
คู่มือขั้นสุดท้ายสำหรับการติดฉลากข้อมูลสำหรับแมชชีนเลิร์นนิง
เผยแพร่แล้ว: 2019-11-18 ข้อมูลสำหรับโปรเจ็กต์แมชชีนเลิร์นนิงส่วนใหญ่จะรวบรวมจากแหล่งข้อมูลต่างๆ เช่น การดึงข้อมูล การรับคนกรอกแบบฟอร์มแบบสำรวจ ฯลฯ โดยปกติ ข้อมูลในเปอร์เซ็นต์ที่สูงนี้จะไม่มีป้ายกำกับหรือติดป้ายกำกับผิด โดยข้อมูลที่ไม่มีป้ายกำกับ ในที่นี้ เราหมายถึงข้อมูลที่ไม่ได้ติดแท็กด้วยป้ายกำกับที่ระบุลักษณะ การจำแนกประเภท หรือคุณสมบัติ แต่ข้อมูลทั้งหมดนี้จะต้องมีป้ายกำกับอย่างถูกต้องก่อนที่จะดำเนินการกับโปรเจ็กต์ ML ของคุณ และงานนี้ใช้เวลามาก ตามรายงานโดยบริษัทวิเคราะห์ Cognilytica มากถึง 25% ของเวลาที่จัดสรรให้กับโปรเจ็กต์แมชชีนเลิร์นนิงถูกใช้ไปในการติดฉลากข้อมูล 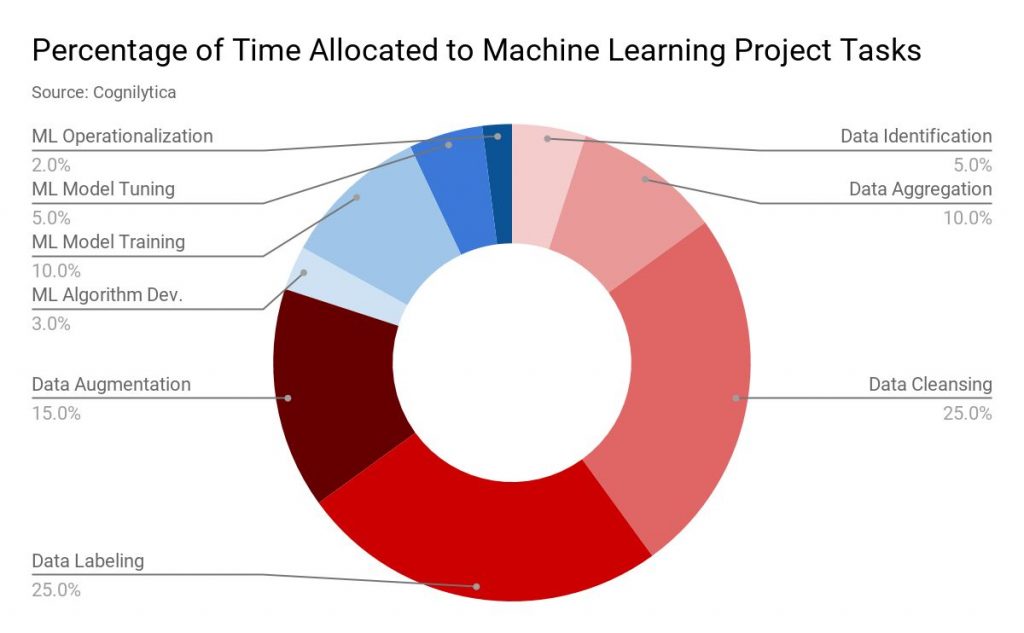 การติดฉลากข้อมูล” width=”1200″ height=”742″ />
การติดฉลากข้อมูล” width=”1200″ height=”742″ />
ใครควรทำการติดฉลากข้อมูล?
