
웹 크롤링 색다른 가이드
게시 됨: 2020-03-26클라우드 스크래핑 및 웹 크롤링 소개:
웹 크롤링은 공개적으로 사용할 수 있는 정보가 있는 다양한 웹 사이트에서 정보를 찾고 추출하기 위해 회사에서 수행하는 방법입니다. 웹 페이지에서 데이터를 자동으로 추출하는 기술입니다. 스크립트는 클라이언트 또는 고객의 요구 사항에 따라 여러 페이지에서 데이터를 추출할 수 로드할 수 있습니다.
웹 크롤링 또는 웹 스크래핑은 새로운 방법이며 전 세계의 많은 조직이 작업하는 방식을 변경했습니다. 조직이 생각하고 일하는 방식을 바꾸었습니다.
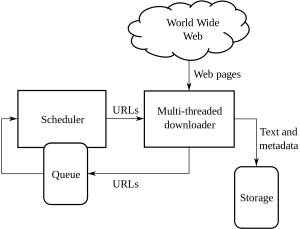
이것은 웹 크롤링 및 스크래핑과 그로 인해 발생하는 복잡성을 처리하기 위한 색다른 가이드입니다.
1. 올바른 도구 선택:
이 단계는 귀하가 수행한 프로젝트에 따라 다릅니다. Python 코드에는 웹 사이트 크롤링 배포에 사용할 수 있는 다양한 라이브러리 및 프레임워크 세트가 있습니다. 그것은 여러 기능을 가지고 있으며 누구나 선택한 웹 사이트에서 정보를 추출하는 데 사용합니다.
웹 크롤링에 사용되는 Python 유형은 다음과 같습니다.
아름다운 수프:
HTML 및 XML 문서 라이브러리를 구문 분석하는 코드입니다. 그것은 구문 분석과 HTTP 세션 만들기의 조합입니다.
스크랩:
이것은 웹 크롤링 및 프레임워크이며 스크래핑을 위한 도구를 완전히 제공합니다.
셀렌:
모든 무거운 JSON 렌더링 파일의 경우 이것은 모든 정보를 쉽게 구문 분석하고 데이터 크기가 작은 경우 더 빠른 시간 프레임에 수행할 수 있으므로 Python을 사용하는 것이 가장 좋습니다.

웹 크롤링에 사용되는 다양한 유형의 Python 코드입니다.

2. 동적 페이지 또는 클라이언트를 대신한 렌더링:
요즘 웹 사이트는 점점 더 상호 작용하고 있으며 가능한 한 사용자 친화적입니다. 이는 사용자가 자신에게 판매된 제품을 빠르고 쉽게 볼 수 있도록 하기 위한 것입니다. 최신 웹 사이트는 주로 데이터 크롤링과 관련이 없는 동적 및 정적 코딩 방식을 많이 사용합니다.
동적 페이지인지 정적 페이지인지 어떻게 알 수 있습니까?
페이지에서 비동기 로딩을 사용하는 것을 감지할 수 있습니다. 동적 페이지의 경우 페이지 소스를 확인하여 동적 페이지인지 정적 페이지인지 확인해야 합니다. 요즘 대부분의 웹 사이트는 JavaScript로 렌더링되므로 스크래핑이 때때로 특히 어렵습니다.
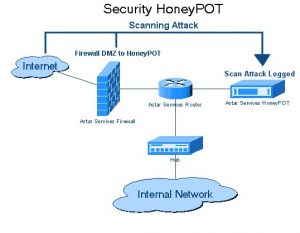
3. 허니팟의 함정
웹사이트 개발자는 링크 형태로 웹사이트에서 허니팟 트랩을 사용합니다. 이러한 링크는 웹사이트의 일반 사용자에게 표시되지 않습니다. 웹 크롤러가 링크에서 데이터를 추출하려고 하면 웹사이트가 이를 감지하고 소스 IP 주소의 차단을 트리거합니다.
4. 인증:
다른 웹사이트에서 데이터를 크롤링할 때 먼저 웹사이트에 대한 인증을 받아야 합니다. 그 후에야 데이터를 크롤링할 수 있습니다.
인증에는 2가지 유형의 입력이 있습니다.
숨겨진 입력:
제공된 사용자 이름과 비밀번호와 함께 CSRF_TOKEN과 같은 더 많은 데이터가 제공된 경우.
추가 헤더 정보:
이것은 POST 요청을 하기 전에 포스트 헤더를 제공할 것입니다. 같은 머리에 대한 자세한 내용은 Pluralsight를 참조하십시오.
5. 보안 문자:
이것은 개발자가 작성한 일종의 챌린지 응답 코드입니다. 특정 웹사이트 또는 웹사이트의 기능에 대한 액세스 권한을 부여하기 전에 사용자를 인증하는 것입니다. 크롤링하거나 스크랩하려는 웹 사이트에 보안 문자가 있는 경우. 웹 크롤러가 웹사이트의 보안 문자 장벽을 넘을 수 없으므로 설정이 실패합니다.
6. IP 차단:
이것은 모든 국가의 정부가 공통적으로 사용하는 방법입니다. 악의적이거나 위험한 것을 발견하면 크롤러의 소스 IP를 취소할 수 있습니다. IP 차단을 피하기 위해 개발자는 모든 플랫폼에서 크롤러의 ID를 생성 및 교체하고 모든 브라우저에서 작동하는지 확인해야 합니다.

7. 웹 크롤링 프레임워크 구조의 빈번한 변경:
콘텐츠별 페이지로 전달된 HTML입니다. 개발자는 동일한 구조를 고수하려고 하지만 결국 HTML 페이지의 일부를 변경하게 됩니다. 이것은 웹 사이트의 ID와 HTML 코드의 모든 요소를 변경하는 것입니다. 개발자들은 또한 웹사이트의 사용자 인터페이스를 개선하는 방법을 모색합니다. 아이디어가 떠올랐을 때 프레임워크는 일반적으로 고객이나 클라이언트가 웹사이트에서 쉽게 사용할 수 있도록 변경됩니다. 그들은 또한 그들에 의해 생성된 가짜 데이터를 남깁니다. 이 프로세스는 데이터를 크롤링하려는 크롤러 뒤에 남겨두기 위한 것입니다.

결론:
이들은 웹 크롤링의 다양한 비 전통적인 방법입니다. 웹 크롤링은 많은 사람들이 생각하는 것처럼 불법적인 프로세스가 아닙니다. 웹 크롤링은 웹 스크래핑 도구 또는 웹 스크래핑 서비스를 사용하여 전 세계 여러 웹 사이트에서 일반 대중이 사용할 수 있는 데이터를 추출하는 것입니다. 데이터를 활용하면 데이터를 최대한 활용할 수 있습니다. 모든 회사에서 웹 스크래핑 팀을 구성하는 것이 불가능할 수 있으며 내부 데이터를 사용하는 것만으로는 야심찬 데이터 과학 프로젝트에 충분하지 않을 수 있습니다. 이것이 PromptCloud의 팀이 웹에서 스크랩한 데이터뿐만 아니라 요구 사항을 제공하는 완전한 DaaS 솔루션을 제공하는 이유입니다.