
O guia definitivo para rotulagem de dados para aprendizado de máquina
Publicados: 2019-11-18 Os dados para a maioria dos projetos de aprendizado de máquina são coletados por meio de várias fontes, como coleta de dados, fazer com que as pessoas preencham formulários de pesquisa etc. Normalmente, uma alta porcentagem desses dados não é rotulada ou rotulada incorretamente. Por dados não rotulados, estamos nos referindo a dados que não foram rotulados com rótulos especificando suas características, classificação ou propriedades. Mas todos esses dados precisam ser rotulados corretamente antes de continuar com seu projeto de ML. E essa tarefa leva muito tempo. De acordo com um relatório da empresa de análise Cognilytica, até 25% do tempo alocado para um projeto de aprendizado de máquina é gasto na rotulagem de dados. 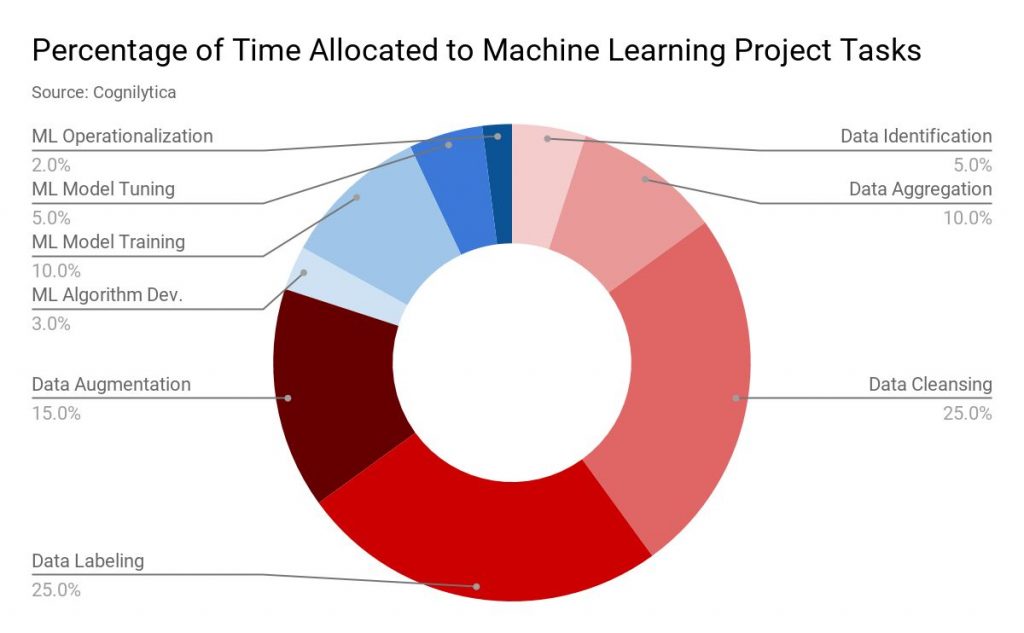 rotulagem de dados” largura=”1200″ altura=”742″ />
rotulagem de dados” largura=”1200″ altura=”742″ />
Quem deve realizar a rotulagem de dados?
Fazer com que cientistas de dados em sua equipe rotulem dados brutos pode não ser uma boa ideia. Por um lado, eles têm muito trabalho a fazer, e seu tempo é melhor gasto trabalhando em algoritmos e encontrando soluções para problemas. Em vez disso, você deve ter uma equipe separada que deve ter duas partes: 1. Equipe de rotulagem de dados 2. Equipe de qualidade e garantia.
O primeiro é autoexplicativo, mas o segundo é ainda mais importante, pois você não gostaria de dados mal rotulados arruinando todo o seu projeto de pesquisa ou distorcendo os resultados. Quando se trata de verificar os dados rotulados, dois fatores devem ser levados em consideração:
- Precisão - Isso mede o quão próximo a rotulagem está da verdade básica. Ou seja, todos os cavalos são marcados como cavalos e todos os gatos são rotulados como gatos.
- Qualidade - Ao trabalhar com uma grande equipe de rotulagem de dados, isso é muito importante. Quando várias pessoas estão classificando partes do mesmo conjunto de dados, é obrigatório que todas elas usem o mesmo critério. Se alguém rotular um apartamento de 2 BHK como pequeno, 3 BHK como médio e 4+ BHK como grande, então todos devem seguir o mesmo.
Os inúmeros problemas de dados de baixa qualidade
Primeiro, ao treinar o modelo, você obteria um modelo incorreto. Novamente, ao validar o modelo, você enfrentaria a ira de dados impuros. Quem está rotulando dados deve ter domínio e conhecimento contextual. Isso ajudaria você a criar conjuntos de dados estruturados e de alta qualidade para seus projetos de machine learning. Em certos cenários, duas ou mais palavras podem significar a mesma coisa. Se as pessoas que fazem a rotulagem não tiverem contexto, elas podem rotular os itens com tags diferentes. Para a rotulagem de dados de melhor qualidade, as pessoas devem ter conhecimento de domínio, bem como uma compreensão fundamental da indústria que é atendida por seus dados.