การให้นักวิทยาศาสตร์ข้อมูลในทีมของคุณติดป้ายกำกับข้อมูลดิบอาจไม่ใช่ความคิดที่ดี ประการแรก พวกเขามีงานอื่นๆ อีกมากที่ต้องทำ และเวลาของพวกเขาถูกใช้ไปอย่างดีที่สุดในการทำงานกับอัลกอริทึมและคิดหาวิธีแก้ไขปัญหา คุณควรมีทีมแยกกันซึ่งควรมีสองส่วนคือ 1. Data Labeling Teaming 2. ทีมคุณภาพและการประกัน
อย่างแรกอธิบายตนเองได้ แต่ข้อที่สองมีความสำคัญมากกว่า เนื่องจากคุณไม่ต้องการให้ข้อมูลที่มีป้ายกำกับไม่ดีมาทำลายโครงการวิจัยทั้งหมดของคุณหรือบิดเบือนผลลัพธ์ เมื่อพูดถึงการตรวจสอบข้อมูลที่ติดฉลาก จะต้องคำนึงถึงสองปัจจัย -
- ความแม่นยำ- นี่เป็นการวัดว่าการติดฉลากนั้นใกล้เคียงกับความจริงจริงเพียงใด กล่าวคือเป็นม้าทุกตัวที่มีเครื่องหมายเป็นม้าและเป็นแมวทุกตัวที่มีป้ายกำกับว่าเป็นแมว
- คุณภาพ- เมื่อทำงานกับทีมการติดฉลากข้อมูลขนาดใหญ่ สิ่งนี้สำคัญมาก เมื่อหลายคนกำลังจัดประเภทส่วนต่างๆ ของชุดข้อมูลเดียวกัน ทุกคนจะต้องใช้ปทัฏฐานเดียวกัน หากคนหนึ่งระบุว่าแฟลต 2 BHK มีขนาดเล็ก 3 BHK เป็นขนาดกลางและ 4+ BHK เป็นขนาดใหญ่ ทั้งหมดควรเป็นไปตามเดียวกัน
ปัญหามากมายของข้อมูลคุณภาพต่ำ
อย่างแรก เมื่อคุณฝึกโมเดล คุณจะได้โมเดลที่ไม่ถูกต้อง อีกครั้งเมื่อตรวจสอบความถูกต้องของแบบจำลอง คุณจะต้องเผชิญกับข้อมูลที่ไม่สะอาด ใครก็ตามที่ติดป้ายกำกับข้อมูลจะต้องมีทั้งความรู้ด้านโดเมนและบริบท ซึ่งจะช่วยให้คุณสร้างชุดข้อมูลคุณภาพสูงและมีโครงสร้างสำหรับโปรเจ็กต์แมชชีนเลิร์นนิงของคุณ ในบางสถานการณ์ คำสองคำขึ้นไปอาจหมายถึงสิ่งเดียวกัน หากผู้ทำการติดฉลากไม่มีบริบท พวกเขาอาจติดป้ายรายการภายใต้แท็กที่แตกต่างกัน เพื่อการติดฉลากข้อมูลที่มีคุณภาพดีที่สุด ผู้คนควรมีความรู้เกี่ยวกับโดเมนและความเข้าใจพื้นฐานเกี่ยวกับอุตสาหกรรมที่ข้อมูลของคุณให้บริการ
การเรียนรู้ของเครื่อง อย่างที่เราทุกคนทราบกันดีว่าเป็นกระบวนการที่ทำซ้ำได้ การติดฉลากข้อมูลอาจเปลี่ยนแปลงหรือมีวิวัฒนาการในขณะที่คุณทดสอบแบบจำลองของคุณและเรียนรู้จากผลลัพธ์ของมัน ดังนั้นสำหรับการทำซ้ำในอนาคต คุณอาจต้องเตรียมป้ายกำกับใหม่หรือปรับปรุงป้ายกำกับที่มีอยู่ ดังนั้น ทีมงานการติดฉลากข้อมูลของคุณควรมีความยืดหยุ่นในการปรับปรุงฉลากสำหรับการเปลี่ยนแปลงในอัลกอริธึม ML

เมื่อคุณมีข้อมูลจำนวนมากที่ติดป้ายกำกับ มีบางสิ่งที่คุณจะต้องจับตาดูและรักษาไว้
- มาตรฐานทองคำ – ทุกคำถามเกี่ยวกับการติดฉลาก มีคำตอบที่ถูกต้อง คุณสามารถวัดฉลากที่ถูกต้องและไม่ถูกต้องเพื่อดูว่าข้อมูลของคุณดีแค่ไหน
- การตรวจสอบตัวอย่าง – คุณสามารถรวบรวมตัวอย่างข้อมูลขนาดเล็กที่ติดฉลากและตรวจสอบความถูกต้องได้ คาดว่าเปอร์เซ็นต์ความแม่นยำจะกระจายไปทั่วทั้งชุดข้อมูล
- ความเห็นพ้องต้องกัน – เมื่อมีการอภิปรายในขณะที่ระบุข้อมูลบางส่วนที่สามารถโต้แย้งได้ ไม่ว่าความคิดเห็นใดจะเป็นที่นิยมมากที่สุด ก็ควรถือเป็นฉันทามติร่วมกัน
ข้อผิดพลาดทั่วไปและสำคัญที่ควรหลีกเลี่ยงด้วยการติดฉลากข้อมูล
เมื่อเจาะลึกการติดฉลากข้อมูลสำหรับโปรเจ็กต์แมชชีนเลิร์นนิง เป็นเรื่องง่ายมากที่จะดำเนินการและสร้างปราสาทในที่โล่ง คุณต้องวางเท้าบนพื้นและคิดตามความเป็นจริง มีชุดฉลากที่จำกัดและตายตัว และปฏิบัติตามกฎเกณฑ์บางประการเมื่อคุณทำธุรกิจเกี่ยวกับฉลากของคุณ
