
Veri Normalleştirme: Ham Sayıları Gelire Dönüştürme
Yayınlanan: 2022-05-13Veriler, tüm iş kararlarının merkezinde yer alır. Her an etrafımızı sarıyor. Ne yazık ki, doğrudan veri kaynaklarından aldığınız bilgiler genellikle yapılandırılmamış, parçalanmış ve yanıltıcıdır.
Muhtemelen olası satışları çekmenize, yatırım getirinizi artırmanıza ve gelirinizi artırmanıza yardımcı olabilecek bir yığın sıkıcı veri üzerinde oturuyorsunuz.
Veri normalleştirme, ham rakamlarınızı değer yaratan eyleme geçirilebilir içgörülere dönüştürecektir.
Veri normalleştirme nedir?
Bazı büyük kelimeleri kullanmak için, veri normalleştirme, verileri belirli bir aralığa veya standart formlara sığdıracak şekilde düzenleme sürecidir. Analistlerin yeni içgörüler elde etmesine, veri fazlalığını en aza indirmesine, kopyalardan kurtulmasına ve daha fazla analiz için verileri kolayca sindirilebilir hale getirmesine yardımcı olur.
Ancak, bu tür ifadeler karmaşık ve kafa karıştırıcı olabilir, o yüzden basit ve açıklayıcı bir örnekle özetleyelim.
Elma toplayan bir bahçıvan olduğunuzu hayal edin. Bu yıl 20 ağaçtan 500 elma toplamayı başardınız. Ancak komşunuz 1.000 elma toplamakla övünüyor ve size berbat bir bahçıvan diyor.
Kendi 500 elmayı komşunuzun 1000 elması ile karşılaştırırsanız, çok yetenekli bir bahçıvan olmadığınız anlaşılıyor. Ama komşunuz size böyle bir verim elde etmek için yüz elma ağacı diktiğini hiç söylemedi.
Verileri normalleştirirseniz, komşunuzun tatsız bir durumda olduğu ortaya çıkar. 20 ağaçtan 500 elma ile ağaç başına 25 elma hasat ederken komşunuz ağaç başına sadece 10 elma alıyor. Peki, şimdi kim korkunç bir bahçıvan?
Analiz, birçok normalleştirilmemiş veri tarafından bulandırılabilir, bu nedenle ağaçlar için ormanı göremezsiniz.
Silah kontrol verilerini kullanan başka bir örnek. Veri normalleştirme olmadan bilişsel bir önyargıya kurban gitmenin ne kadar kolay olduğunu bize gösteriyor.

Normalleştirilmiş içgörüler olmadan, kapsamlı bir resim oluşturmak ve araştırılan konu hakkında bilinçli kararlar vermek neredeyse imkansızdır.
Anahtar çıkarımlar:
- Veri normalleştirme, bir veri kümesindeki verileri yeniden düzenleme işlemidir.
- Bu süreç, daha fazla analiz ve veri işlemlerini basitleştirir.
- Veri normalleştirme, araştırılan konunun kapsamlı bir görünümünü elde etmenizi sağlar.
Tamam, ama verileri ne zaman normalleştirmeniz gerekiyor?
Heterojen veriler (veri türleri ve biçimleri yüksek değişkenlik gösteren veriler) nedeniyle kullanıcılar farklı sorunlar yaşarlar. Verileri normalleştirmeniz gerektiğinde başka kullanım durumları da vardır. Bu konuyu pazarlama analistleri açısından ele alalım.
İlk ve en önemlisi, adlandırma kurallarının birleştirilmesidir. Örneğin analistler onlarca pazarlama kanalından veri toplarken çoğu zaman farklı isimler altında aynı metriklerle karşılaşırlar. Sonuç olarak, analistler verileri eşlerken zorluklarla karşılaşırlar.
Örneğin, bir Reddit kullanıcısı, farklı verilerle ilgili sorunlarını şu şekilde açıklıyor.
Diğer bir zorluk, para birimleri veya saat dilimleri gibi farklı verileri tek bir gerçek kaynağında birleştirmek. Reklam harcamanız dolar, euro, sterlin ve diğer birkaç para birimine bölünürken, kapsamlı bir gösterge panosu oluşturamazsınız.
Reddit'te başka bir pazarlamacı bu sorunu şöyle açıklıyor.
Peki, verilerinizi normalleştirmek için doğru zaman ne zaman?
- Veri kümenizdeki metrikleri eşleştirirken farklı adlandırma kuralları vardır.
- Para birimleri, saat dilimleri, tarih biçimleri vb. gibi heterojen verileri eşleştirmeniz gerektiğinde.
