
Makine Öğrenimi için Veri Etiketlemeye Yönelik Kesin Kılavuz
Yayınlanan: 2019-11-18 Çoğu makine öğrenimi projesi için veriler, veri kazıma, anket formlarını doldurma vb. gibi birden çok kaynak aracılığıyla toplanır. Genellikle bu verilerin yüksek bir yüzdesi etiketlenmemiş veya yanlış etiketlenmiştir. Etiketlenmemiş verilerden burada, özelliklerini, sınıflandırmasını veya özelliklerini belirten etiketlerle etiketlenmemiş verileri kastediyoruz. Ancak, makine öğrenimi projenize devam etmeden önce tüm bu verilerin düzgün bir şekilde etiketlenmesi gerekir. Ve bu görev çok zaman alıyor. Analitik firması Cognilytica tarafından hazırlanan bir rapora göre, bir makine öğrenimi projesine ayrılan sürenin %25'i veri etiketlemeye harcanıyor. 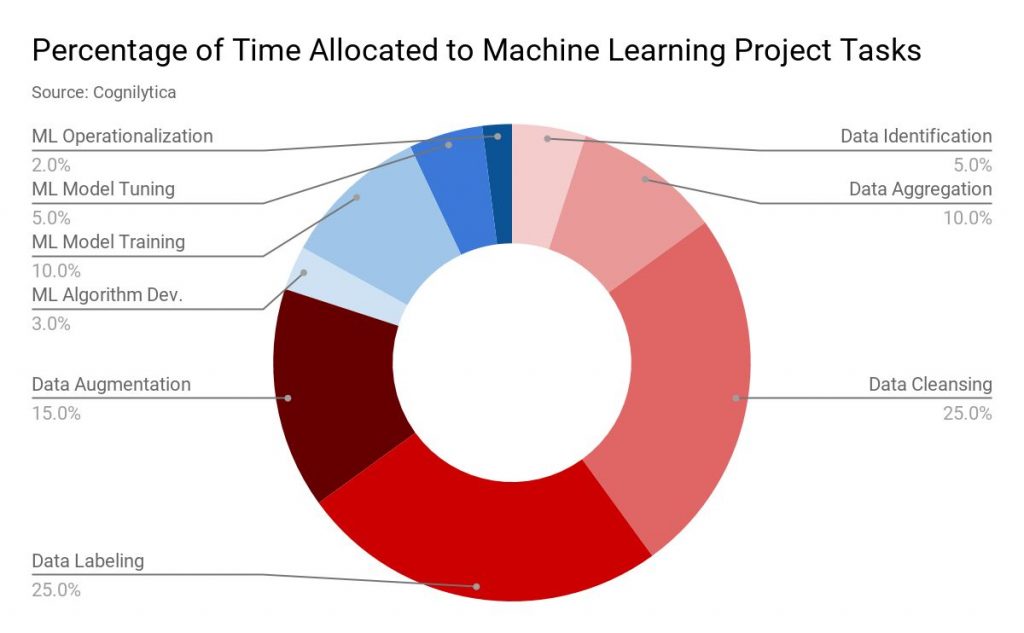 veri etiketleme” genişlik=”1200″ yükseklik=”742″ />
veri etiketleme” genişlik=”1200″ yükseklik=”742″ />
Veri etiketlemesini kim yapmalıdır?
Ekibinizdeki veri bilimcilerinin ham verileri etiketlemesini sağlamak iyi bir fikir olmayabilir. Birincisi, yapacak çok işleri var ve zamanlarını algoritmalar üzerinde çalışmak ve sorunlara çözümler bulmak için harcamak en iyisidir. Bunun yerine, iki bölümden oluşan ayrı bir ekibiniz olmalıdır: 1. Veri Etiketleme Ekip Oluşturma 2. Kalite ve Güvence ekibi.
Birincisi açıklayıcıdır, ancak ikincisi daha da önemlidir çünkü kötü etiketlenmiş verilerin tüm araştırma projenizi mahvetmesini veya sonuçları çarpıtmasını istemezsiniz. Etiketlenmiş verileri kontrol etmeye gelince, iki faktör dikkate alınmalıdır-
- Doğruluk- Bu, etiketlemenin temel gerçeğe ne kadar yakın olduğunu ölçer. Yani, tüm atlar at olarak işaretlenir ve tüm kediler kedi olarak etiketlenir.
- Kalite- Büyük bir veri etiketleme ekibiyle çalışırken bu çok önemlidir. Birden fazla kişi aynı veri setinin parçalarını sınıflandırırken, hepsinin aynı kıstası kullanması zorunludur. 2 BHK'lik bir daireyi küçük, 3 BHK'yi orta ve 4+ BHK'yi büyük olarak etiketlerseniz, hepsinin aynı olması gerekir.
Düşük kaliteli verilerin sayısız sorunu
İlk olarak, modeli eğittiğinizde yanlış bir model alıyor olacaksınız. Yine modeli doğrularken, kirli verilerin öfkesiyle karşı karşıya kalırsınız. Verileri etiketleyen kişi hem alan hem de bağlamsal bilgiye sahip olmalıdır. Bu, makine öğrenimi projeleriniz için yüksek kaliteli ve yapılandırılmış veri kümeleri oluşturmanıza yardımcı olur. Bazı senaryolarda, iki veya daha fazla kelime aynı anlama gelebilir. Etiketlemeyi yapan kişilerin bağlamı yoksa, öğeleri farklı etiketler altında etiketleyebilirler. En iyi kalitede veri etiketleme için, insanların alan bilgisine ve ayrıca verilerinizin hizmet verdiği sektör hakkında temel bir anlayışa sahip olması gerekir.
