
機械学習のためのデータ ラベル付けの決定版ガイド
公開: 2019-11-18ほとんどの機械学習プロジェクトのデータは、データ スクレイピング、アンケート フォームへの記入など、複数のソースを通じて収集されます。通常、このデータの大部分はラベル付けされていないか、誤ってラベル付けされています。 ラベルのないデータとは、ここでは、特性、分類、またはプロパティを指定するラベルでタグ付けされていないデータを指しています。 ただし、ML プロジェクトに進む前に、このすべてのデータに適切なラベルを付ける必要があります。 そして、この作業には多くの時間がかかります。 分析会社 Cognilytica のレポートによると、機械学習プロジェクトに割り当てられた時間の 25% がデータのラベル付けに費やされています。 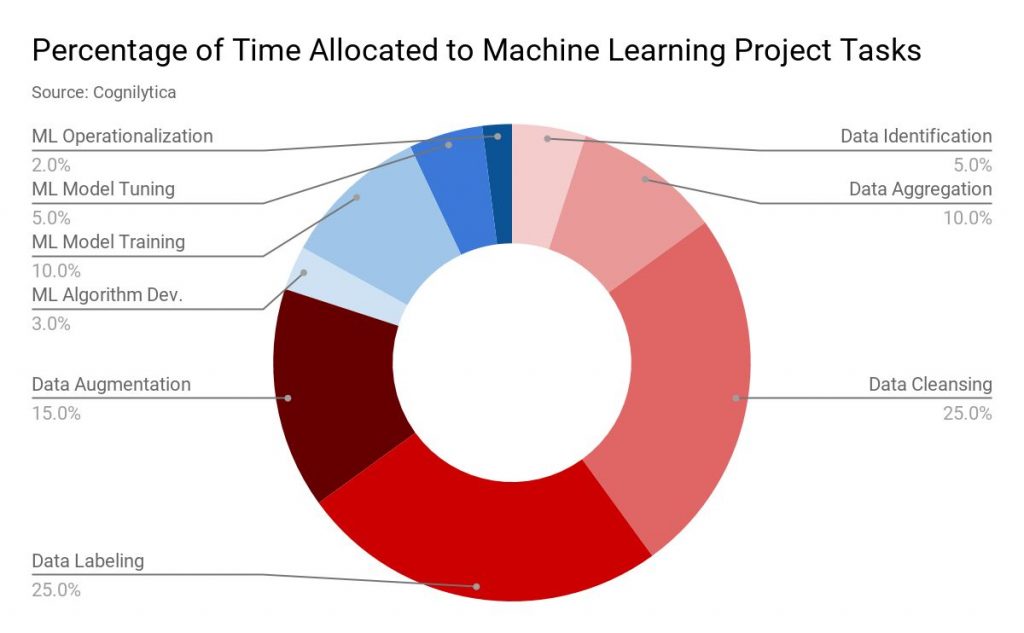 データのラベル付け」 width=”1200″ height=”742″ />
データのラベル付け」 width=”1200″ height=”742″ />
誰がデータのラベル付けを実行する必要がありますか?
チームのデータ サイエンティストに生データのラベル付けをさせるのは得策ではないかもしれません。 1 つは、彼らには他にやるべき仕事がたくさんあり、彼らの時間は、アルゴリズムに取り組み、問題の解決策を考え出すことに費やすのが最善です。 代わりに、1. データのラベル付けのチーム化 2. 品質と保証のチームの 2 つの部分を持つ別のチームを用意する必要があります。
1 つ目は一目瞭然ですが、ラベル付けが不十分なデータによって研究プロジェクト全体が台無しになったり、結果がゆがめられたりすることは望ましくないため、2 つ目はさらに重要です。 ラベル付けされたデータをチェックする際には、次の 2 つの要素を考慮する必要があります。
- 精度 - これは、ラベリングがグラウンド トゥルースにどれだけ近いかを測定します。 つまり、馬としてマークされたすべての馬と、猫としてマークされたすべての猫です。
- 品質 - 大規模なデータ ラベル付けチームで作業する場合、これは非常に重要です。 複数の人が同じデータセットの一部を分類している場合、全員が同じ尺度を使用する必要があります。 2 BHK のフラットを小、3 BHK を中、4+ BHK を大とラベル付けした場合、すべてが同じになるはずです。
低品質データの数々の問題
まず、モデルをトレーニングすると、間違ったモデルが得られます。 モデルを検証するときも、汚れたデータの怒りに直面するでしょう。 データにラベルを付ける人は誰でも、ドメイン知識とコンテキスト知識の両方を持っている必要があります。 これは、機械学習プロジェクト用に高品質で構造化されたデータセットを作成するのに役立ちます。 特定のシナリオでは、2 つ以上の単語が同じことを意味する場合があります。 ラベル付けを行う人がコンテキストを持っていない場合、別のタグでアイテムにラベルを付けることがあります。 最高品質のデータ ラベル付けを行うには、ドメインの知識と、データが提供される業界の基本的な理解が必要です。

ご存知のように、機械学習は反復的なプロセスです。 モデルをテストしてその結果から学習するにつれて、データのラベル付けが変更または進化する可能性があります。 したがって、今後のイテレーションでは、新しいラベルを準備するか、既存のラベルを強化する必要があるかもしれません。 したがって、データ ラベル付けチームは、ML アルゴリズムの変更に合わせてラベルを拡張できる柔軟性を備えている必要があります。
大量のデータにラベルを付ける場合、注意を払い、維持する必要がある特定の事柄があります。
- ゴールド スタンダード – すべてのラベリングの質問には、正解があります。 正しいラベルと正しくないラベルを測定して、データの品質を確認できます。
