
Нормализация данных: преобразование необработанных чисел в доход
Опубликовано: 2022-05-13Данные лежат в основе всех бизнес-решений. Оно окружает нас на каждом шагу. К сожалению, информация, которую вы получаете непосредственно из источников данных, часто неструктурирована, фрагментирована и вводит в заблуждение.
Вы, вероятно, сидите на куче скучных данных, которые могут помочь вам привлечь потенциальных клиентов, повысить рентабельность инвестиций и увеличить доход.
Нормализация данных превратит ваши необработанные цифры в полезную информацию, повышающую ценность.
Что такое нормализация данных?
Если использовать несколько громких слов, нормализация данных — это процесс организации данных таким образом, чтобы они соответствовали определенному диапазону или стандартным формам. Это помогает аналитикам получать новые идеи, минимизировать избыточность данных, избавляться от дубликатов и делать данные легко усваиваемыми для дальнейшего анализа.
Однако такая формулировка может быть сложной и запутанной, поэтому давайте приведем ее к простому и наглядному примеру.
Представьте, что вы садовник, собирающий яблоки. В этом году вам удалось собрать 500 яблок с 20 деревьев . Однако ваш сосед хвастается, что собрал 1000 яблок , и называет вас ужасным садовником.
Если вы сравните свои 500 яблок с 1000 яблок вашего соседа, может показаться, что вы не очень искусный садовник. Но ваш сосед никогда не говорил вам, что посадил сотню яблонь, чтобы добиться такого урожая.
Если нормализовать данные, то выяснится, что ваш сосед попал в неприятную ситуацию. Собрав 500 яблок с 20 деревьев, вы соберете по 25 яблок с каждого дерева , в то время как ваш сосед получит только 10 яблок с дерева. Итак, кто теперь ужасный садовник?
Анализ может быть запутан большим количеством ненормализованных данных, поэтому за деревьями не видно леса.
Вот еще один пример с использованием данных управления оружием. Это показывает нам, насколько легко стать жертвой когнитивной предвзятости без нормализации данных.

Без нормализованного инсайта практически невозможно построить комплексную картину и принять взвешенное решение по исследуемой теме.
Основные выводы:
- Нормализация данных — это процесс реорганизации данных в наборе данных.
- Этот процесс упрощает дальнейший анализ и операции с данными.
- Нормализация данных гарантирует, что вы получите всестороннее представление об исследуемой теме.
Хорошо, но когда вам нужно нормализовать данные?
Пользователи сталкиваются с различными проблемами из-за разнородных данных (данных с высокой изменчивостью типов и форматов данных). Есть и другие случаи использования, когда вам нужно нормализовать данные. Рассмотрим этот вопрос с точки зрения маркетологов.
Прежде всего, это унификация соглашений об именах. Например, собирая данные из десятков маркетинговых каналов, аналитики часто сталкиваются с одними и теми же метриками под разными названиями. В результате аналитики сталкиваются с трудностями при отображении данных.
Например, вот как один пользователь Reddit объясняет свои проблемы с разрозненными данными.
Еще одна проблема заключается в объединении разрозненных данных, таких как валюты или часовые пояса, в единый источник достоверной информации. Вы просто не можете создать информативную информационную панель, пока ваши расходы на рекламу делятся на доллары, евро, фунты стерлингов и несколько других валют.
Вот как другой маркетолог описывает эту проблему на Reddit.
Итак, когда пора нормализовать ваши данные?
- При сопоставлении метрик в вашем наборе данных используются разные соглашения об именах.
- Когда вам нужно сопоставить разнородные данные, такие как валюты, часовые пояса, форматы даты и т. д.
- Когда вы заметите, что некоторые ваши данные избыточны, и вам нужно их удалить.
Термины, которые часто путают: нормализация данных и стандартизация
В преобразовании данных стандартизация и нормализация — это два разных термина, которые часто путают.
Нормализация изменяет масштаб значений набора данных, чтобы они попадали в диапазон [0,1] . Этот процесс полезен, когда вам нужно, чтобы все параметры были на положительной шкале.
Стандартизация корректирует ваши данные , чтобы иметь среднее значение 0 и стандартное отклонение 1 . Он не обязательно должен попадать в определенный диапазон, и на него гораздо меньше влияют выбросы.
Этой информации более чем достаточно, чтобы маркетинговые аналитики перестали путать термины. Однако, если вы хотите глубже погрузиться в эту тему, вы можете найти все различия между двумя понятиями здесь.
Как нормализовать данные и собрать воедино свои идеи
По своей сути нормализация данных требует от вас создания стандартного формата данных для всех записей в вашем наборе данных. Ваш алгоритм должен хранить все данные в едином формате независимо от входных данных.
Вот несколько примеров нормализации данных:
- Мистер ХОЛМС должен храниться как мистер Холмс.
- Пятая авеню Sf должна храниться как 5-я авеню, Сан-Франциско.
- Технический директор должен храниться как главный технический директор.
