
Полное руководство по маркировке данных для машинного обучения
Опубликовано: 2019-11-18 Данные для большинства проектов машинного обучения собираются из нескольких источников, таких как анализ данных, заполнение форм опроса и т. д. Обычно большая часть этих данных не помечена или помечена неправильно. Под немаркированными данными здесь мы подразумеваем данные, которые не были помечены метками, указывающими их характеристики, классификацию или свойства. Но все эти данные необходимо правильно пометить, прежде чем приступить к проекту машинного обучения. И эта задача требует много времени. Согласно отчету аналитической компании Cognilytica, до 25% времени, отведенного на проект машинного обучения, тратится на маркировку данных. 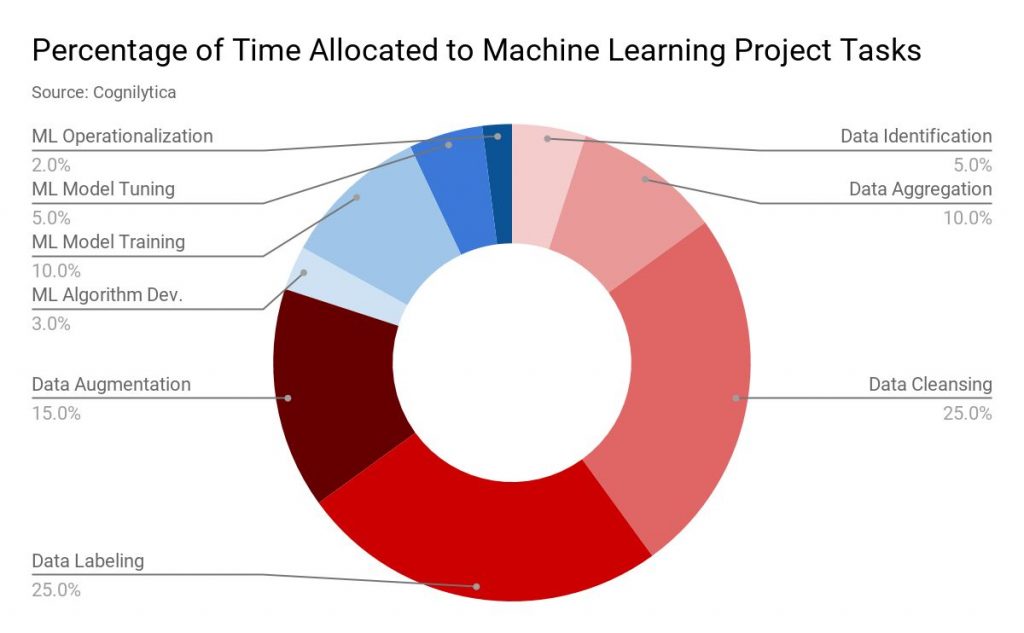 маркировка данных» ширина = «1200» высота = «742» />
маркировка данных» ширина = «1200» высота = «742» />
Кто должен выполнять маркировку данных?
Привлечение специалистов по данным в вашей команде для маркировки необработанных данных может быть плохой идеей. Во-первых, у них есть много другой работы, и их время лучше всего тратить на работу с алгоритмами и поиск решений проблем. Вместо этого у вас должна быть отдельная команда, которая должна состоять из двух частей: 1. Группа по маркировке данных 2. Группа качества и обеспечения.
Первое говорит само за себя, но второе еще важнее, поскольку вы не хотите, чтобы плохо размеченные данные разрушили весь ваш исследовательский проект или исказили результаты. Когда дело доходит до проверки помеченных данных, необходимо учитывать два фактора:
- Точность — измеряет, насколько близка маркировка к истине. То есть все ли лошади помечены как лошади, а все кошки помечены как кошки.
- Качество. При работе с большой командой по маркировке данных это очень важно. Когда несколько человек классифицируют части одного и того же набора данных, необходимо, чтобы все они использовали один и тот же критерий. Если кто-то называет квартиру 2 BHK маленькой, 3 BHK средней и 4+ BHK большой, то все должно следовать одному и тому же.
Многочисленные проблемы некачественных данных
Во-первых, при обучении модели вы получите неправильную модель. Опять же, при проверке модели вы столкнетесь с гневом нечистых данных. Тот, кто маркирует данные, должен иметь как предметные, так и контекстуальные знания. Это поможет вам создавать высококачественные и структурированные наборы данных для ваших проектов машинного обучения. В некоторых сценариях два или более слова могут означать одно и то же. Если люди, выполняющие маркировку, не имеют контекста, они могут маркировать элементы под разными тегами. Для наилучшего качества маркировки данных люди должны обладать знаниями в предметной области, а также фундаментальным пониманием отрасли, которая обслуживается вашими данными.
