
Ostateczny przewodnik po etykietowaniu danych w uczeniu maszynowym
Opublikowany: 2019-11-18 Dane dla większości projektów uczenia maszynowego są gromadzone z wielu źródeł, takich jak skrobanie danych, zachęcanie ludzi do wypełniania formularzy ankiet itp. Zwykle duży odsetek tych danych jest nieoznakowanych lub błędnie oznaczonych. Przez dane nieoznakowane mamy na myśli dane, które nie zostały oznaczone etykietami określającymi ich charakterystykę, klasyfikację lub właściwości. Ale wszystkie te dane muszą być odpowiednio oznaczone, zanim przejdziesz do projektu ML. A to zadanie zajmuje dużo czasu. Jak wynika z raportu firmy analitycznej Cognilytica, aż 25% czasu przeznaczonego na projekt uczenia maszynowego spędza się na etykietowaniu danych. 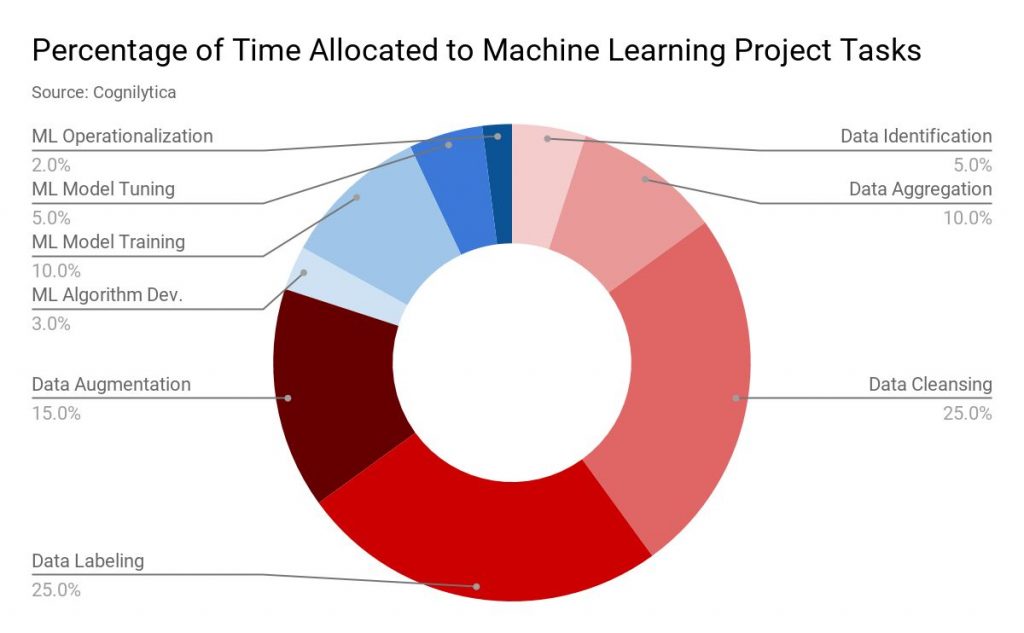 etykietowanie danych” szerokość=”1200″ wysokość=”742″ />
etykietowanie danych” szerokość=”1200″ wysokość=”742″ />
Kto powinien wykonywać etykietowanie danych?
Pozyskiwanie naukowców zajmujących się danymi w zespole do oznaczania nieprzetworzonych danych może nie być dobrym pomysłem. Po pierwsze, mają dużo innej pracy do wykonania, a swój czas najlepiej poświęcić na pracę nad algorytmami i wymyślanie rozwiązań problemów. Zamiast tego powinieneś mieć osobny zespół, który powinien składać się z dwóch części: 1. Zespół ds. Etykietowania danych 2. Zespół ds. Jakości i zapewnienia.
Pierwsza jest oczywista, ale druga jest jeszcze ważniejsza, ponieważ nie chciałbyś, aby źle oznakowane dane zrujnowały cały projekt badawczy lub wypaczył wyniki. Jeśli chodzi o kontrolę oznakowanych danych, należy wziąć pod uwagę dwa czynniki:
- Dokładność — mierzy, jak blisko prawdy jest oznakowanie. Oznacza to, że wszystkie konie są oznaczone jako konie i wszystkie koty są oznaczone jako koty.
- Jakość – podczas pracy z dużym zespołem etykietowania danych jest to bardzo ważne. Gdy wiele osób klasyfikuje części tego samego zbioru danych, konieczne jest, aby wszyscy używali tej samej miary. Jeśli jeden oznaczy mieszkanie 2 BHK jako małe, 3 BHK jako średnie, a 4+ BHK jako duże, to wszystkie powinny postępować tak samo.
Liczne problemy z danymi niskiej jakości
Po pierwsze, kiedy trenujesz model, otrzymujesz niepoprawny model. Ponownie, podczas walidacji modelu, napotkasz gniew nieczystych danych. Ktokolwiek oznacza dane etykietami, musi mieć zarówno wiedzę dziedzinową, jak i kontekstową. Pomoże to w tworzeniu wysokiej jakości uporządkowanych zbiorów danych dla projektów uczenia maszynowego. W niektórych sytuacjach co najmniej dwa słowa mogą oznaczać to samo. Jeśli osoby wykonujące etykietowanie nie mają kontekstu, mogą oznaczać elementy różnymi etykietami. Aby zapewnić najlepszą jakość etykietowania danych, ludzie powinni posiadać wiedzę o domenach, a także podstawową wiedzę na temat branży, której obsługują Twoje dane.