Нормализация данных идет рука об руку с нормализацией базы данных. Давайте кратко рассмотрим, что это такое.
Нормализация базы данных: предварительное условие для очищенной информации
Нормализация базы данных — это процесс организации таблиц и строк данных внутри реляционной базы данных.
Этот процесс включает в себя создание и управление отношениями между таблицами. При нормализации баз данных аналитики и инженеры данных полагаются на правила, которые помогают защитить данные и сделать их более гибкими для дальнейшего анализа.
Все правила объявляются типами нормализации базы данных или так называемыми «нормальными формами».
Всего существует семь нормальных форм (наиболее часто используются первые три):
- Первая нормальная форма (1 НФ)
- Вторая нормальная форма (2 NF)
- Третья нормальная форма (3 NF)
- Нормальная форма Бойса-Кодда (BCNF)
- Четвертая нормальная форма (4 NF)
- Пятая нормальная форма (5 NF)
- Шестая нормальная форма (6 NF)
Давайте рассмотрим все эти нормальные формы, чтобы узнать, как они помогают нормализовать ваши данные.
Первая нормальная форма (1NF)
Первая нормальная форма требует, чтобы таблица данных удовлетворяла следующим условиям:
- Каждая ячейка таблицы должна иметь одно значение.
- Каждая запись должна быть уникальной.
- Ни один из столбцов не должен содержать скрытых значений.
Давайте рассмотрим пример. Здесь у нас есть две записи из таблицы сотрудников.

Ячейки Department_Name содержат более одного параметра в ячейке. Таким образом, они нарушают первое правило 1NF.
Вы должны разделить эту таблицу на две части, чтобы нормализовать таблицу и удалить повторяющиеся группы. Нормализованные таблицы будут выглядеть так:

Вторая и третья нормальные формы вращаются вокруг зависимостей между столбцами первичного ключа и неключевыми столбцами.
Вторая нормальная форма (2NF)
Основное требование второй нормальной формы состоит в том, что все атрибуты таблицы должны зависеть от первичного ключа. Другими словами, все значения во вторичных столбцах должны иметь зависимость от основного столбца.
Примечание. Первичный ключ — это уникальное значение столбца, которое помогает идентифицировать запись базы данных. Он имеет некоторые ограничения и атрибуты:
- Значение первичного ключа не может быть NULL.
- Значение первичного ключа всегда должно быть уникальным для каждой таблицы.
Кроме того, таблица уже должна быть в 1NF со всеми удаленными частичными зависимостями и помещена в отдельную таблицу.
На этом этапе наиболее проблемным вопросом становится составной первичный ключ .
Примечание. Составной первичный ключ — это первичный ключ, состоящий из двух или более столбцов данных.
Давайте представим, что у вас есть таблица, в которой отслеживаются курсы, которые прошли ваши сотрудники. На один и тот же курс могут записываться разные сотрудники. Вот почему вам понадобится составной ключ для идентификации уникальной записи. Столбец Date будет дополнительным параметром для вашего составного ключа. Взгляните на пример:
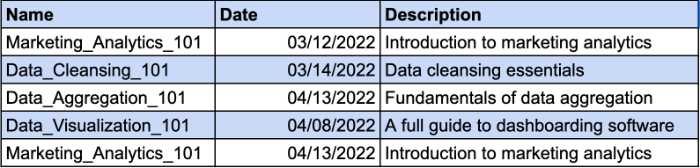
Однако столбец «Описание» функционально зависит от столбца «Имя». Если вы измените название курса, вы также должны изменить его описание. Итак, вам нужно будет создать отдельную таблицу для описания курса, чтобы соответствовать требованиям 2NF.

Вот как вы можете дать описанию курса отдельный ключ и уйти от использования составного ключа.
Третья нормальная форма (3NF)
Третья нормальная форма требует, чтобы все неключевые столбцы в вашей таблице напрямую зависели от первичного ключа. Другими словами, если вы удалите любой из неключевых столбцов, оставшиеся столбцы по-прежнему должны предоставлять уникальный идентификатор для каждой записи.
Вот основные требования 3NF:
- Все столы соответствуют требованиям 2NF.
- Столбцы, не являющиеся первичными ключами, должны зависеть только от столбцов первичного ключа.
- Таблицы не имеют транзитивной функциональной зависимости.
Основное различие между 2НФ и 3НФ заключается в том, что в 3НФ нет транзитивных зависимостей. Транзитивная зависимость существует, когда неключевой столбец зависит от другого неключевого столбца.
Примечание. Транзитивная зависимость — это косвенная связь между значениями в одной таблице, которая вызывает функциональную зависимость. Функциональная зависимость устанавливает определенные ограничения между атрибутами. В этом отношении атрибут A определяет значение атрибута B, а B определяет значение атрибута A.
Взгляните на пример ниже:

Здесь идентификатор сотрудника определяет идентификатор отдела из нашего предыдущего примера, а идентификатор отдела определяет название отдела. Здесь возникает косвенная зависимость между идентификатором сотрудника и названием отдела.