Hepimizin bildiği gibi Makine Öğrenimi yinelemeli bir süreçtir. Siz modellerinizi test ettikçe ve sonuçlarından bir şeyler öğrendikçe veri etiketleme değişebilir veya gelişebilir. Bu nedenle, gelecekteki yinelemeler için yeni etiketler hazırlamanız veya mevcut etiketleri geliştirmeniz gerekebilir. Bu nedenle, veri etiketleme ekibiniz, ML algoritmasındaki değişiklikler için etiketleri geliştirme esnekliğine sahip olmalıdır.

Etiketlenen çok fazla veriye sahip olduğunuzda, gözünüzü dört açmanız ve korumanız gereken belirli şeyler vardır.
- Altın standart – Her etiketleme sorusunun bir doğru cevabı vardır. Verilerinizin ne kadar iyi olduğunu bulmak için doğru ve yanlış etiketleri ölçebilirsiniz.
- Örnek inceleme – Küçük bir etiketli veri örneği toplayabilir ve doğruluğunu kontrol edebilirsiniz. Doğruluk yüzdesinin tüm veri setinin kendisine yayılması beklenir.
- Konsensüs - Belirli bir tartışılabilir veri parçasını etiketlerken bir tartışma olduğunda, en popüler görüş ne olursa olsun, ortak fikir birliği olarak alınmalıdır.
Veri etiketlemede kaçınılması gereken bazı yaygın ve önemli hatalar
Bir makine öğrenimi projesi için verilerin etiketlenmesiyle uğraşırken, kendinizi kaptırmak ve ince havada kaleler inşa etmek çok kolaydır. Etiketleme işinizi yaparken ayağınızı yere sağlam basmanız ve gerçekçi düşünmeniz, sınırlı ve sabit bir etiket setine sahip olmanız ve belirli kurallara uymanız gerekir.
Boşluklar, noktalama işaretleri ve büyük/küçük harf duyarlılığı
Verileri etiketlerken, boşluklar ve diğer bazı noktalama işaretleri dikkatli bir şekilde ele alınmalıdır. Bir kişinin bir resmi "Afrika fili" olarak etiketlediğini varsayalım. Bir başkası onu "Afrika fili" olarak etiketler ve bir başkası onu "Afrika fili" olarak etiketler. Şimdi nereye geldiğimizi görüyorsunuz. Bu nedenle, kullanılacak etiketlerin biçimlerini önceden belirlediğinizden ve eklenen yeni etiketlerin herkese iletildiğinden emin olmanız çok önemlidir. Aynı zamanda, tek boşluklar birden fazla boşluk haline gelmemelidir ve bu basit bir Python betiği ile halledilebilir.
iç içe etiketler
Ortaya çıkabilecek başka bir sorun, iç içe etiketleme senaryosudur. Diyelim ki “İngiltere Kralı, üçüncü Edward…” cümleniz var. Şimdi biri onu a olarak etiketleyebilir. {1: “kral”, 2: “İngiltere”, 3: “Üçüncü Edward”}
olarak da etiketlenebilse de-
b. {1: “İngiltere”, 2: “kral”, 3: “Üçüncü Edward”}
İlki doğrudur, çünkü etiketleri cümlede geçtiği sırayla kullandık. Ancak daha sonra aynı kelimeler farklı bir sırada görünebilir, yani aynı şeyi ifade edebilir ve tamamen farklı bir etiket sırası ile sonuçlanabilir. Bu nedenle tüm senaryolarda ikinci formatı kullanmak daha iyi olacaktır. Bu tür bir karar, hem konunun hem de konunun anlaşılmasını gerektirir. Veri kümesini etiketleyen farklı kişiler, iç içe geçmiş etiketleri kullanırken aynı biçimi kullanmalıdır.
Listenize yeni etiket ekleme, yarı yolda
Etiketleme görevinizin ortasında, ana listede bulunmayan yeni bir etikete ihtiyacınız olacağını fark edebilirsiniz. Bunu ana listeye eklemeye devam edebilir ve gerektiğinde ve gerektiğinde bu etiketi kullanmaları için herkesi bilgilendirebilirsiniz. Bu son derece cesaret kırıcı. Bunun basit nedeni, siz ve diğerleri tarafından zaten etiketlenmiş olan verilerin de, etiketin önceden işlenmiş verilerde yumruk olup olmadığını görmek için yeniden kontrol edilmesi gerekmesidir. Herhangi bir veri kümesini etiketlemeye başlamadan önce etiket listesini hazırlamak her zaman en iyisidir.
Ana listenizde uzun bir etiket listesine sahip olmak
Proje maliyetlerini artırmanın ve veri kalitesini düşürmenin harika bir yolu, uzun bir etiket listesine sahip olmaktır. Verileri sürüngenler ve memeliler olarak etiketlediğinizi varsayalım. Bu basit ve hızlı olmalı. Şimdi diyelim ki 100 sürüngen ve memelinin adı var ve bunları etiketlemek için kullanıyorsunuz. Etiketlemede hatalar olması muhtemeldir. Ayrıca yavaş olacak ve sorunlarınız ancak hatalar yapıldıktan sonra daha da artacaktır. Etiketler listesinin her zaman küçük tutulması ve ayrı veri kümeleri üzerinde ayrı çalışmalar yapılması önerilir.
Veri etiketlemeyi başlat
Yapay zeka ile ilgili problemlerle uğraşırken harika veri bilimcilere ve makine öğrenimi mühendislerine sahip olmak yeterli değildir. Verimli bir veri toplama ekibine sahip olmak, akıllı bir veri temizleme sistemine ve nihayetinde ML modelleri için gıda olacak verileri etiketleyen bazı deneyimli ellere sahip olmak kadar önemlidir.