- Bazı verilerinizin gereksiz olduğunu fark ettiğinizde ve bunları ortadan kaldırmanız gerekir.
Sıklıkla karıştırılan terimler: veri normalleştirmeye karşı standardizasyon
Veri dönüştürmede standardizasyon ve normalleştirme, sıklıkla karıştırılan iki farklı terimdir.
Normalleştirme, bir veri kümesinin değerlerini [0,1] aralığına düşmelerini sağlamak için yeniden ölçeklendirir. Bu süreç, tüm parametrelerin pozitif bir ölçekte olması gerektiğinde kullanışlıdır.
Standardizasyon, verilerinizi ortalama 0 ve standart sapma 1 olacak şekilde ayarlar. Belirli bir aralığa girmesi gerekmez ve aykırı değerlerden çok daha az etkilenir.
Bu bilgi, pazarlama analistlerinin terimleri karıştırmayı bırakması için fazlasıyla yeterli. Ancak, bu konuya daha derine dalmak isterseniz, iki kavram arasındaki tüm farkları burada bulabilirsiniz.
Verileri normalleştirme ve içgörülerinizi bir araya getirme
Özünde, veri normalleştirme, veri kümenizdeki tüm kayıtlar için standart bir veri formatı oluşturmanızı gerektirir. Algoritmanız, girdiden bağımsız olarak tüm verileri birleşik bir biçimde saklamalıdır.
İşte bazı veri normalleştirme örnekleri:
- Bay HOLmes , Bay Holmes olarak saklanmalıdır.
- Fifth Avenue Sf , 5th Ave, San Francisco olarak saklanmalıdır.
- CTO , Baş Teknik Sorumlu olarak saklanmalıdır.
Verilerinizi normalleştirme, veritabanı normalleştirme ile el ele gider. Bunun ne olduğuna kısaca bir göz atalım.
Veritabanı normalleştirmesi: saflaştırılmış içgörüler için bir ön koşul
Veritabanı normalleştirme, ilişkisel bir veritabanı içindeki tabloları ve veri satırlarını düzenleme işlemidir.
Süreç, tablolar arasında ilişkiler oluşturmayı ve yönetmeyi içerir. Analistler ve veri mühendisleri, veritabanlarını normalleştirirken, verilerin korunmasına yardımcı olan ve daha fazla analiz için daha esnek hale getiren kurallara güvenirler.
Tüm kurallar, veritabanı normalleştirme türleri veya "Normal Formlar" olarak adlandırılır.
Toplamda yedi Normal Form vardır (ilk üçü en sık kullanılanlardır):
- İlk Normal Form (1 NF)
- İkinci Normal Form (2 NF)
- Üçüncü Normal Form (3 NF)
- Boyce Codd Normal Formu (BCNF)
- Dördüncü Normal Form (4 NF)
- Beşinci Normal Form (5 NF)
- Altıncı Normal Form (6 NF)
Verilerinizi normalleştirmeye nasıl yardımcı olduklarını öğrenmek için tüm bu Normal Formları gözden geçirelim.
İlk Normal Form (1NF)
İlk Normal Form, aşağıdaki koşulları karşılamak için bir veri tablosu gerektirir:
- Her tablo hücresinin tek bir değeri olmalıdır.
- Her kayıt benzersiz olmalıdır.
- Sütunların hiçbiri gizli değerler içermemelidir.
Bir örneği gözden geçirelim. Burada çalışan tablosundan iki kaydımız var.

Department_Name hücreleri, bir hücrede birden fazla parametre içerir. Böylece, 1NF'nin ilk kuralını ihlal ediyorlar.
Tablonuzu normalleştirmek ve yinelenen grupları kaldırmak için bu tabloyu iki parçaya ayırmanız gerekir. Normalleştirilmiş tablolar şöyle görünecektir:

İkinci ve Üçüncü Normal Formlar, birincil anahtar sütunlar ve anahtar olmayan sütunlar arasındaki bağımlılıklar etrafında döner.
İkinci Normal Form (2NF)
İkinci Normal Formun temel gereksinimi, tablonun tüm niteliklerinin birincil anahtara bağlı olmasıdır. Başka bir deyişle, ikincil sütunlardaki tüm değerler, birincil sütuna bağımlı olmalıdır.
Not: Birincil anahtar , bir veritabanı kaydını tanımlamaya yardımcı olan benzersiz bir sütun değeridir. Bazı kısıtlamaları ve özellikleri vardır:
- Birincil anahtar değeri NULL olamaz.
- Her tablo için birincil anahtar değeri her zaman benzersiz olmalıdır.