Чтобы соответствовать требованиям 3NF, нам нужно разделить таблицу на несколько частей.
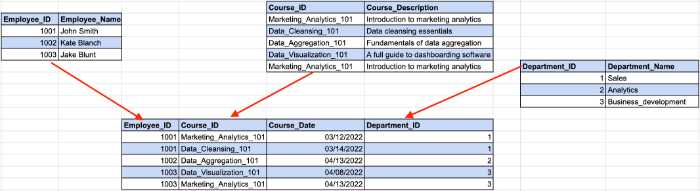
В этой структуре все неключевые столбцы зависят исключительно от первичного ключа.
Несмотря на то, что существует семь нормальных форм, база данных считается нормализованной после соответствия требованиям 3NF. Мы сделаем краткий обзор оставшихся нормальных форм, чтобы раскрыть тему до конца.
Нормальная форма Бойса-Кодда (BCNF)
Это более надежная версия 3NF. Таблица BCNF должна соответствовать всем правилам 3NF и не должна содержать несколько перекрывающихся ключей-кандидатов.
Четвертая нормальная форма (4NF)
База данных считается 4НФ, если любой из ее экземпляров содержит две или более независимых и многозначных записей данных.
Пятая нормальная форма (5NF)
Таблица попадает в пятую нормальную форму, если она соответствует требованиям 4NF и ее нельзя разбить на меньшие таблицы без потери данных.
Шестая нормальная форма (6NF)
Шестая нормальная форма предназначена для разложения переменных отношения на неприводимые компоненты. Это может быть важно при работе с временными переменными или другими интервальными данными.
Это все, что касается нормализации базы данных. 101. Теперь, когда вы знаете, как все работает, вы можете лучше понять преимущества нормализации данных для ваших идей.
Почему важно нормализовать данные?
Как мы уже упоминали, основной целью и преимуществом нормализации данных является уменьшение избыточности данных и несогласованности в базах данных. Чем меньше у вас дублирования, тем меньше ошибок и проблем может возникнуть при извлечении данных.
Однако есть менее очевидные преимущества, которые помогают аналитикам данных в их рабочем процессе.
Картирование данных больше не является отстойным временем
Если вам когда-либо приходилось иметь дело с ненормализованными данными, вы знаете, что процесс сопоставления данных из нескольких таблиц в одну довольно утомителен.
Это требует объединения нескольких таблиц, работы с дубликатами и очистки множества пустых записей данных.
Конечно, вы можете нормализовать данные вручную, написав SQL-запросы или скрипты Python. Однако инструменты сопоставления данных с возможностями автоматической нормализации данных ускорят этот процесс.
Например, Oracle Integration Cloud предлагает функции сопоставления данных. После нормализации данных в облаке инструмент создает метаданные для исходных схем и создает запись «один к одному» для каждого объекта данных в целевой схеме.
У аналитиков, работающих с маркетинговой информацией, есть свои скрытые жемчужины. MCDM (Marketing Common Data Model) от Improvado — это швейцарский армейский нож для нормализации данных о маркетинге и продажах. Инструмент унифицирует разрозненные соглашения об именах, нормализует ваши идеи и устраняет разрыв между источниками данных и местом назначения без каких-либо ручных действий.
️ Найдите подходящие инструменты для отображения данных в нашем обширном списке ️
Используйте хранилище данных более эффективно
С каждым днем компании собирают все больше и больше данных, которые занимают место для хранения. Независимо от того, используете ли вы облачное хранилище или локальное хранилище данных, вы должны использовать его эффективно.
Например, 100 ТБ данных, хранящихся в AWS S3, обойдутся вам в 2580 долларов в месяц. Более того, Amazon будет взимать плату за каждый запрос, который вы выполняете с вашими данными. Десятки гигабайт избыточных данных не только увеличат ваш счет за услуги хранения, но и заставят вас платить за анализ бессмысленных инсайтов.
