
Panduan Definitif untuk Pelabelan Data untuk Pembelajaran Mesin
Diterbitkan: 2019-11-18 Data untuk sebagian besar proyek pembelajaran mesin dikumpulkan melalui berbagai sumber seperti pengikisan data, meminta orang untuk mengisi formulir survei, dll. Biasanya, persentase tinggi dari data ini tidak diberi label atau salah label. Dengan data yang tidak berlabel, di sini kita mengacu pada data yang belum ditandai dengan label yang menentukan karakteristik, klasifikasi, atau propertinya. Tetapi semua data ini perlu diberi label dengan benar sebelum melanjutkan proyek ML Anda. Dan tugas ini memang memakan banyak waktu. Sesuai laporan oleh perusahaan analitik Cognilytica, sebanyak 25% dari waktu yang dialokasikan untuk proyek pembelajaran mesin dihabiskan untuk pelabelan data. 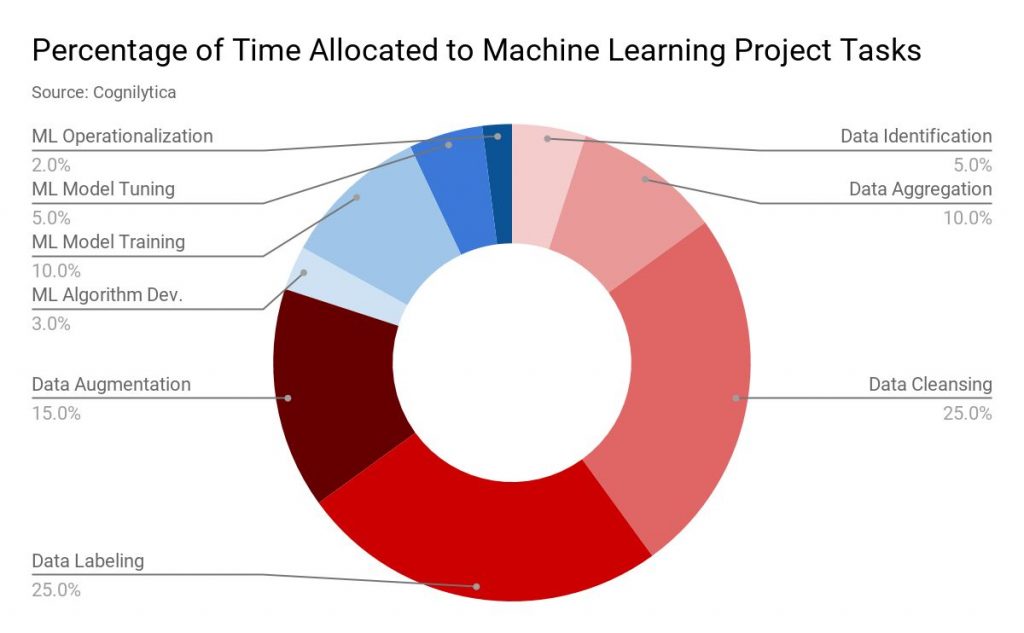 pelabelan data” width=”1200″ height="742″ />
pelabelan data” width=”1200″ height="742″ />
Siapa yang harus melakukan pelabelan data?
Mendapatkan data-scientist di tim Anda untuk melabeli data mentah mungkin bukan ide yang baik. Pertama, mereka memiliki banyak pekerjaan lain yang harus dilakukan, dan waktu mereka paling baik dihabiskan untuk mengerjakan algoritme dan menghasilkan solusi untuk masalah. Sebaliknya, Anda harus memiliki tim terpisah yang harus memiliki dua bagian- 1. Tim Pelabelan Data 2. Tim Kualitas dan Jaminan.
Yang pertama cukup jelas, tetapi yang kedua bahkan lebih penting karena Anda tidak ingin data berlabel buruk merusak seluruh proyek penelitian Anda atau mengacaukan hasilnya. Ketika datang untuk menjaga pemeriksaan pada data berlabel, dua faktor harus diperhitungkan-
- Akurasi- Ini mengukur seberapa dekat pelabelan dengan kebenaran dasar. Artinya, semua kuda ditandai sebagai kuda dan semua kucing diberi label sebagai kucing.
- Kualitas- Saat bekerja dengan tim pelabelan data yang besar, ini sangat penting. Ketika beberapa orang mengklasifikasikan bagian-bagian dari kumpulan data yang sama, mereka semua harus menggunakan tolok ukur yang sama. Jika satu rumah susun 2 BHK diberi label kecil, 3 BHK sedang, dan 4+ BHK besar, maka semua harus mengikuti yang sama.
Banyaknya masalah data berkualitas rendah
Pertama, ketika Anda melatih model, Anda akan mendapatkan model yang salah. Sekali lagi ketika memvalidasi model, Anda akan menghadapi kemarahan data yang tidak bersih. Siapa pun yang melabeli data harus memiliki pengetahuan domain dan kontekstual. Ini akan membantu Anda membuat set data terstruktur dan berkualitas tinggi untuk proyek pembelajaran mesin Anda. Dalam skenario tertentu, dua kata atau lebih mungkin memiliki arti yang sama. Jika orang yang melakukan pelabelan tidak memiliki konteks, mereka dapat memberi label item di bawah tag yang berbeda. Untuk pelabelan data kualitas terbaik, orang harus memiliki pengetahuan domain serta pemahaman mendasar tentang industri yang dilayani oleh data Anda.
