
La guía definitiva para el etiquetado de datos para el aprendizaje automático
Publicado: 2019-11-18 Los datos para la mayoría de los proyectos de aprendizaje automático se recopilan a través de múltiples fuentes, como el raspado de datos, hacer que las personas completen formularios de encuestas, etc. Por lo general, un alto porcentaje de estos datos no está etiquetado o está mal etiquetado. Por datos sin etiquetar, aquí nos referimos a datos que no han sido etiquetados con etiquetas que especifiquen sus características, clasificación o propiedades. Pero todos estos datos deben etiquetarse correctamente antes de continuar con su proyecto ML. Y esta tarea lleva mucho tiempo. Según un informe de la empresa de análisis Cognilytica, hasta el 25 % del tiempo asignado a un proyecto de aprendizaje automático se dedica al etiquetado de datos. 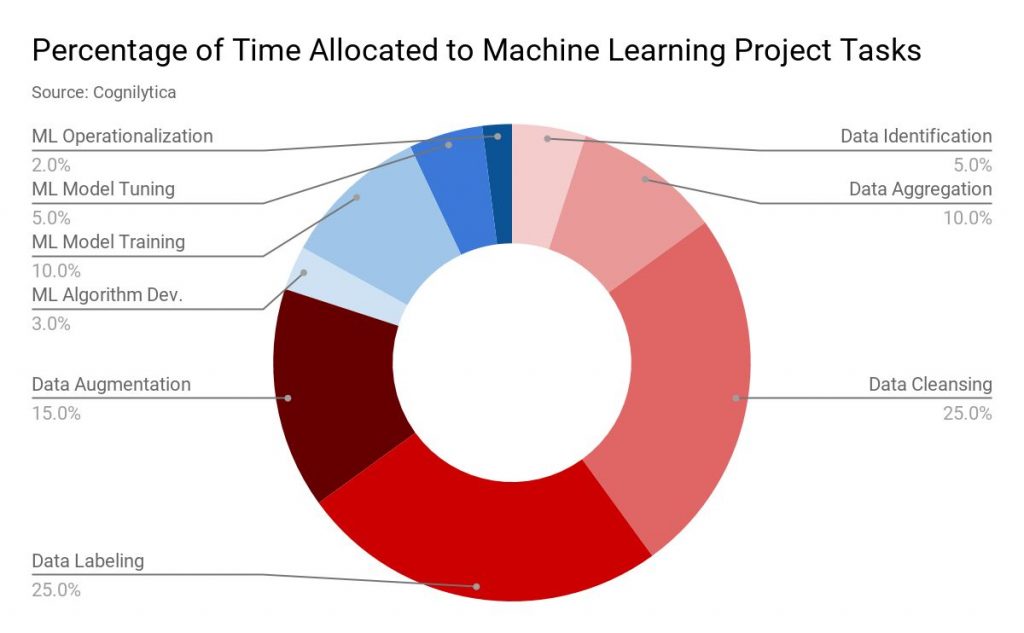 etiquetado de datos” width=”1200″ height=”742″ />
etiquetado de datos” width=”1200″ height=”742″ />
¿Quién debe realizar el etiquetado de datos?
Hacer que los científicos de datos de su equipo etiqueten los datos sin procesar puede no ser una buena idea. Por un lado, tienen mucho trabajo por hacer, y es mejor dedicar su tiempo a trabajar en algoritmos y encontrar soluciones a los problemas. En su lugar, debe tener un equipo separado que debe tener dos partes: 1. Equipo de etiquetado de datos 2. Equipo de calidad y garantía.
El primero se explica por sí mismo, pero el segundo es aún más importante ya que no querrá que los datos mal etiquetados arruinen todo su proyecto de investigación o distorsionen los resultados. Cuando se trata de controlar los datos etiquetados, se deben tener en cuenta dos factores:
- Precisión: mide qué tan cerca está el etiquetado de la realidad del suelo. Es decir, todos los caballos están marcados como caballos y todos los gatos están etiquetados como gatos.
- Calidad: cuando se trabaja con un gran equipo de etiquetado de datos, esto es muy importante. Cuando varias personas clasifican partes del mismo conjunto de datos, es imprescindible que todas utilicen el mismo criterio. Si uno etiqueta un piso de 2 BHK como pequeño, 3 BHK como mediano y 4+ BHK como grande, entonces todos deberían seguir lo mismo.
Los numerosos problemas de los datos de baja calidad
Primero, cuando entrena el modelo, obtendrá un modelo incorrecto. Nuevamente, al validar el modelo, se enfrentaría a la ira de los datos sucios. Quienquiera que esté etiquetando los datos debe tener conocimiento tanto del dominio como del contexto. Esto lo ayudaría a crear conjuntos de datos estructurados y de alta calidad para sus proyectos de aprendizaje automático. En ciertos escenarios, dos o más palabras pueden significar lo mismo. Si las personas que realizan el etiquetado no tienen contexto, pueden etiquetar los elementos con etiquetas diferentes. Para el etiquetado de datos de la mejor calidad, las personas deben tener conocimientos de dominio, así como una comprensión fundamental de la industria a la que sirven sus datos.
