
机器学习数据标记权威指南
已发表: 2019-11-18大多数机器学习项目的数据都是通过多种来源收集的,例如数据抓取、让人们填写调查表等。通常,这些数据中有很大一部分是未标记或错误标记的。 通过未标记的数据,这里我们指的是没有用标签标记的数据,以指定它们的特征、分类或属性。 但是在继续您的 ML 项目之前,所有这些数据都需要正确标记。 而且这项任务确实需要很多时间。 根据分析公司 Cognilytica 的一份报告,分配给机器学习项目的时间中有多达 25% 用于数据标记。 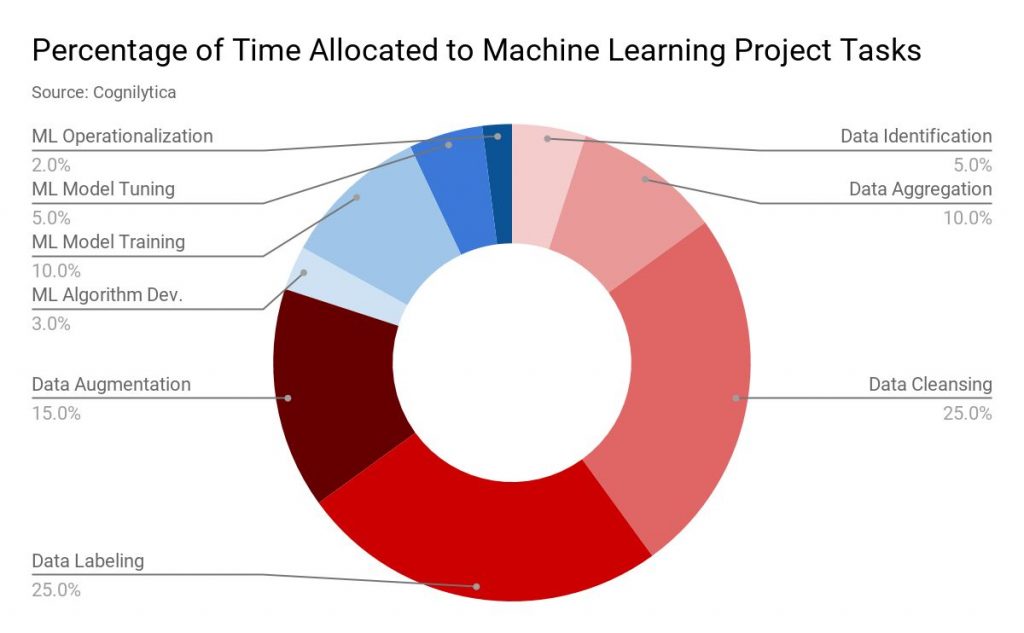 数据标注” 宽度=”1200” 高度=”742” />
数据标注” 宽度=”1200” 高度=”742” />
谁应该执行数据标记?
