
La guida definitiva all'etichettatura dei dati per l'apprendimento automatico
Pubblicato: 2019-11-18 I dati per la maggior parte dei progetti di apprendimento automatico vengono raccolti attraverso più fonti come lo scraping dei dati, convincere le persone a compilare i moduli dei sondaggi, ecc. Di solito, un'alta percentuale di questi dati non è etichettata o etichettata in modo errato. Per dati non etichettati, qui ci si riferisce a dati che non sono stati etichettati con etichette che ne specificano le caratteristiche, la classificazione o le proprietà. Ma tutti questi dati devono essere etichettati correttamente prima di procedere con il progetto ML. E questo compito richiede molto tempo. Secondo un rapporto della società di analisi Cognilytica, fino al 25% del tempo assegnato a un progetto di apprendimento automatico viene dedicato all'etichettatura dei dati. 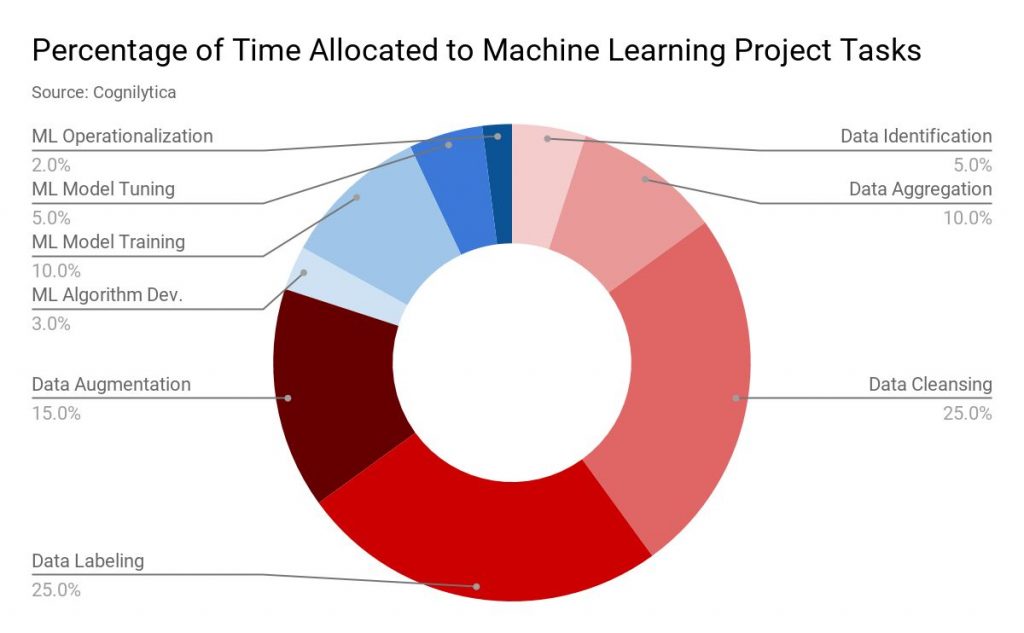 etichettatura dei dati” width=”1200″ height=”742″ />
etichettatura dei dati” width=”1200″ height=”742″ />
Chi dovrebbe eseguire l'etichettatura dei dati?
Far sì che gli scienziati dei dati nel tuo team etichettino i dati grezzi potrebbe non essere una buona idea. Per prima cosa, hanno molto altro lavoro da fare e il loro tempo è speso meglio lavorando su algoritmi e trovando soluzioni ai problemi. Invece, dovresti avere un team separato che dovrebbe avere due parti: 1. Team di etichettatura dei dati 2. Team di qualità e garanzia.
Il primo è autoesplicativo, ma il secondo è ancora più importante poiché non vorresti che dati mal etichettati rovinino l'intero progetto di ricerca o distorcano i risultati. Quando si tratta di mantenere un controllo sui dati etichettati, devono essere presi in considerazione due fattori:
- Precisione: misura quanto è vicina l'etichettatura alla verità di base. Cioè, tutti i cavalli sono contrassegnati come cavalli e tutti i gatti sono etichettati come gatti.
- Qualità: quando si lavora con un grande team di etichettatura dei dati, questo è molto importante. Quando più persone classificano parti dello stesso set di dati, è necessario che tutte utilizzino lo stesso parametro. Se si etichetta un piatto da 2 BHK come piccolo, 3 BHK come medio e 4+ BHK come grande, allora tutti dovrebbero seguire lo stesso.
I numerosi problemi dei dati di bassa qualità
In primo luogo, quando alleni il modello, otterresti un modello errato. Anche in questo caso, durante la convalida del modello, dovresti affrontare l'ira di dati sporchi. Chiunque stia etichettando i dati deve avere sia la conoscenza del dominio che quella contestuale. Ciò ti aiuterebbe a creare set di dati strutturati e di alta qualità per i tuoi progetti di machine learning. In alcuni scenari, due o più parole potrebbero significare la stessa cosa. Se le persone che eseguono l'etichettatura non hanno il contesto, possono etichettare gli elementi con tag diversi. Per un'etichettatura dei dati della migliore qualità, le persone dovrebbero avere una conoscenza del dominio e una conoscenza fondamentale del settore servito dai tuoi dati.