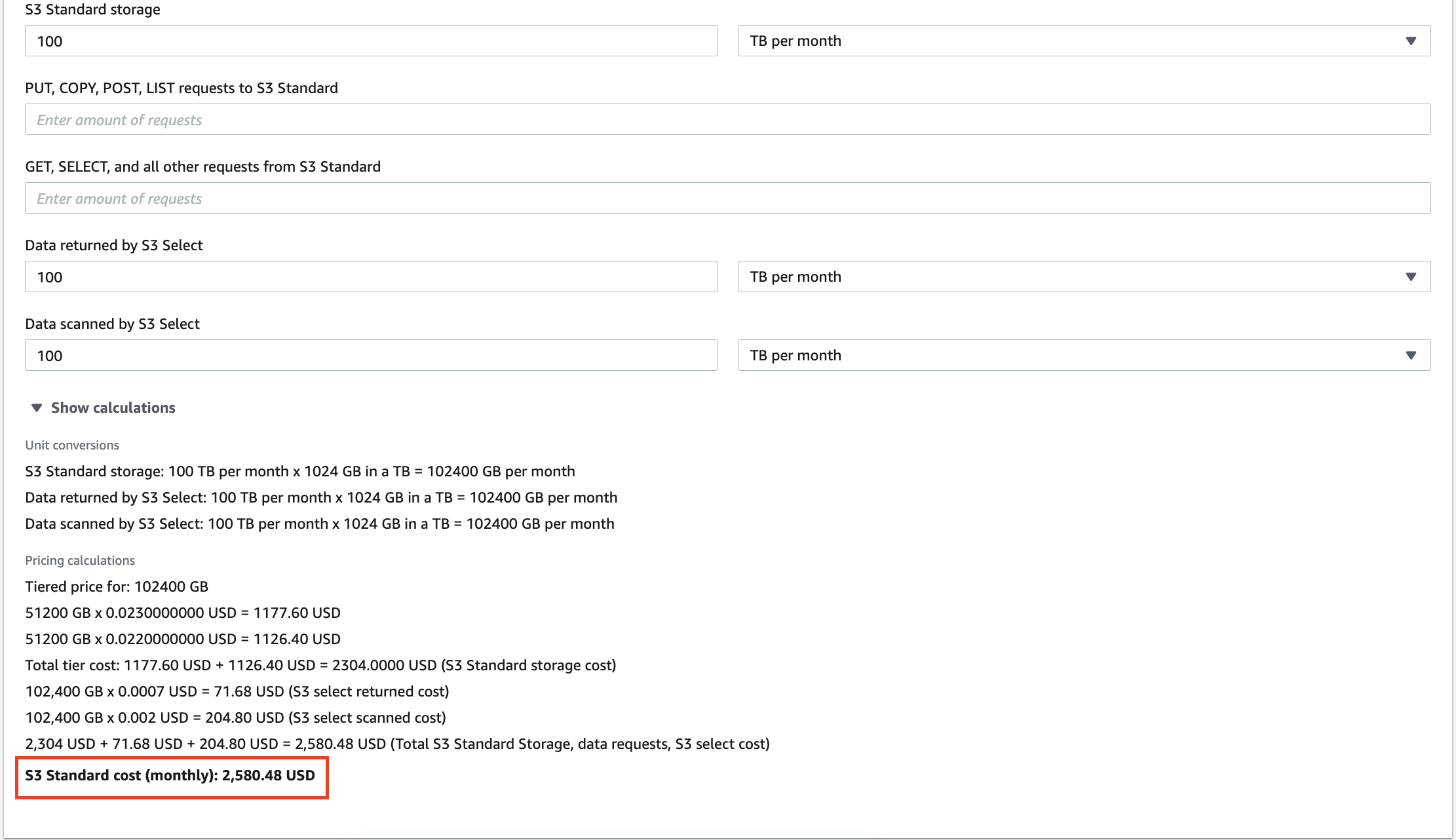
Масштабирование локальных хранилищ данных также обходится дорого, поэтому удаление ненужной информации может помочь снизить эксплуатационные расходы и совокупную стоимость владения.

Сократите время получения информации
Помимо снижения затрат, аналитики также могут повысить производительность своего анализа.
Выполнение запросов к терабайтам данных требует времени. Пока ваша система обрабатывает запрос, вы можете спокойно выпить чашечку кофе и обсудить политику с коллегами. Но жаль, когда вывод запроса бессмысленен, потому что у вас были некоторые несоответствия в вашем наборе данных.
С нормализованными данными вы всегда получаете ожидаемый результат, но без сюрпризов, таких как «N/A», «NaN», «NULL» и т. д. Более того, система выполняет ваши запросы быстрее, когда вы анализируете только релевантные данные. Кто знает, может быть, в следующий раз вы получите результат до того, как ваша кофеварка приготовит капучино!
Создавайте информационные панели, которым можно доверять
Визуализация данных — лучший способ создать полную картину ваших усилий по анализу. Однако информационные панели не имеют ценности, если вы строите их на жестких данных. Приборная панель не будет отражать истинное положение дел, если вы будете кормить ее дубликатами.
Вот почему нормализация данных является главным приоритетом, если вы хотите объяснить сложные концепции или показатели эффективности через призму красочных диаграмм и столбцов.
Как нормализовать данные в разных средах
Поскольку аналитики данных работают с разными инструментами, мы объясним, как нормализовать данные в самых востребованных средах на современном рынке.
Как нормализовать данные в Python
Специалисты по данным и аналитики, работающие с Python, используют несколько библиотек для обработки данных и их очистки. Вот самые популярные среди них:
- Панды
- Нампи
- ТензорФлоу
Мы рассмотрим некоторые функции этих библиотек, которые могут помочь вам ускорить процесс нормализации данных.
Удаление столбцов в вашем наборе данных
Необработанные данные часто содержат избыточные или ненужные категории. Например, вы работаете с набором данных маркетинговых показателей, включающим показы, цену за клик, CTR, рентабельность инвестиций в рекламу и конверсии, но вам нужны только конверсии из этой таблицы.