WhiteSpaces เครื่องหมายวรรคตอนและความละเอียดอ่อนของตัวพิมพ์
เมื่อติดป้ายกำกับข้อมูล ช่องว่างและเครื่องหมายวรรคตอนอื่นๆ จะต้องได้รับการจัดการอย่างระมัดระวัง สมมติว่ามีคนแท็กรูปภาพเป็น "ช้างแอฟริกา" คนอื่นแท็กเป็น "ช้างแอฟริกา" และอีกคนหนึ่งแท็กเป็น "ช้างแอฟริกา" ตอนนี้คุณเห็นที่เราได้รับ ดังนั้นจึงเป็นเรื่องสำคัญมากที่จะต้องตรวจสอบให้แน่ใจว่าคุณได้สรุปแท็กที่จะใช้ รวมทั้งรูปแบบของแท็กไว้ล่วงหน้าและควรแจ้งแท็กใหม่ที่เพิ่มเข้ามาให้ทุกคนทราบ ในเวลาเดียวกัน ช่องว่างเดียวไม่ควรกลายเป็นมากกว่าหนึ่งช่องว่าง และสิ่งนี้สามารถจัดการได้ด้วยสคริปต์ Python ทั่วไป
แท็กที่ซ้อนกัน
ปัญหาอีกประการหนึ่งที่สามารถเกิดขึ้นได้คือสถานการณ์ของการแท็กที่ซ้อนกัน สมมติว่าคุณมีประโยค - "ราชาแห่งอังกฤษ เอ็ดเวิร์ดที่สาม ... " ตอนนี้อาจมีคนแท็กเป็น {1: “ราชา” 2: “อังกฤษ” 3: “เอ็ดเวิร์ดที่สาม”}
ในขณะที่มันอาจถูกแท็กเป็น-
ข. {1: “อังกฤษ”, 2: “ราชา”, 3: “เอ็ดเวิร์ดที่สาม”}
อันแรกถูกต้องเพราะเราใช้แท็กในลำดับที่ปรากฏในประโยค แต่แล้วคำเดียวกันก็สามารถปรากฏในลำดับที่แตกต่างกัน ซึ่งหมายถึงสิ่งเดียวกัน และจบลงด้วยลำดับแท็กที่ต่างไปจากเดิมอย่างสิ้นเชิง นี่คือเหตุผลที่จะดีกว่าถ้าใช้รูปแบบที่สองในทุกสถานการณ์ การตัดสินใจประเภทนี้ต้องการความเข้าใจทั้งเรื่องและหัวข้อ บุคคลที่ติดป้ายกำกับชุดข้อมูลต่างกันต้องใช้รูปแบบเดียวกันเมื่อใช้ป้ายกำกับที่ซ้อนกัน
เพิ่มป้ายกำกับใหม่ในรายการของคุณ ตรงกลาง
ระหว่างงานการติดฉลากของคุณ คุณอาจตระหนักว่าคุณจะต้องมีป้ายผนึกใหม่ ไม่ได้อยู่ในรายการหลัก คุณอาจเพิ่มไปยังรายการหลักและแจ้งให้ทุกคนใช้ป้ายกำกับนี้ตลอดจนและเมื่อจำเป็น นี่ท้อแท้มาก เหตุผลง่ายๆ ก็คือ ข้อมูลที่คุณและคนอื่น ๆ ติดป้ายไว้แล้วจะต้องได้รับการตรวจสอบอีกครั้งเช่นกัน เพื่อดูว่าการติดป้ายกำกับนั้นอยู่ในข้อมูลที่ประมวลผลแล้วหรือไม่ วิธีที่ดีที่สุดคือเตรียมรายการป้ายกำกับให้พร้อมก่อนเริ่มการติดป้ายกำกับชุดข้อมูลใดๆ
มีรายการป้ายกำกับมากมายในรายการหลักของคุณ
วิธีที่ยอดเยี่ยมในการเพิ่มต้นทุนโครงการและลดคุณภาพข้อมูลคือการมีรายการป้ายกำกับจำนวนมาก สมมติว่าคุณกำลังติดป้ายกำกับข้อมูลว่าเป็นสัตว์เลื้อยคลานและสัตว์เลี้ยงลูกด้วยนม ที่ควรจะง่ายและรวดเร็ว สมมติว่าคุณมีชื่อสัตว์เลื้อยคลานและสัตว์เลี้ยงลูกด้วยนม 100 ตัว และคุณกำลังใช้ชื่อเหล่านั้นในการติดฉลาก ต้องมีข้อผิดพลาดในการติดฉลาก นอกจากนี้ยังจะช้าและปัญหาของคุณจะได้รับการทบต้นเมื่อเกิดข้อผิดพลาดเท่านั้น ขอแนะนำเสมอให้เก็บรายการแท็กให้เล็กและทำการศึกษาแยกกันในชุดข้อมูลแยกกัน
เริ่มการติดฉลากข้อมูล
ไม่เพียงพอที่จะมีนักวิทยาศาสตร์ข้อมูลที่น่าทึ่งและวิศวกรการเรียนรู้ของเครื่องเมื่อคุณจัดการกับปัญหาที่เกี่ยวข้องกับปัญญาประดิษฐ์ การมีทีมรวบรวมข้อมูลที่มีประสิทธิภาพมีความสำคัญพอๆ กัน เช่นเดียวกับการมีระบบทำความสะอาดข้อมูลอัจฉริยะและมือที่มีประสบการณ์บางส่วนที่ติดฉลากข้อมูลซึ่งท้ายที่สุดแล้วจะกลายเป็นอาหารสำหรับโมเดล ML