Uczenie maszynowe, jak wszyscy wiemy, jest procesem iteracyjnym. Etykietowanie danych może się zmieniać lub ewoluować w miarę testowania modeli i uczenia się na ich wynikach. Dlatego w przyszłych iteracjach może być konieczne przygotowanie nowych etykiet lub ulepszenie istniejących. W związku z tym Twój zespół etykietowania danych powinien mieć elastyczność w zakresie ulepszania etykiet pod kątem zmian w algorytmie ML.

Kiedy masz dużo danych oznaczonych etykietami, musisz mieć na uwadze i utrzymywać pewne rzeczy.
- Złoty standard — na każde pytanie dotyczące etykietowania istnieje prawidłowa odpowiedź. Możesz zmierzyć prawidłowe i nieprawidłowe etykiety, aby sprawdzić, jak dobre są Twoje dane.
- Przykładowy przegląd — możesz zebrać niewielką próbkę oznaczonych danych i sprawdzić ich dokładność. Oczekuje się, że jego procent dokładności będzie rozłożony na cały sam zestaw danych.
- Konsensus – Kiedy jest debata, podczas której określa się konkretną dyskusyjną część danych, bez względu na to, jaka opinia jest najbardziej popularna, należy traktować ją jako wspólny konsensus.
Niektóre typowe i ważne błędy, których należy unikać przy oznaczaniu danych
Zagłębiając się w etykietowanie danych w projekcie uczenia maszynowego, bardzo łatwo jest dać się ponieść emocjom i budować zamki w powietrzu. Musisz twardo stąpać po ziemi i myśleć realistycznie, mieć ograniczony i ustalony zestaw etykiet oraz przestrzegać pewnych zasad, kiedy zajmujesz się etykietowaniem.
Spacje, znaki interpunkcyjne i rozróżnianie wielkości liter
Podczas etykietowania danych, spacji i niektórych innych znaków interpunkcyjnych należy obchodzić się ostrożnie. Powiedzmy, że jedna osoba oznacza obraz jako- „Słoń afrykański”. Ktoś inny oznacza go jako „afrykański słoń”, a jeszcze inna osoba oznacza go jako „afrykański słoń”. Teraz widzisz, dokąd zmierzamy. Dlatego bardzo ważne jest, aby upewnić się, że sfinalizowałeś tagi, które mają być używane, a także ich formaty, a wszelkie nowe tagi, które są dodawane, powinny być przekazywane wszystkim. Jednocześnie pojedyncze spacje nie powinny stać się więcej niż jedną spacją, a tym można się zająć za pomocą prostego skryptu Pythona.
Zagnieżdżone tagi
Innym problemem, który może się pojawić, jest scenariusz zagnieżdżonego tagowania. Powiedzmy, że masz zdanie „Król Anglii, Edward trzeci…”. Teraz można oznaczyć to jako. {1: „król”, 2: „Anglia”, 3: „Edward trzeci”}
Chociaż może być również oznaczony jako-
b. {1: „Anglia”, 2: „król”, 3: „Edward trzeci”}
Pierwsza z nich jest poprawna, ponieważ użyliśmy tagów w kolejności, w jakiej pojawiły się w zdaniu. Ale wtedy te same słowa mogą pojawić się w innej kolejności, oznaczać to samo, i skończyć z zupełnie inną kolejnością tagów. Dlatego we wszystkich scenariuszach lepiej byłoby używać drugiego formatu. Ten rodzaj decyzji wymaga zrozumienia zarówno tematu, jak i tematu. Różne osoby oznaczające zbiór danych etykietami muszą używać tego samego formatu podczas korzystania z zagnieżdżonych etykiet.
Dodanie nowej etykiety do listy, w połowie
W połowie zadania etykietowania możesz zdać sobie sprawę, że potrzebujesz nowej etykiety, której nie ma na liście głównej. Możesz dodać go do listy głównej i poinformować wszystkich, aby używali tej etykiety, gdy jest to wymagane. Jest to bardzo odradzane. Prostym powodem jest to, że dane, które zostały już oznaczone przez Ciebie i innych, również musiałyby zostać ponownie sprawdzone, aby sprawdzić, czy etykieta znajduje się w już przetworzonych danych. Zawsze najlepiej jest przygotować listę etykiet przed rozpoczęciem oznaczania dowolnego zestawu danych.
Posiadanie długiej listy etykiet na głównej liście
Świetnym sposobem na zwiększenie kosztów projektu i obniżenie jakości danych jest posiadanie długiej listy etykiet. Załóżmy, że oznaczasz dane jako gady i ssaki. To powinno być proste i szybkie. Teraz powiedz, że masz nazwy 100 gadów i ssaków i używasz ich do etykietowania. Na etykietach mogą wystąpić błędy. Będzie to również powolne, a problemy będą się pogłębiać dopiero po popełnieniu błędów. Zawsze zaleca się, aby lista znaczników była mała i przeprowadzać oddzielne badania na oddzielnych zbiorach danych.
Rozpocznij oznaczanie danych
Nie wystarczy mieć niesamowitych naukowców zajmujących się danymi i inżynierów uczenia maszynowego, gdy rozwiązujesz problemy związane ze sztuczną inteligencją. Równie ważne jest posiadanie wydajnego zespołu zbierającego dane, jak posiadanie inteligentnego systemu czyszczenia danych i kilku doświadczonych rąk oznaczających dane, które ostatecznie będą pokarmem dla modeli ML.