Если для анализа не важно все, кроме конверсий, нужно удалить лишние столбцы. Pandas предлагает простой способ удаления столбцов из набора данных с помощью функции drop().
Во-первых, вы должны определить список столбцов, которые вы хотите удалить. В нашем случае это будет выглядеть так:
column_drop_list = ['Показы, 'CPC', 'CTR', 'ROAS']
Затем вам нужно выполнить функцию:
dataframe_name.drop (column_drop_list, inplace = True, ось = 1)
В этой строке кода первый параметр обозначает имя нашего списка столбцов. Установка для параметра inplace значения True означает, что Pandas будет применять изменения непосредственно к вашему объекту. Третий параметр указывает, следует ли удалять метки или столбцы из фрейма данных («0» — метки, «1» — столбцы).
После повторной проверки набора данных вы увидите, что все лишние столбцы успешно удалены.
Очистка полей данных
Еще один шаг — привести в порядок поля данных. Это помогает повысить согласованность данных и привести данные в стандартизированный формат.
Основная проблема здесь в том, что нельзя быть уверенным, что API маркетинговой платформы передаст 100% точные данные. Вы все еще можете столкнуться с неуместными символами или вводящими в заблуждение данными в дальнейшем.
Одна маркетинговая кампания может иметь только одно количество показов. Вот почему нам нужно отделить ценные числа от других символов.
Регулярные выражения (регулярные выражения) могут помочь вам идентифицировать все цифры в вашем наборе данных. Этот генератор регулярных выражений поможет вам создать регулярное выражение для ваших нужд и сразу же протестировать его.
Затем с помощью функции str.extract() мы можем извлечь необходимые данные из набора данных в виде столбцов.
true_impressions = dataframe_name.str.extract(your_regex), expand = False)
Наконец, вам может понадобиться преобразовать столбец в числовую версию. Поскольку все столбцы во фрейме данных имеют тип объекта, преобразование его в числовое значение упростит дальнейшие вычисления. Вы можете сделать это с помощью функции pd.to_numeric().
Переименование столбцов во фрейме данных
Источники данных часто передают столбцы с именами, которые аналитики не могут понять. Например, CTR по какой-то причине может называться C_T_R_final.
Еще одна проблема выявляется, когда вы объединяете данные из разных источников и анализируете их как единое целое. В то время как первый источник данных называет показы показами, другой — просмотрами. Это затрудняет расчет и построение целостной картины по всем источникам данных.
Вот почему вам нужно переименовать столбцы, чтобы все было структурировано.
Во-первых, создайте словарь с будущими именами ваших столбцов. Предположим, у нас есть показы из Google Ads и Facebook Ads с разными соглашениями об именах. В этом случае наш словарь будет выглядеть следующим образом:
new_clmn_names = {'Показы' : 'Показы Google Реклама',
«Просмотры»: «Показы рекламы на Facebook»}
Затем вы должны использовать функцию rename() в вашем фрейме данных:
dataframe_name.rename (столбцы = new_clmn_names, inplace = True)
Теперь вашим столбцам будут присвоены имена в словаре.
Pandas имеет гораздо больше различных функций, которые могут помочь вам нормализовать данные. Мы рекомендуем прочитать официальную документацию, чтобы лучше понять другие функции.
Как нормализовать данные в Excel
Excel или Google Таблицы — это мощный инструмент, любимый многими аналитиками благодаря простоте использования и широким возможностям. Нет никаких сомнений в том, что языки программирования, такие как R или Python, предлагают больше возможностей, но электронные таблицы отлично справляются с анализом данных.
Однако ваши таблицы могут содержать разнородные данные, а Excel предоставляет набор инструментов для нормализации аналитических данных.
Обрезка лишних пробелов
Выявление лишних пробелов в большой таблице — пустая трата времени, если делать это вручную. К счастью, в Excel и Google Sheets есть функция TRIM, которая позволяет аналитикам удалять лишние пробелы в наборе данных с помощью всего одной функции. Взгляните на пример ниже.

Как видите, в данных ввода есть большие пробелы между словами. С помощью функции TRIM данные помещаются в правильный формат.

Удаление пустых строк данных в наборе данных
Пустые ячейки могут перерасти в настоящий кошмар во время анализа. Вот почему вы всегда должны иметь дело с ними заранее. Вот как это сделать.
- Выберите все ячейки и нажмите на вкладку «Данные» на панели инструментов.

- Нажмите кнопку «Сортировать диапазон по столбцу (от Z до A)» в меню диапазона сортировки.
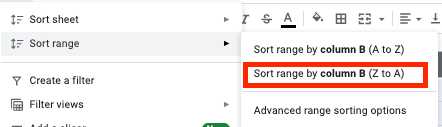
- Теперь у вас есть все пустые строки в нижней части таблицы, так что вы можете просто выбрать и удалить их.