- サンプル レビュー – ラベル付けされたデータの小さなサンプルを収集し、正確性をチェックできます。 その精度のパーセンテージは、データセット自体全体に広がると予想されます。
- コンセンサス – 特定の議論可能なデータにラベルを付ける際に議論がある場合、最も人気のある意見が何であれ、共通のコンセンサスとして取られるべきです。
データのラベル付けで避けるべきよくある重要な間違い
機械学習プロジェクトのデータのラベル付けを詳しく調べると、夢中になって城を築くのは非常に簡単です。 地に足をつけて現実的に考え、限られた固定されたラベルのセットを持ち、ラベル付けビジネスを行うときは特定のルールに従う必要があります。
空白、句読点、大文字と小文字の区別
データにラベルを付ける場合、空白やその他の句読点は注意して処理する必要があります。 ある人が画像に「アフリカゾウ」のタグを付けたとします。 他の人は「アフリカゾウ」とタグ付けし、さらに別の人は「アフリカゾウ」とタグ付けしました。 これで、私たちがどこに到達しているかがわかります。 したがって、使用するタグとその形式を事前に確定し、追加された新しいタグを全員に通知することが非常に重要です。 同時に、単一のスペースが複数のスペースになることはありません。これは、単純な Python スクリプトで処理できます。
ネストされたタグ
発生する可能性のある別の問題は、ネストされたタグ付けのシナリオです。 「イングランド王、エドワード 3 世…」という文があるとします。 これで、 としてタグ付けできます。 {1:「王」、2:「イングランド」、3:「エドワード三世」}
また、次のようにタグ付けされる場合もありますが、
b. {1:「イングランド」、2:「王」、3:「エドワード三世」}
最初のタグは、文中に出現した順序でタグを使用したため、正しいです。 しかし、同じ単語が別の順序で表示され、同じことを意味し、最終的にタグの順序がまったく異なる場合があります。 これが、すべてのシナリオで 2 番目の形式を使用する方がよい理由です。 この種の決定には、主題とトピックの両方を理解する必要があります。 ネストされたラベルを使用する場合、データセットにラベルを付ける別の人が同じ形式を使用する必要があります。
途中でリストに新しいラベルを追加する
ラベル付けタスクの途中で、マスター リストにない新しいラベルが必要になることに気付くかもしれません。 それをマスター リストに追加し、必要に応じてこのラベルを使用するように全員に通知することもできます。 これは非常にお勧めできません。 単純な理由は、ラベルがすでに処理されたデータに含まれているかどうかを確認するために、自分や他の人によって既にラベル付けされているデータも再チェックする必要があるからです。 データセットのラベル付けを開始する前に、ラベルのリストを用意しておくことをお勧めします。
マスターリストにラベルの長いリストがある
プロジェクトのコストを増やし、データの品質を下げる優れた方法は、ラベルのリストを長くすることです。 データを爬虫類と哺乳類としてラベル付けしているとします。 それは簡単で速いはずです。 ここで、100 種類の爬虫類と哺乳類の名前があり、それらをラベル付けに使用しているとします。 ラベル付けには間違いがあります。 また、遅くなり、エラーが発生すると問題が悪化します。 タグのリストを小さく保ち、別々のデータセットで別々の調査を実施することを常にお勧めします。
データのラベル付けを開始
人工知能に関連する問題に取り組む場合、優れたデータ サイエンティストや機械学習エンジニアがいるだけでは十分ではありません。 効率的なデータ収集チームを持つことは、インテリジェントなデータ クリーニング システムと、最終的に ML モデルの材料となるデータにラベルを付ける経験豊富なスタッフを持つことと同様に重要です。