Ek olarak, tüm kısmi bağımlılıklar kaldırılmış ve ayrı bir tabloya yerleştirilmiş olarak tablo zaten 1NF'de olmalıdır.
Bu aşamada, bileşik birincil anahtar en sorunlu konu haline gelir.
Not: Bileşik birincil anahtar, iki veya daha fazla veri sütunundan oluşan birincil anahtardır.
Diyelim ki çalışanlarınızın aldığı derslerin kaydını tutan bir masanız var. Farklı çalışanlar aynı kursa kayıt olabilir. Bu nedenle, benzersiz kaydı tanımlamak için bir bileşik anahtara ihtiyacınız olacak. Tarih sütunu, bileşik anahtarınız için ek parametre olacaktır. Örneğe bir göz atın:
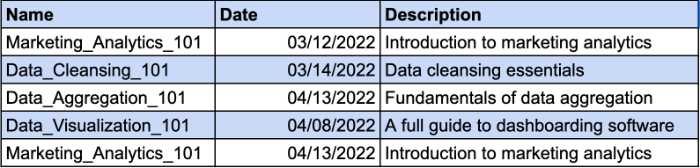
Ancak, Açıklama sütunu işlevsel olarak Ad sütununa bağlıdır. Kursun adını değiştirirseniz, açıklamayı da değiştirmelisiniz. Bu nedenle, kurs açıklamasının 2NF gereksinimlerine uyması için ayrı bir tablo oluşturmanız gerekecek.

Bu şekilde kurs açıklamasına ayrı bir anahtar verebilir ve bileşik anahtar kullanmaktan kurtulabilirsiniz.
Üçüncü Normal Form (3NF)
Üçüncü Normal Form, tablonuzdaki anahtar olmayan tüm sütunların doğrudan birincil anahtara bağlı olmasını gerektirir. Başka bir deyişle, anahtar olmayan sütunlardan herhangi birini kaldırırsanız, kalan sütunlar yine de her kayıt için benzersiz bir tanımlayıcı sağlamalıdır.
3NF'nin temel gereksinimleri şunlardır:
- Tüm tablolar 2NF gereksinimlerine uygundur.
- Birincil olmayan anahtar sütunları yalnızca birincil anahtar sütunlarına bağlı olmalıdır.
- Tabloların geçişli işlevsel bağımlılığı yoktur.
2NF ve 3NF arasındaki temel fark, 3NF'de geçişli bağımlılıkların olmamasıdır. Anahtar olmayan sütun, anahtar olmayan başka bir sütuna bağlı olduğunda geçişli bir bağımlılık vardır.
Not: Geçişli bağımlılık , aynı tablodaki değerler arasında işlevsel bir bağımlılığa neden olan dolaylı bir ilişkidir. İşlevsel bir bağımlılık , nitelikler arasında belirli kısıtlamalar belirler. Bu ilişkide, A niteliği B niteliğinin değerini, B ise A'nın değerini belirler.
Aşağıdaki örneğe bir göz atın:

Burada çalışan kimliği, önceki örneğimizdeki departman kimliğini belirlerken, departman kimliği departman adını belirler. Çalışan kimliği ile departman adı arasında dolaylı bir bağımlılığın oluştuğu yer burasıdır.
3NF gereksinimlerine uymak için tabloyu birden çok parçaya bölmemiz gerekir.
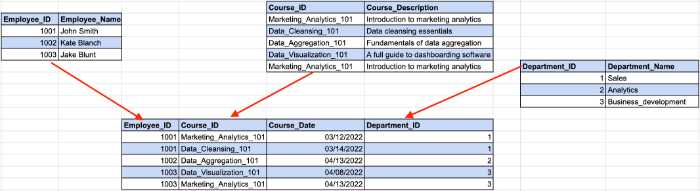
Bu yapı ile, tüm anahtar olmayan sütunlar yalnızca birincil anahtara bağlıdır.
Yedi Normal Form olmasına rağmen, veritabanının 3NF gereksinimlerine uygun hale getirildikten sonra normalize edildiği kabul edilir. Konuyu sonuna kadar ele almak için kalan Normal Formlara hızlı bir genel bakış yapacağız.
Boyce-Codd Normal Formu (BCNF)
3NF'nin daha sağlam bir versiyonudur. Bir BCNF tablosu, tüm 3NF kurallarına uymalı ve çakışan birden çok aday anahtarı içermemelidir.
Dördüncü Normal Form (4NF)
Örneklerinden herhangi biri iki veya daha fazla bağımsız ve çok değerli veri girişi içeriyorsa, veritabanı 4NF olarak kabul edilir.