Удаление дубликатов
Повторяющиеся записи данных — распространенная проблема для аналитиков, работающих в Excel или Google Sheets. Вот почему эти инструменты имеют специальную функцию для быстрого и простого удаления дубликатов.
В Google Sheets есть функция UNIQUE, которая позволяет хранить в таблице только уникальные данные.
Предположим, у вас есть эта простая таблица со столбцами «Имя» и «Возраст», которые содержат несколько дубликатов.

Вы можете получить чистую таблицу без повторяющихся записей, передав свой набор данных функции UNIQUE.

Нормализация регистра текста
После импорта данных из текстовых файлов вы часто будете сталкиваться с несогласованными текстовыми регистрами в именах или заголовках. Вы можете легко исправить свои данные в Excel или Google Таблицах, используя следующие функции:
- LOWER() — переводит весь текст в нижний регистр.
- UPPER() — переводит весь текст в верхний регистр.
- PROPER() - преобразует весь текст в правильный регистр.

В зависимости от вашего конкретного варианта использования существует множество способов нормализовать данные Excel или Google Sheets. Эти руководства проливают больше света на нормализацию данных Excel:
- Методы очистки данных Excel
- Советы Microsoft по нормализации данных Excel
Инструменты автоматической нормализации данных
Языки программирования предлагают широкий набор инструментов для нормализации ваших данных. Однако ручная нормализация данных имеет свои ограничения.
Прежде всего, аналитикам нужны сильные инженерные знания и практический опыт работы с необходимыми библиотеками. Специалисты по данным и инженеры — очень желанные таланты, и их зарплаты часто астрономические.
Кроме того, кодирование требует времени и часто подвержено ошибкам. Таким образом, последующий обзор проанализированного набора данных является обязательным. В конце концов, процесс анализа может занять гораздо больше времени, чем предполагалось.
Автоматизированные инструменты экономят время аналитиков и дают более точные результаты. Вы можете упорядочить свои данные с помощью инструмента нормализации и получить очищенную информацию за считанные минуты, а не дни.
Рассмотрим на примере Improvado. Improvado — это платформа ETL для получения доходов, которая помогает маркетологам и продавцам согласовывать разрозненные данные и хранить их в одном месте.
Платформа собирает данные из более чем 300 источников и помогает аналитикам нормализовать их без особых усилий. Современный рынок инструментов маркетинга и продаж фрагментирован, и разные платформы используют разные соглашения об именах для одинаковых показателей.
Маркетинговая общая модель данных Improvado (MCDM) — это унифицированная модель данных, которая обеспечивает автоматическое межканальное сопоставление, дедупликацию и объединение популярных источников данных. Кроме того, он объединяет и стандартизирует платные медиа-источники, автоматически передавая готовые к анализу идеи в ваше хранилище данных.
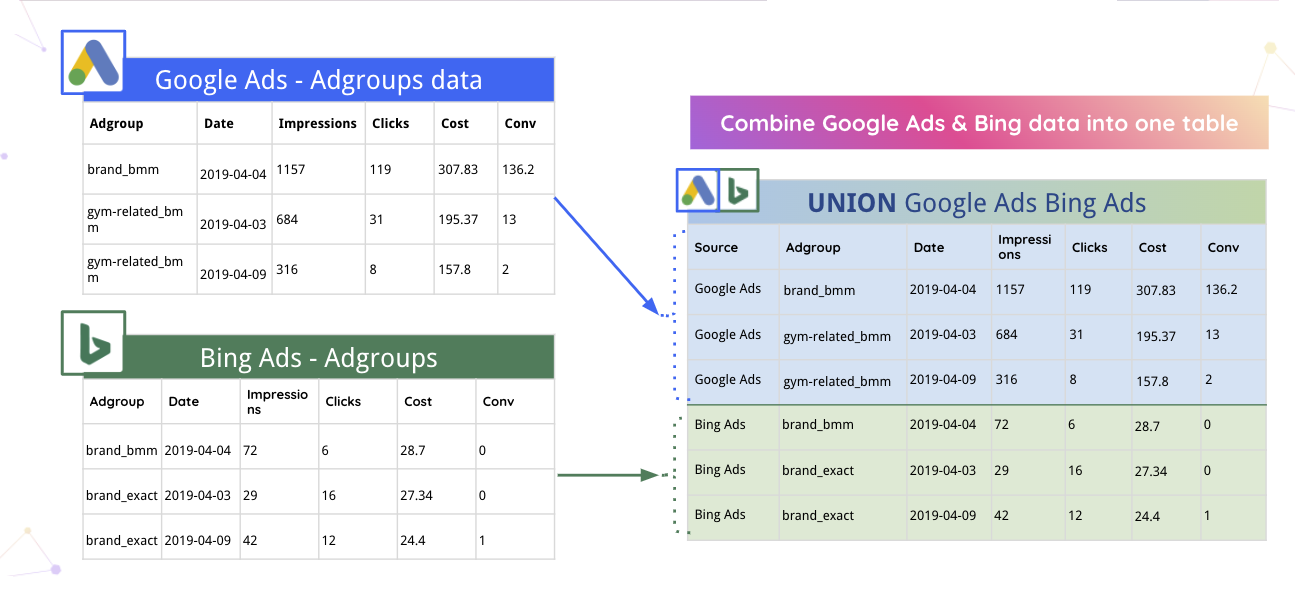
Например, Improvado может автоматически объединять данные Google Ads и Bing в одну таблицу.