让团队中的数据科学家来标记原始数据可能不是一个好主意。 一方面,他们还有很多其他工作要做,最好把时间花在算法和提出问题的解决方案上。 相反,您应该有一个单独的团队,该团队应该有两个部分 - 1. 数据标签团队 2. 质量和保证团队。
第一个是不言自明的,但第二个更重要,因为您不希望标记不良的数据破坏您的整个研究项目或扭曲结果。 在检查标记数据时,必须考虑两个因素 -
- 准确性 - 这衡量标签与基本事实的接近程度。 也就是说,所有的马都被标记为马,所有的猫都被标记为猫。
- 质量 - 与大型数据标签团队合作时,这一点非常重要。 当多人对同一数据集的部分进行分类时,他们必须使用相同的标准。 如果有人将 2 BHK 的平面标记为小,将 3 BHK 标记为中,4+ BHK 标记为大,那么所有人都应该遵循相同的规则。
低质量数据的众多问题
首先,当你训练模型时,你会得到一个不正确的模型。 再次验证模型时,您将面临不干净数据的愤怒。 标记数据的人必须同时具备领域知识和上下文知识。 这将帮助您为机器学习项目创建高质量和结构化的数据集。 在某些情况下,两个或多个单词可能意味着同一件事。 如果做标签的人没有上下文,他们可能会在不同的标签下标记项目。 为了获得最佳质量的数据标签,人们应该具有领域知识以及对您的数据所服务的行业的基本了解。

众所周知,机器学习是一个迭代过程。 当您测试模型并从结果中学习时,数据标记可能会发生变化或演变。 因此,对于未来的迭代,您可能需要准备新标签或增强现有标签。 因此,您的数据标签团队应该能够灵活地针对 ML 算法的变化增强标签。
当您有大量数据被标记时,您需要密切关注和维护某些事情。
- 黄金标准——对于每一个标签问题,都有一个正确的答案。 您可以测量正确和不正确的标签,以了解您的数据有多好。
- 样本审查——您可以收集一小部分标记数据并检查其准确性。 预计其准确率将分布在整个数据集本身。
- 共识 – 当在标记特定的可辩论数据时发生辩论时,无论意见是最流行的,都应该被视为共同共识。
数据标记要避免的一些常见和重要错误
在深入研究机器学习项目的数据标签时,很容易忘乎所以并在空中建造城堡。 在开展标签业务时,您必须脚踏实地并现实地思考,拥有一组有限且固定的标签,并遵循一定的规则。
空格、标点符号和区分大小写
在标记数据时,必须小心处理空格和其他一些标点符号。 假设一个人将图像标记为“非洲大象”。 其他人将其标记为“非洲大象”,而另一个人将其标记为“非洲大象”。 现在你明白我们的目标了。 因此,确保您事先确定要使用的标签及其格式非常重要,并且应将添加的任何新标签传达给所有人。 同时,单个空格不应最终变成多个空格,这可以通过一个简单的 Python 脚本来处理。
嵌套标签
另一个可能出现的问题是嵌套标记的场景。 假设您有一句话-“英格兰国王,爱德华三世……”。 现在可以将其标记为 a。 {1:“国王”,2:“英格兰”,3:“爱德华三世”}
虽然它也可能被标记为-
湾。 {1:“英格兰”,2:“国王”,3:“爱德华三世”}
第一个是正确的,因为我们按照它在句子中出现的顺序使用了标签。 但是同样的词可能会以不同的顺序出现,意思是相同的东西,最终得到完全不同的标签顺序。 这就是为什么在所有场景中都使用第二种格式会更好的原因。 这种决定需要对主题和主题都有了解。 使用嵌套标签时,标记数据集的不同人员必须使用相同的格式。
将新标签添加到您的列表中,中途
在您的标签任务中途,您可能会意识到您需要一个新标签,而不是出现在主列表中。 您可以继续将其添加到主列表中,并通知每个人在需要时使用此标签。 这是非常不鼓励的。 原因很简单,你和其他人已经标记的数据也必须重新检查,看看标记是否在已经处理的数据中。 在开始标记任何数据集之前,最好先准备好标签列表。
在您的主列表中有很长的标签列表
增加项目成本和降低数据质量的一个好方法是拥有一长串标签。 假设您将数据标记为爬行动物和哺乳动物。 那应该是简单而快速的。 现在假设您有 100 种爬行动物和哺乳动物的名称,并且您正在使用这些名称进行标记。 标签上肯定有错误。 它也会很慢,一旦出现错误,您的问题只会变得更加复杂。 始终建议保持标签列表较小,并对单独的数据集进行单独的研究。
开始数据标注
在解决与人工智能相关的问题时,仅仅拥有出色的数据科学家和机器学习工程师是不够的。 拥有一个高效的数据收集团队同样重要,因为它拥有一个智能数据清理系统和一些经验丰富的人来标记最终将成为 ML 模型食物的数据。