Beşinci Normal Form (5NF)
Bir tablo, 4NF gereksinimlerine uyuyorsa beşinci Normal Form'a girer ve veri kaybı olmadan daha küçük tablolara bölünemez.
Altıncı Normal Form (6NF)
Altıncı Normal Form, ilişki değişkenlerini indirgenemez bileşenlere ayırmayı amaçlar. Zamansal değişkenler veya diğer aralık verileriyle uğraşırken önemli olabilir.
Veritabanı normalleştirmesi 101 için bu kadar. Artık her şeyin nasıl çalıştığını bildiğinize göre, veri normalleştirmenin içgörülerinize sağladığı faydaları daha iyi anlayabilirsiniz.
Verileri normalleştirmek neden önemlidir?
Daha önce de belirttiğimiz gibi, veri normalleştirmenin ana amacı ve faydası, veritabanlarındaki veri fazlalığını ve tutarsızlıkları azaltmaktır. Ne kadar az tekrara sahip olursanız, veri alımı sırasında oluşabilecek hata ve sorunlar o kadar az olur.
Ancak, veri analistlerine iş akışlarında yardımcı olan daha az belirgin faydalar vardır.
Veri eşleme artık bir zaman emmek değil
Normalleştirilmemiş verilerle uğraşmak zorunda kaldıysanız, birden fazla tablodaki verileri tek bir tabloya eşleme işleminin oldukça sıkıcı olduğunu bilirsiniz.
Birden çok tabloyu birleştirmeyi, kopyalarla uğraşmayı ve birçok boş veri girişini temizlemeyi gerektirir.
Elbette, SQL sorguları veya Python komut dosyaları yazarak verileri manuel olarak normalleştirebilirsiniz. Ancak, otomatikleştirilmiş veri normalleştirme özelliklerine sahip veri eşleme araçları süreci hızlandıracaktır.
Örneğin, Oracle Entegrasyon Bulutu, veri eşleme işlevleri sunar. Araç, buluttaki verileri normalleştirdikten sonra kaynak şemalar için meta veriler oluşturur ve hedef şemadaki her veri nesnesi için bire bir kayıt oluşturur.
Pazarlama içgörüleriyle çalışan analistlerin kendi gizli mücevherleri vardır. Improvado'nun MCDM'si (Pazarlama Ortak Veri Modeli), pazarlama ve satış verilerinin normalleştirilmesi için bir İsviçre çakısı. Araç, farklı adlandırma kurallarını birleştirir, öngörülerinizi normalleştirir ve manuel işlem gerekmeden veri kaynakları ile hedefiniz arasındaki boşluğu kapatır.
️ Kapsamlı listemizle ihtiyaçlarınız için doğru veri haritalama araçlarını bulun ️
Veri depolamayı daha verimli kullanın
Şirketler her geçen gün depolama alanı kaplayan daha fazla veri toplamaktadır. İster bulut depolama, ister şirket içi veri ambarı kullanın, onu etkin bir şekilde kullanmanız gerekir.
Örneğin, AWS S3'te depolanan 100 TB veri size ayda 2.580 ABD dolarına mal olur. Ayrıca Amazon, verileriniz üzerinde gerçekleştirdiğiniz her sorgu için sizden ücret alacaktır. Onlarca gigabaytlık fazla veri, yalnızca depolama hizmetleri faturanızı artırmakla kalmaz, aynı zamanda anlamsız içgörülerin analizi için ödeme yapmanıza da neden olur.
