluppatori cercano anche come migliorare l'interfaccia utente del sito web. Quando atterrano su un'idea, il framework di solito viene modificato per offrire al cliente o al cliente facilità d'uso sul sito Web. Lasciano anche dati falsi generati da loro. Questo processo serve a lasciarsi alle spalle i crawler che stanno tentando di eseguire la scansione dei propri dati.

Conclusione:
Questi sono i vari metodi non convenzionali di scansione del web. La scansione del Web non è un processo illegale come molti pensano che sia. Il crawling Web è l'estrazione di dati disponibili al pubblico da diversi siti Web in tutto il mondo utilizzando uno strumento di scraping Web o un servizio di scraping Web. Sfruttare al meglio i dati è possibile una volta che hai i dati con te. Sebbene la creazione del tuo team di web scraping potrebbe non essere possibile per tutte le aziende e l'utilizzo dei dati interni potrebbe non essere sufficiente per un ambizioso progetto di scienza dei dati. Questo è il motivo per cui il nostro team di PromptCloud ti offre non solo i dati prelevati dal Web, ma una soluzione DaaS in piena regola, in cui alimenti le tue esigenze.