El aprendizaje automático, como todos sabemos, es un proceso iterativo. El etiquetado de datos puede cambiar o evolucionar a medida que prueba sus modelos y aprende de sus resultados. Entonces, para iteraciones futuras, es posible que deba preparar nuevas etiquetas o mejorar las existentes. Por lo tanto, su equipo de etiquetado de datos debe tener la flexibilidad de mejorar las etiquetas para cambios en el algoritmo de ML.

Cuando tiene una gran cantidad de datos que se etiquetan, hay ciertas cosas que necesitaría vigilar y mantener.
- Estándar de oro: para cada pregunta de etiquetado, hay una respuesta correcta. Puede medir las etiquetas correctas e incorrectas para saber qué tan buenos son sus datos.
- Revisión de muestra: puede recopilar una pequeña muestra de datos etiquetados y verificar su precisión. Se esperaría que su porcentaje de precisión se extienda por todo el conjunto de datos.
- Consenso: cuando hay un debate al etiquetar un dato debatible en particular, cualquier opinión que sea la más popular debe tomarse como el consenso común.
Algunos errores comunes e importantes que se deben evitar con el etiquetado de datos
Al profundizar en el etiquetado de datos para un proyecto de aprendizaje automático, es muy fácil dejarse llevar y construir castillos en el aire. Debe mantener el pie en el suelo y pensar de manera realista, tener un conjunto limitado y fijo de etiquetas y seguir ciertas reglas cuando se dedica a su negocio de etiquetado.
Espacios en blanco, puntuaciones y distinción entre mayúsculas y minúsculas
Al etiquetar datos, los espacios en blanco y algunos otros signos de puntuación deben manejarse con cuidado. Digamos que una persona etiqueta una imagen como "elefante africano". Alguien más lo etiqueta como "elefante africano" y otra persona lo etiqueta como "elefante africano". Ahora ves a dónde estamos llegando. Por lo tanto, es muy importante asegurarse de finalizar las etiquetas que se van a utilizar, así como sus formatos de antemano, y cualquier nueva etiqueta que se agregue debe comunicarse a todos. Al mismo tiempo, los espacios individuales no deberían terminar convirtiéndose en más de un espacio, y esto puede solucionarse con un simple script de Python.
Etiquetas anidadas
Otro problema que puede surgir es el escenario del etiquetado anidado. Digamos que tienes la oración: "El rey de Inglaterra, Eduardo tercero...". Ahora uno puede etiquetarlo como a. {1: "rey", 2: "Inglaterra", 3: "Eduardo tercero"}
Si bien también puede ser etiquetado como-
b. {1: "Inglaterra", 2: "rey", 3: "Eduardo tercero"}
La primera es correcta ya que usamos las etiquetas en el orden en que aparecían en la oración. Pero luego las mismas palabras pueden aparecer en un orden diferente, con el mismo significado, y terminar con un orden de etiquetas completamente diferente. Es por eso que sería mejor usar el segundo formato en todos los escenarios. Este tipo de decisión necesita una comprensión tanto del sujeto como del tema. Las diferentes personas que etiquetan el conjunto de datos deben usar el mismo formato cuando usan etiquetas anidadas.
Agregando una nueva etiqueta a tu lista, a mitad de camino
A la mitad de su tarea de etiquetado, es posible que se dé cuenta de que necesitaría una nueva etiqueta, que no está presente en la lista maestra. Puede agregarlo a la lista maestra e informar a todos que usen esta etiqueta cuando sea necesario. Esto está muy desaconsejado. La razón simple es que los datos que ya han sido etiquetados por usted y los demás también deberían volver a verificarse, para ver si la etiqueta se ajusta a los datos ya procesados. Siempre es mejor preparar la lista de etiquetas antes de comenzar con el etiquetado de cualquier conjunto de datos.
Tener una larga lista de etiquetas en su lista maestra
Una excelente manera de aumentar los costos del proyecto y disminuir la calidad de los datos es tener una larga lista de etiquetas. Digamos que está etiquetando datos como reptiles y mamíferos. Eso debería ser simple y rápido. Ahora diga que tiene los nombres de 100 reptiles y mamíferos y los está usando para etiquetar. Es probable que haya errores en el etiquetado. También será lento y sus problemas solo se agravarán una vez que se cometan los errores. Siempre se recomienda mantener pequeña la lista de etiquetas y realizar estudios separados en conjuntos de datos separados.
Iniciar el etiquetado de datos
No es suficiente tener científicos de datos e ingenieros de aprendizaje automático increíbles cuando se abordan problemas relacionados con la inteligencia artificial. Es tan importante contar con un equipo de recopilación de datos eficiente, como lo es tener un sistema inteligente de limpieza de datos y algunas manos experimentadas que etiquetan los datos que finalmente serán el alimento para los modelos de ML.