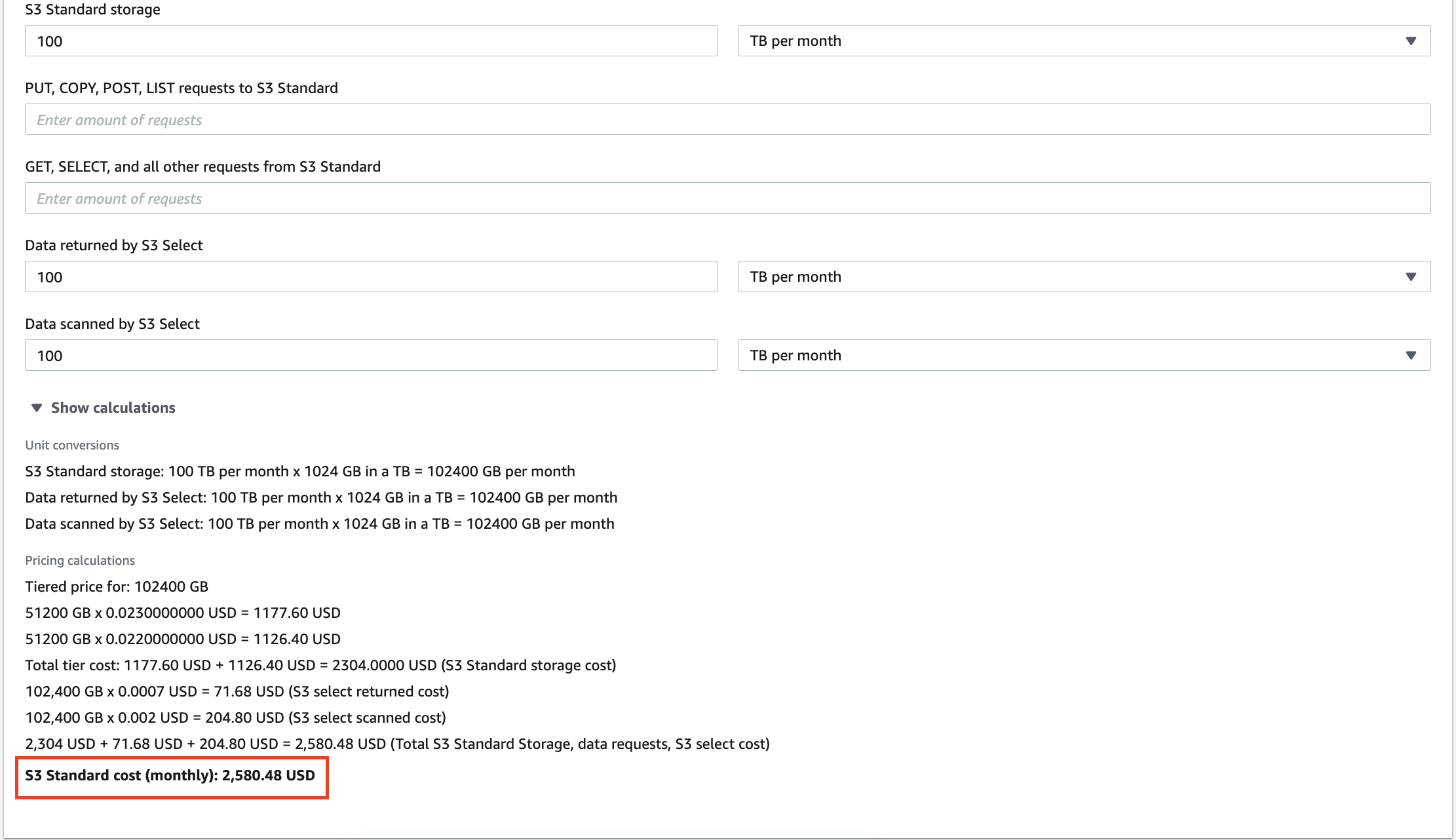
Şirket içi veri ambarlarını ölçeklendirmek de pahalıdır, bu nedenle gereksiz bilgileri temizlemek işletim maliyetlerini ve TCO'yu (Toplam Sahip Olma Maliyeti) azaltmanıza yardımcı olabilir.
İçgörülere ulaşma sürenizi azaltın
Maliyet düşürmenin yanı sıra analistler, analiz üretkenliklerini de artırabilirler.
Terabaytlarca veri üzerinde sorgu yürütmek zaman alır. Sisteminiz sorguyu işlerken, bir fincan kahve içebilir ve iş arkadaşlarınızla siyaset tartışabilirsiniz. Ancak, veri kümenizde bazı tutarsızlıklar olduğundan, sorgu çıktısının anlamsız olması üzücü.

Normalleştirilmiş verilerle her zaman beklenen çıktıyı alırsınız, ancak "N/A", "NaN", "NULL" vb. sürprizlerle karşılaşmazsınız. Ayrıca, yalnızca ilgili verileri ayrıştırdığınızda sistem sorgularınızı daha hızlı gerçekleştirir. Kim bilir, belki bir dahaki sefere kahve makineniz kapuçinonuzu yapmadan önce çıktı alırsınız!
Güvenebileceğiniz panolar oluşturun
Veri görselleştirme, analiz çabalarınızın kapsamlı bir resmini oluşturmanın en iyi yoludur. Ancak, onları zorlu veriler üzerine kurarsanız, gösterge tablolarının değeri yoktur. Kontrol paneli, kopyaları beslerseniz gerçek durumu yansıtmaz.
Bu nedenle, karmaşık kavramları veya performans göstergelerini renkli çizelgeler ve çubuklar prizması aracılığıyla açıklamak istiyorsanız, veri normalleştirme birinci önceliktir.
Farklı ortamlardaki veriler nasıl normalleştirilir?
Veri analistleri farklı araçlarla çalıştıkları için günümüz piyasasında en çok talep gören ortamlarda verilerin nasıl normalleştirileceğini açıklayacağız.