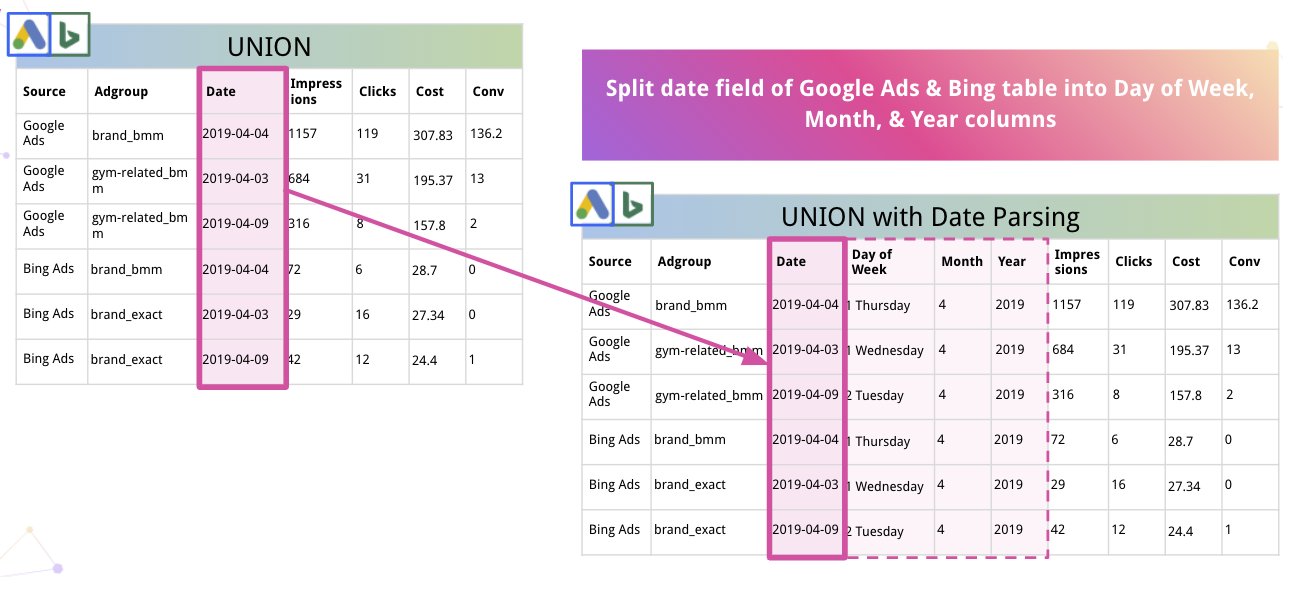
Кроме того, платформа может автоматически анализировать данные и преобразовывать их в подходящий формат. Например, вот как Improvado разбивает дату на столбцы «День недели», «Месяц» и «Год».
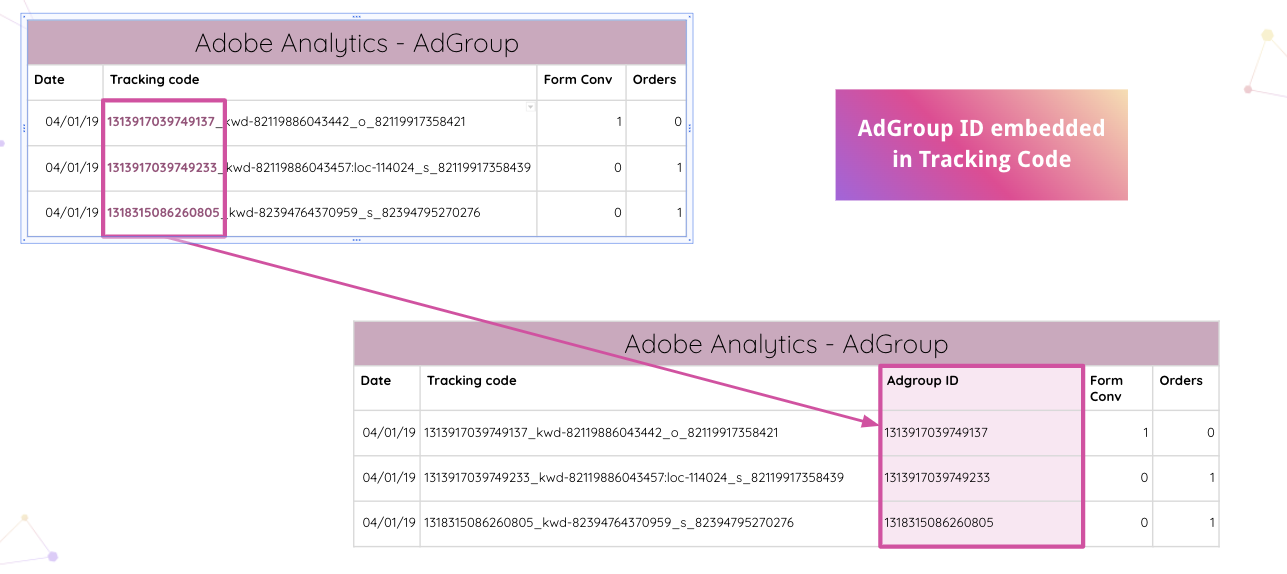
Improvado идет еще дальше, позволяя аналитикам автоматически анализировать коды отслеживания Adobe Analytics на вашем веб-сайте. Вы можете извлечь встроенный идентификатор AdGroup из кода отслеживания без ручных манипуляций.