Machine Learning, seperti yang kita semua tahu adalah proses berulang. Pelabelan data dapat berubah atau berkembang saat Anda menguji model dan belajar dari hasilnya. Jadi untuk iterasi di masa mendatang, Anda mungkin perlu menyiapkan label baru atau menyempurnakan label yang sudah ada. Oleh karena itu, tim pelabelan data Anda harus memiliki fleksibilitas untuk meningkatkan label untuk perubahan dalam algoritme ML.

Ketika Anda memiliki banyak data yang diberi label, ada hal-hal tertentu yang perlu Anda perhatikan, dan pertahankan.
- Standar emas – Untuk setiap pertanyaan pelabelan, ada jawaban yang benar. Anda dapat mengukur label yang benar dan salah untuk mengetahui seberapa bagus data Anda.
- Tinjauan sampel – Anda dapat mengumpulkan sampel kecil data berlabel dan memeriksa keakuratannya. Persentase akurasinya diharapkan tersebar di seluruh dataset itu sendiri.
- Konsensus – Ketika ada perdebatan saat memberi label pada bagian data tertentu yang dapat diperdebatkan, pendapat apa pun yang paling populer, harus dianggap sebagai konsensus bersama.
Beberapa kesalahan umum dan penting yang harus dihindari dengan pelabelan data
Saat mempelajari pelabelan data untuk proyek pembelajaran mesin, sangat mudah untuk terbawa suasana dan membangun istana di udara tipis. Anda harus tetap berpijak dan berpikir realistis, memiliki label yang terbatas dan tetap dan mengikuti aturan tertentu ketika Anda menjalankan bisnis pelabelan Anda.
WhiteSpaces, tanda baca, dan sensitivitas huruf
Saat melabeli data, spasi, dan beberapa tanda baca lainnya harus ditangani dengan hati-hati. Katakanlah satu orang menandai sebuah gambar sebagai- “Gajah Afrika”. Orang lain menandainya sebagai "Gajah Afrika" Dan orang lain menandainya sebagai "Gajah Afrika". Sekarang Anda melihat di mana kita mendapatkan. Oleh karena itu, sangat penting untuk memastikan bahwa Anda menyelesaikan tag yang akan digunakan, serta formatnya sebelumnya dan setiap tag baru yang ditambahkan harus dikomunikasikan kepada semua. Pada saat yang sama, spasi tunggal tidak boleh berakhir menjadi lebih dari satu spasi, dan ini dapat ditangani dengan skrip Python sederhana.
Tag bersarang
Masalah lain yang dapat muncul adalah skenario penandaan bersarang. Katakanlah Anda memiliki kalimat- "Raja Inggris, Edward yang ketiga ...". Sekarang seseorang dapat menandainya sebagai a. {1: "raja", 2: "Inggris", 3: "Edward yang ketiga"}
Meskipun mungkin juga ditandai sebagai-
b. {1: "Inggris", 2: "raja", 3: "Edward yang ketiga"}
Yang pertama benar karena kami menggunakan tag sesuai urutan kemunculannya dalam kalimat. Tetapi kemudian kata-kata yang sama dapat muncul dalam urutan yang berbeda, artinya sama, dan berakhir dengan urutan tag yang sama sekali berbeda. Inilah sebabnya mengapa akan lebih baik menggunakan format kedua di semua skenario. Keputusan semacam ini membutuhkan pemahaman tentang subjek dan topik. Orang yang berbeda memberi label pada kumpulan data harus menggunakan format yang sama saat menggunakan label bertingkat.
Menambahkan label baru ke daftar Anda, di tengah jalan
Di tengah-tengah tugas pelabelan Anda, Anda mungkin menyadari bahwa Anda akan membutuhkan label baru, tidak ada dalam daftar induk. Anda dapat menambahkannya ke daftar induk dan memberi tahu semua orang untuk menggunakan label ini serta dan bila diperlukan. Ini sangat tidak dianjurkan. Alasan sederhananya adalah bahwa data yang sudah Anda dan yang lainnya harus dilabeli juga harus diperiksa ulang, untuk melihat apakah label tersebut menempel pada data yang sudah diproses. Itu selalu yang terbaik untuk menyiapkan daftar label sebelum memulai dengan pelabelan set data apa pun.
Memiliki daftar label yang panjang di daftar induk Anda
Cara yang bagus untuk meningkatkan biaya proyek dan menurunkan kualitas data adalah dengan memiliki daftar label yang panjang. Katakanlah Anda melabeli data sebagai reptil dan mamalia. Itu harus sederhana dan cepat. Sekarang katakanlah Anda memiliki 100 nama reptil dan mamalia dan Anda menggunakannya untuk pelabelan. Pasti ada kesalahan dalam pelabelan. Ini juga akan lambat dan masalah Anda hanya akan bertambah setelah kesalahan dibuat. Selalu disarankan untuk menjaga daftar tag tetap kecil dan melakukan studi terpisah pada kumpulan data terpisah.
Mulai pelabelan data
Tidaklah cukup memiliki ilmuwan data dan insinyur pembelajaran mesin yang luar biasa saat Anda menangani masalah yang terkait dengan kecerdasan buatan. Sama pentingnya untuk memiliki tim pengumpulan data yang efisien, seperti halnya memiliki sistem pembersihan data yang cerdas dan beberapa tangan berpengalaman yang melabeli data yang pada akhirnya akan menjadi makanan bagi model ML.