Python'da veriler nasıl normalleştirilir
Python ile çalışan veri bilimcileri ve analistler, verileri işlemek ve düzenlemek için birkaç kitaplık kullanır. İşte aralarında en popüler olanlar:
- pandalar
- Dizi
- TensorFlow
Veri normalleştirme sürecinizi hızlandırmanıza yardımcı olabilecek bu kitaplıkların bazı işlevlerini gözden geçireceğiz.
Veri kümenizdeki sütunları bırakma
Ham veriler genellikle aşırı veya gereksiz kategoriler içerir. Örneğin, gösterimleri, TBM'yi, TO'yu, ROAS'ı ve dönüşümleri içeren bir pazarlama metrikleri veri kümesiyle çalışıyorsunuz, ancak yalnızca bu tablodaki dönüşümlere ihtiyacınız var.
Dönüşümler dışındaki her şey analiz için önemli değilse, fazla sütunları kaldırmanız gerekir. Pandalar, drop() işleviyle bir veri kümesinden sütunları kaldırmanın kolay bir yolunu sunar.
İlk olarak, bırakmak istediğiniz sütunların listesini tanımlamanız gerekir. Bizim durumumuzda, şöyle görünecek:
column_drop_list = ['Gösterimler, 'TBM', 'TO', 'ROAS']
Ardından, işlevi yürütmeniz gerekir:
dataframe_name.drop(column_drop_list, inplace=True, axis=1)
Bu kod satırında, ilk parametre sütun listemizin adı anlamına gelir. Yerinde parametreyi True olarak ayarlamak, Pandaların değişiklikleri doğrudan nesnenize uygulayacağı anlamına gelir. Üçüncü parametre, veri çerçevesinden etiketlerin mi yoksa sütunların mı bırakılacağını belirtir ('0' etiketleri, '1' sütunları belirtir).
Veri kümesini tekrar kontrol ettikten sonra, tüm gereksiz sütunların başarıyla kaldırıldığını göreceksiniz.
Veri alanlarını temizleme
Diğer bir adım, veri alanlarını düzenlemektir. Veri tutarlılığını artırmaya ve verileri standart bir biçime getirmeye yardımcı olur.
Buradaki temel sorun, bir pazarlama platformunun API'sinin %100 doğru veri aktaracağından emin olamamanızdır. Yine de yanlış yerleştirilmiş karakterlerle veya satırda yanıltıcı verilerle karşılaşabilirsiniz.
Tek bir pazarlama kampanyasının yalnızca bir gösterim miktarı olabilir. Bu yüzden değerli sayıları diğer karakterlerden ayırmamız gerekiyor.
Normal ifadeler (regex), veri kümenizdeki tüm rakamları tanımlamanıza yardımcı olabilir. Bu regex oluşturucu, ihtiyaçlarınız için düzenli bir ifade oluşturmanıza ve hemen test etmenize yardımcı olacaktır.
Daha sonra str.extract() fonksiyonu yardımıyla veri setinden gerekli verileri sütunlar halinde çıkartabiliriz.
true_impressions = dataframe_name.str.extract(your_regex) , genişlet = False)
Son olarak, sütununuzu sayısal bir sürüme dönüştürmeniz gerekebilir. Veri çerçevesindeki tüm sütunlar nesne tipine sahip olduğundan, onu sayısal bir değere dönüştürmek daha sonraki hesaplamaları basitleştirecektir. Bunu pd.to_numeric() fonksiyonu yardımıyla yapabilirsiniz.
Veri çerçevesindeki sütunları yeniden adlandırma
Veri kaynakları genellikle analistlerin anlayamadığı adlara sahip sütunları aktarır. Örneğin, TO, herhangi bir nedenle C_T_R_final olarak adlandırılabilir.
Farklı kaynaklardan gelen verileri birleştirip bir bütün olarak analiz ettiğinizde başka bir sorun ortaya çıkıyor. İlk veri kaynağı gösterimleri gösterimler olarak ifade ederken, bir diğeri buna görüntülemeler adını verir. Bu, tüm veri kaynaklarında bütünsel bir resmin hesaplanmasını ve oluşturulmasını zorlaştırır.
Bu nedenle, her şeyi yapılandırmak için sütunlarınızı yeniden adlandırmanız gerekir.