Machine Learning, como todos sabemos, é um processo iterativo. A rotulagem de dados pode mudar ou evoluir à medida que você testa seus modelos e aprende com seus resultados. Portanto, para futuras iterações, talvez seja necessário preparar novos rótulos ou aprimorar os existentes. Portanto, sua equipe de rotulagem de dados deve ter a flexibilidade de aprimorar rótulos para alterações no algoritmo de ML.

Quando você tem muitos dados sendo rotulados, há certas coisas que você precisa observar e manter.
- Padrão ouro – Para cada pergunta de rotulagem, há uma resposta correta. Você pode medir rótulos corretos e incorretos para descobrir a qualidade dos seus dados.
- Revisão de amostra – Você pode coletar uma pequena amostra de dados rotulados e verificar sua precisão. Espera-se que sua porcentagem de precisão seja espalhada por todo o próprio conjunto de dados.
- Consenso – Quando há um debate ao rotular um determinado dado passível de debate, qualquer que seja a opinião mais popular, deve ser tomada como consenso comum.
Alguns erros comuns e importantes a serem evitados com a rotulagem de dados
Ao se aprofundar na rotulagem de dados para um projeto de aprendizado de máquina, é muito fácil se deixar levar e construir castelos no ar. Você tem que manter o pé no chão e pensar de forma realista, ter um conjunto limitado e fixo de rótulos e seguir certas regras quando você se dedica ao seu negócio de rotulagem.
Espaços em branco, pontuações e distinção entre maiúsculas e minúsculas
Ao rotular dados, espaços em branco e algumas outras pontuações devem ser tratadas com cuidado. Digamos que uma pessoa marque uma imagem como “elefante africano”. Alguém o rotula como “elefante africano” E ainda outra pessoa o rotula como “elefante africano”. Agora você vê onde estamos chegando. Por isso, é muito importante certificar-se de que você finalize as tags que serão usadas, bem como seus formatos de antemão e todas as novas tags que forem adicionadas devem ser comunicadas a todos. Ao mesmo tempo, espaços simples não devem acabar se tornando mais de um espaço, e isso pode ser resolvido por um simples script Python.
Tags aninhadas
Outro problema que pode surgir é o cenário de marcação aninhada. Digamos que você tenha a frase - "O Rei da Inglaterra, Edward o terceiro ...". Agora pode-se marcá-lo como um. {1: “rei”, 2: “Inglaterra”, 3: “Edward o terceiro”}
Embora também possa ser marcado como
b. {1: “Inglaterra”, 2: “rei”, 3: “Edward o terceiro”}
A primeira está correta, pois usamos as tags na ordem em que aparecem na frase. Mas então as mesmas palavras podem aparecer em uma ordem diferente, significando a mesma coisa, e acabar com uma ordem completamente diferente de tags. É por isso que seria melhor usar o segundo formato em todos os cenários. Esse tipo de decisão precisa de uma compreensão tanto do assunto quanto do tópico. Pessoas diferentes que rotulam o conjunto de dados devem usar o mesmo formato ao usar rótulos aninhados.
Adicionando novo marcador à sua lista, no meio do caminho
No meio da tarefa de rotulagem, você pode perceber que precisaria de um novo rótulo, não presente na lista principal. Você pode adicioná-lo à lista principal e informar a todos para usar esse rótulo, bem como e quando necessário. Isso é altamente desencorajado. A razão simples é que os dados que já foram rotulados por você e os outros teriam que ser verificados novamente, para ver se o rótulo está presente nos dados já processados. É sempre melhor preparar a lista de rótulos antes de iniciar a rotulagem de qualquer conjunto de dados.
Ter uma longa lista de rótulos em sua lista mestra
Uma ótima maneira de aumentar os custos do projeto e diminuir a qualidade dos dados é ter uma longa lista de rótulos. Digamos que você esteja rotulando dados como répteis e mamíferos. Isso deve ser simples e rápido. Agora digamos que você tem os nomes de 100 répteis e mamíferos e os está usando para rotular. É provável que haja erros na rotulagem. Também será lento e seus problemas só serão agravados quando os erros forem cometidos. É sempre recomendável manter a lista de tags pequena e realizar estudos separados em conjuntos de dados separados.
Iniciar rotulagem de dados
Não basta ter cientistas de dados e engenheiros de aprendizado de máquina incríveis quando você está lidando com problemas relacionados à inteligência artificial. É tão importante ter uma equipe de coleta de dados eficiente, quanto ter um sistema de limpeza de dados inteligente e algumas mãos experientes rotulando os dados que acabarão sendo o alimento para os modelos de ML.