Затем аналитики могут комбинировать внутренние электронные таблицы с классификациями и сопоставлять их на основе идентификатора сети.
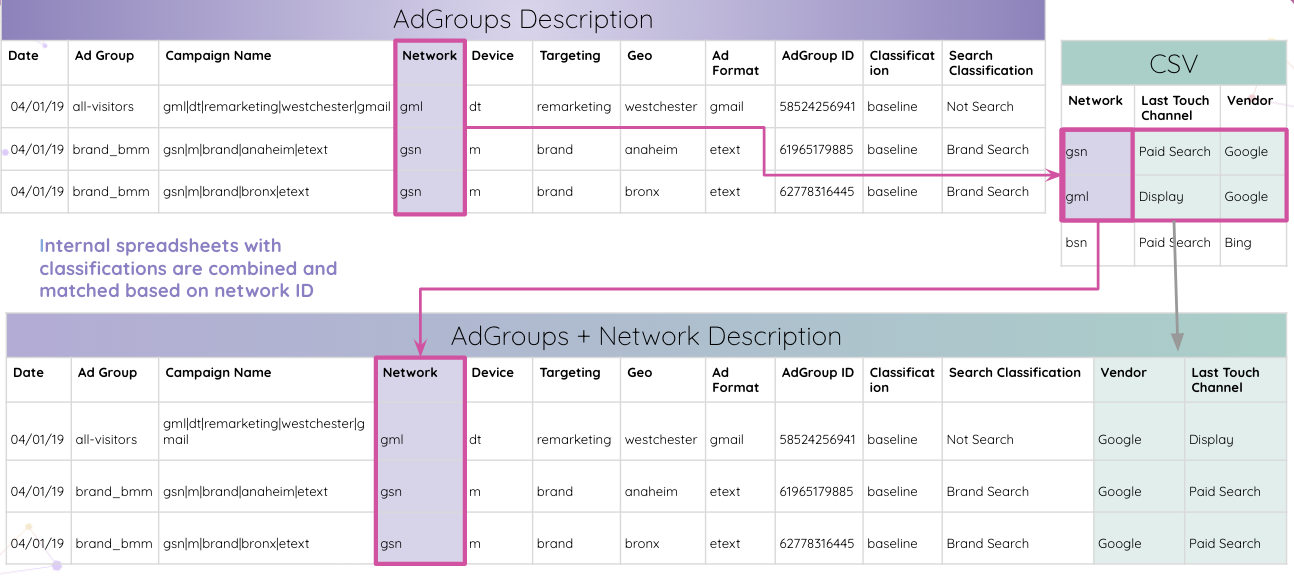
В конце концов, аналитики сопоставляют все таблицы по идентификатору группы объявлений и объединяют их в итоговую таблицу результатов.

Это был лишь один из многих вариантов использования, когда Improvado может нормализовать данные и предоставлять информацию в удобоваримой форме для дальнейших исследований.
Благодаря тому, что все идеи собраны в одном месте, платформа может оптимизировать их для любого инструмента визуализации по вашему выбору. Очищенные и структурированные данные значительно упрощают создание всеобъемлющей многоканальной информационной панели. Например, вот панель инструментов Data Studio, основанная на выводах Improvado:
Нормализуйте данные о маркетинге и продажах с помощью Improvado
Нормализация данных требует времени, но четкое понимание всегда стоит затраченных усилий. Зачем тратить время на нормализацию данных, если можно сразу погрузиться в анализ и значительно сократить время, необходимое для анализа?
Improvado распутывает вашу сеть данных о доходах, сокращает время, затрачиваемое на ручные манипуляции с данными, и обеспечивает высочайшую степень детализации информации. С помощью этой системы ETL вы можете анализировать достоверные данные и создавать информационные панели в режиме реального времени, которые демонстрируют эффективность ваших маркетинговых долларов. Запланируйте звонок, чтобы узнать больше.
Узнайте, как платформа ETL для получения дохода может помочь вам превзойти ваши маркетинговые цели и сэкономить время ваших аналитиков.