İlk olarak, sütunlarınızın gelecekteki adlarıyla bir sözlük oluşturun. Google Ads ve Facebook Ads'den farklı adlandırma kurallarına sahip izlenimlerimiz olduğunu varsayalım. Bu durumda sözlüğümüz şu şekilde görünecektir:
new_clmn_names = {'Gösterimler': 'Google Ads Gösterimleri',
'Görüntülemeler': 'Facebook Reklam Gösterimleri'}
Ardından, veri çerçevenizde rename() işlevini kullanmalısınız:
dataframe_name.rename(columns=new_clmn_names, inplace=True)
Şimdi, sütunlarınız sözlükte atanmış adlara sahip olacak.
Pandalar, verileri normalleştirmenize yardımcı olabilecek çok daha farklı işlevlere sahiptir. Diğer işlevleri daha iyi anlamak için resmi belgeleri okumanızı öneririz.
Excel'de veriler nasıl normalleştirilir
Excel veya Google E-Tablolar, kullanım kolaylığı ve geniş yetenekleri nedeniyle birçok analist tarafından sevilen güçlü bir araçtır. R veya Python gibi programlama dillerinin daha fazla özellik sunduğuna şüphe yok, ancak elektronik tablolar verileri analiz etme konusunda harika bir iş çıkarıyor.
Ancak tablolarınız heterojen veriler içerebilir ve Excel, öngörüleri normalleştirmek için bir araç seti sağlar.
Fazladan boşlukları kırpma
Büyük bir tablodaki fazla boşlukları belirlemek, manuel olarak yapıldığında zaman kaybıdır. Neyse ki, Excel ve Google E-Tablolar, analistlerin tek bir işlevle bir veri kümesindeki fazladan boşlukları kaldırmasına olanak tanıyan bir TRIM işlevine sahiptir. Aşağıdaki örneğe bir göz atın.

Gördüğünüz gibi, giriş verilerinin kelimeler arasında büyük boşlukları var. TRIM işlevi ile veriler doğru formata getirilir.

Veri kümesindeki boş veri satırlarını kaldırma
Boş hücreler, analiz sırasında gerçek bir kabusa dönüşebilir. Bu yüzden onlarla her zaman önceden ilgilenmelisiniz. İşte bunu nasıl yapacağınız.
- Tüm hücreleri seçin ve araç çubuğundaki "Veri" sekmesine tıklayın.

- Sıralama aralığı menüsünde "Aralığı sütuna göre sırala (Z'den A'ya)" düğmesini tıklayın.
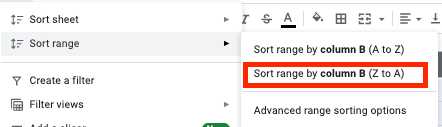
- Artık tablonuzun altındaki tüm boş satırlara sahipsiniz, böylece onları seçip silebilirsiniz.
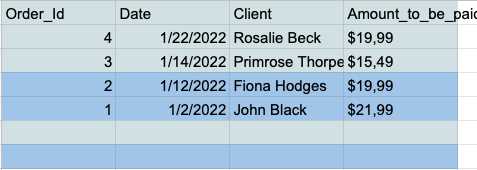
Yinelenenleri kaldırma
Yinelenen veri girişleri, Excel veya Google E-Tablolar'da çalışan analistler için yaygın bir sorundur. Bu nedenle bu araçlar, kopyaları hızlı ve kolay bir şekilde kaldırmak için özel bir özelliğe sahiptir.
Google E-Tablolar, tablonuzda yalnızca benzersiz verileri tutmanıza olanak tanıyan BENZERSİZ bir işleve sahiptir.
Birden çok kopya içeren Ad ve Yaş sütunlarına sahip bu basit tabloya sahip olduğunuzu varsayalım.

Veri kümenizi UNIQUE işlevine besleyerek, yinelenen girişler olmadan temiz bir tablo elde edebilirsiniz.

Metin büyük/küçük harf normalleştirme
Metin dosyalarından verileri içe aktardıktan sonra, adlarda veya başlıklarda genellikle tutarsız metin durumları görürsünüz. Aşağıdaki özellikleri kullanarak verilerinizi Excel veya Google E-Tablolar'da kolayca düzeltebilirsiniz:
- LOWER() - Tüm metni küçük harfe dönüştürür.
- UPPER() - Tüm metni büyük harfe dönüştürür.
- PROPER() - Tüm metni uygun harfe dönüştürür.

Özel kullanım durumunuza bağlı olarak, Excel veya Google E-Tablolar verilerini normalleştirmenin birçok yolu vardır. Bu kılavuzlar, Excel veri normalleştirmesine daha fazla ışık tutmaktadır:
- Excel veri temizleme teknikleri
- Microsoft'un Excel veri normalleştirme ipuçları
Otomatik veri normalleştirme araçları
Programlama dilleri, verilerinizi normalleştirmek için geniş bir araç seti sunar. Ancak, manuel veri normalleştirmenin sınırlamaları vardır.