Машинное обучение, как мы все знаем, представляет собой итеративный процесс. Маркировка данных может меняться или развиваться по мере того, как вы тестируете свои модели и учитесь на их результатах. Поэтому для будущих итераций вам может потребоваться подготовить новые метки или улучшить существующие. Следовательно, ваша команда по маркировке данных должна иметь возможность улучшать метки для изменений в алгоритме машинного обучения.

Когда у вас есть много помеченных данных, есть определенные вещи, за которыми вам нужно следить и поддерживать.
- Золотой стандарт — на каждый вопрос о маркировке есть правильный ответ. Вы можете измерить правильные и неправильные метки, чтобы определить, насколько хороши ваши данные.
- Обзор образца. Вы можете собрать небольшую выборку помеченных данных и проверить ее на точность. Ожидается, что его процент точности будет распределен по всему набору данных.
- Консенсус. Когда возникают дебаты по поводу маркировки конкретной дискуссионной части данных, любое мнение, которое является наиболее популярным, должно восприниматься как общий консенсус.
Некоторые распространенные и важные ошибки, которых следует избегать при маркировке данных
Углубляясь в маркировку данных для проекта машинного обучения, очень легко увлечься и строить замки в воздухе. Вы должны твердо стоять на ногах и мыслить реалистично, иметь ограниченный и фиксированный набор этикеток и следовать определенным правилам, когда занимаетесь этикетированием.
Пробелы, пунктуация и чувствительность к регистру
При маркировке данных с пробелами и некоторыми другими пунктуационными знаками следует обращаться с осторожностью. Скажем, один человек помечает изображение как «африканский слон». Кто-то помечает его как «африканский слон», а кто-то помечает как «африканский слон». Теперь вы видите, куда мы движемся. Следовательно, очень важно убедиться, что вы заранее определили теги, которые будут использоваться, а также их форматы, а любые новые добавленные теги должны быть доведены до сведения всех. В то же время отдельные пробелы не должны становиться более чем одним пробелом, и об этом можно позаботиться с помощью простого скрипта Python.
Вложенные теги
Другая проблема, которая может возникнуть, — это сценарий вложенных тегов. Скажем, у вас есть предложение — «Король Англии, Эдуард третий…». Теперь можно пометить его как a. {1: "король", 2: "Англия", 3: "Эдвард третий"}
Хотя он также может быть помечен как
б. {1: "Англия", 2: "король", 3: "Эдвард третий"}
Первый правильный, так как мы использовали теги в том порядке, в котором они появляются в предложении. Но тогда одни и те же слова могут появляться в другом порядке, означая одно и то же, и заканчиваться совершенно другим порядком тегов. Вот почему было бы лучше использовать второй формат во всех сценариях. Такое решение требует понимания как предмета, так и темы. Разные люди, маркирующие набор данных, должны использовать один и тот же формат при использовании вложенных меток.
Добавление нового ярлыка в ваш список, на полпути
На полпути к выполнению задачи по маркировке вы можете понять, что вам понадобится новая метка, отсутствующая в основном списке. Вы можете добавить его в основной список и сообщить всем использовать этот ярлык, а также и когда это необходимо. Это очень обескураживает. Простая причина в том, что данные, которые уже были помечены вами и другими, также должны быть перепроверены, чтобы увидеть, есть ли метка в уже обработанных данных. Всегда лучше подготовить список меток, прежде чем приступать к маркировке любого набора данных.
Наличие длинного списка ярлыков в мастер-листе
Отличный способ увеличить стоимость проекта и снизить качество данных — иметь длинный список меток. Скажем, вы помечаете данные как рептилий и млекопитающих. Это должно быть просто и быстро. Теперь предположим, что у вас есть названия 100 рептилий и млекопитающих, и вы используете их для обозначения. Обязательно будут ошибки в маркировке. Это также будет медленным, и ваши проблемы будут только усугубляться после совершения ошибок. Всегда рекомендуется сохранять небольшой список тегов и проводить отдельные исследования на отдельных наборах данных.
Начать маркировку данных
Недостаточно иметь замечательных специалистов по данным и инженеров по машинному обучению, когда вы решаете проблемы, связанные с искусственным интеллектом. Иметь эффективную команду по сбору данных так же важно, как иметь интеллектуальную систему очистки данных и несколько опытных рук, маркирующих данные, которые в конечном итоге станут пищей для моделей машинного обучения.