L'apprendimento automatico, come tutti sappiamo, è un processo iterativo. L'etichettatura dei dati può cambiare o evolversi man mano che si testano i modelli e si apprende dai risultati. Quindi, per le iterazioni future, potrebbe essere necessario preparare nuove etichette o migliorare quelle esistenti. Pertanto, il tuo team di etichettatura dei dati dovrebbe avere la flessibilità di migliorare le etichette per le modifiche nell'algoritmo ML.

Quando vengono etichettati molti dati, ci sono alcune cose che dovresti tenere d'occhio e mantenere.
- Gold standard: per ogni domanda sull'etichettatura, c'è una risposta corretta. Puoi misurare le etichette corrette e errate per scoprire quanto sono buoni i tuoi dati.
- Revisione di esempio: è possibile raccogliere un piccolo campione di dati etichettati e verificarne l'accuratezza. La sua percentuale di accuratezza dovrebbe essere distribuita sull'intero set di dati stesso.
- Consenso - Quando c'è un dibattito mentre si etichetta un particolare dato suscettibile di discussione, qualunque opinione sia la più popolare, dovrebbe essere presa come consenso comune.
Alcuni errori comuni e importanti da evitare con l'etichettatura dei dati
Quando si approfondisce l'etichettatura dei dati per un progetto di apprendimento automatico, è molto facile lasciarsi trasportare e costruire castelli nel nulla. Devi tenere i piedi per terra e pensare in modo realistico, avere un set limitato e fisso di etichette e seguire determinate regole quando ti occupi della tua attività di etichettatura.
Spazi bianchi, punteggiatura e distinzione tra maiuscole e minuscole
Quando si etichettano i dati, gli spazi bianchi e alcuni altri segni di punteggiatura devono essere maneggiati con cura. Supponiamo che una persona tagghi un'immagine come "Elefante africano". Qualcun altro lo etichetta come "elefante africano" E ancora un'altra persona lo etichetta come "elefante africano". Ora vedi dove stiamo arrivando. Quindi è molto importante assicurarsi di finalizzare in anticipo i tag che devono essere utilizzati, così come i loro formati e qualsiasi nuovo tag che viene aggiunto dovrebbe essere comunicato a tutti. Allo stesso tempo, i singoli spazi non dovrebbero finire per diventare più di uno spazio, e questo può essere risolto con un semplice script Python.
Tag nidificati
Un altro problema che può sorgere è lo scenario del tagging nidificato. Dì di avere la frase: "Il re d'Inghilterra, Edoardo il terzo...". Ora si può taggarlo come a. {1: "re", 2: "Inghilterra", 3: "Edoardo terzo"}
Sebbene possa anche essere etichettato come-
b. {1: "Inghilterra", 2: "re", 3: "Edoardo terzo"}
Il primo è corretto poiché abbiamo utilizzato i tag nell'ordine in cui sono apparsi nella frase. Ma poi le stesse parole possono apparire in un ordine diverso, a significare la stessa cosa, e finire con un ordine di tag completamente diverso. Ecco perché sarebbe meglio utilizzare il secondo formato in tutti gli scenari. Questo tipo di decisione richiede una comprensione sia dell'argomento che dell'argomento. Persone diverse che etichettano il set di dati devono utilizzare lo stesso formato quando si utilizzano etichette nidificate.
Aggiunta di una nuova etichetta alla tua lista, a metà
A metà della tua attività di etichettatura, potresti renderti conto che avresti bisogno di una nuova etichetta, non presente nell'elenco principale. Potresti continuare ad aggiungerlo all'elenco principale e informare tutti di utilizzare questa etichetta così come e quando richiesto. Questo è altamente sconsigliato. Il semplice motivo è che anche i dati che sono già stati etichettati da te e dagli altri dovrebbero essere ricontrollati, per vedere se l'etichetta si inserisce nei dati già elaborati. È sempre meglio preparare l'elenco delle etichette prima di iniziare con l'etichettatura di qualsiasi set di dati.
Avere una lunga lista di etichette nella tua lista principale
Un ottimo modo per aumentare i costi del progetto e diminuire la qualità dei dati è disporre di un lungo elenco di etichette. Supponi di etichettare i dati come rettili e mammiferi. Dovrebbe essere semplice e veloce. Ora supponi di avere i nomi di 100 rettili e mammiferi e di utilizzarli per l'etichettatura. Ci saranno sicuramente errori nell'etichettatura. Sarà anche lento e i tuoi problemi verranno aggravati solo una volta commessi gli errori. Si consiglia sempre di mantenere l'elenco dei tag piccolo e di condurre studi separati su set di dati separati.
Avvia l'etichettatura dei dati
Non basta avere data scientist e ingegneri di machine learning straordinari quando si affrontano problemi legati all'intelligenza artificiale. È altrettanto importante disporre di un team di raccolta dati efficiente, così come avere un sistema di pulizia dei dati intelligente e alcune mani esperte che etichettano i dati che alla fine saranno il cibo per i modelli ML.