Her şeyden önce, analistler güçlü mühendislik bilgisine ve gerekli kütüphanelerle ilgili uygulamalı deneyime ihtiyaç duyarlar. Veri bilimcileri ve mühendisleri son derece arzu edilen yeteneklerdir ve maaş çekleri genellikle astronomiktir.
Ayrıca, kodlama zaman alır ve genellikle hatalara açıktır. Bu nedenle, analiz edilen veri setinin bir takip incelemesi olmazsa olmazlardandır. Sonuç olarak, analiz süreci amaçlanandan çok daha fazla zaman alabilir.
Otomatik araçlar, analistlerin zamanından tasarruf sağlar ve daha kesin sonuçlar sunar. Verilerinizi normalleştirme aracına uygun hale getirebilir ve günler değil dakikalar içinde saflaştırılmış öngörüler elde edebilirsiniz.
Şimdi Improvado örneğini ele alalım. Improvado, pazarlama analistlerinin ve satış görevlilerinin farklı verilerini hizalamasına ve içgörüleri tek bir yerde depolamasına yardımcı olan bir gelir ETL platformudur.
Platform, 300'den fazla kaynaktan veri toplar ve analistlerin bunları sıfır çabayla normalleştirmelerine yardımcı olur. Günümüzün pazarlama ve satış araçları pazarı parçalıdır ve farklı platformlar benzer ölçümler için farklı adlandırma kuralları kullanır.
Improvado'nun Pazarlama Ortak Veri Modeli (MCDM), popüler veri kaynaklarının otomatikleştirilmiş çapraz kanal eşleme, tekilleştirme ve BİRLEŞTİRME sağlayan birleşik bir veri modelidir. Ayrıca, ücretli medya kaynaklarını bir araya getirir ve standartlaştırır, analize hazır içgörüleri otomatik olarak veri ambarınıza aktarır.
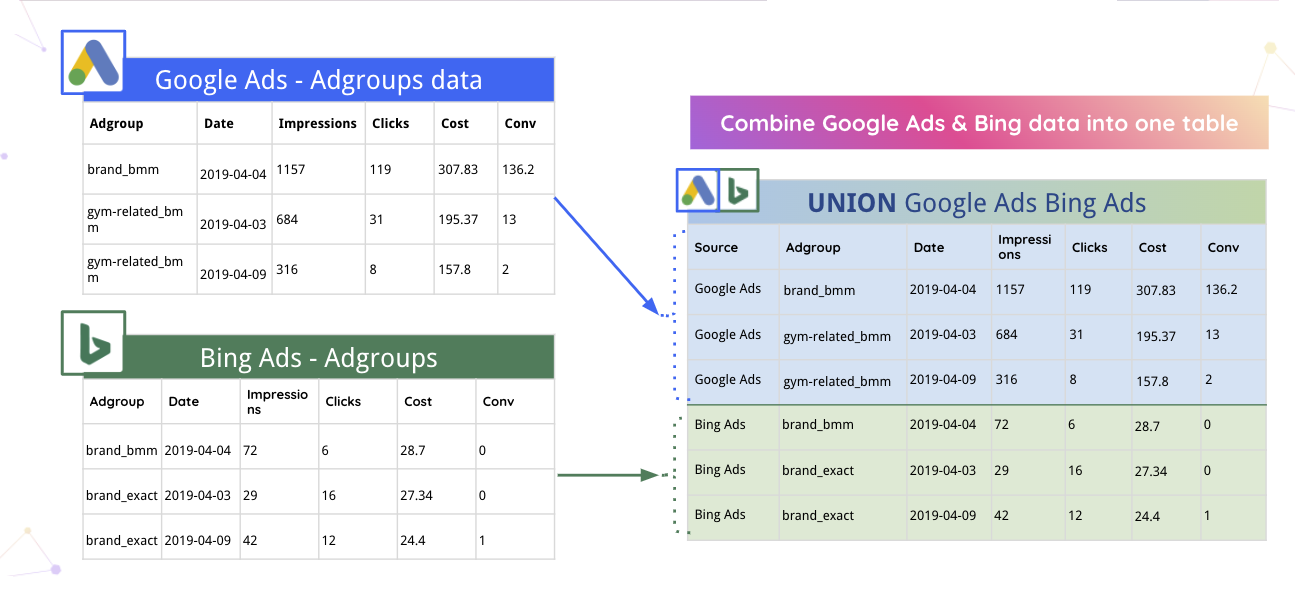
Örneğin Improvado, Google Ads ve Bing verilerini otomatik olarak tek bir tabloda birleştirebilir.
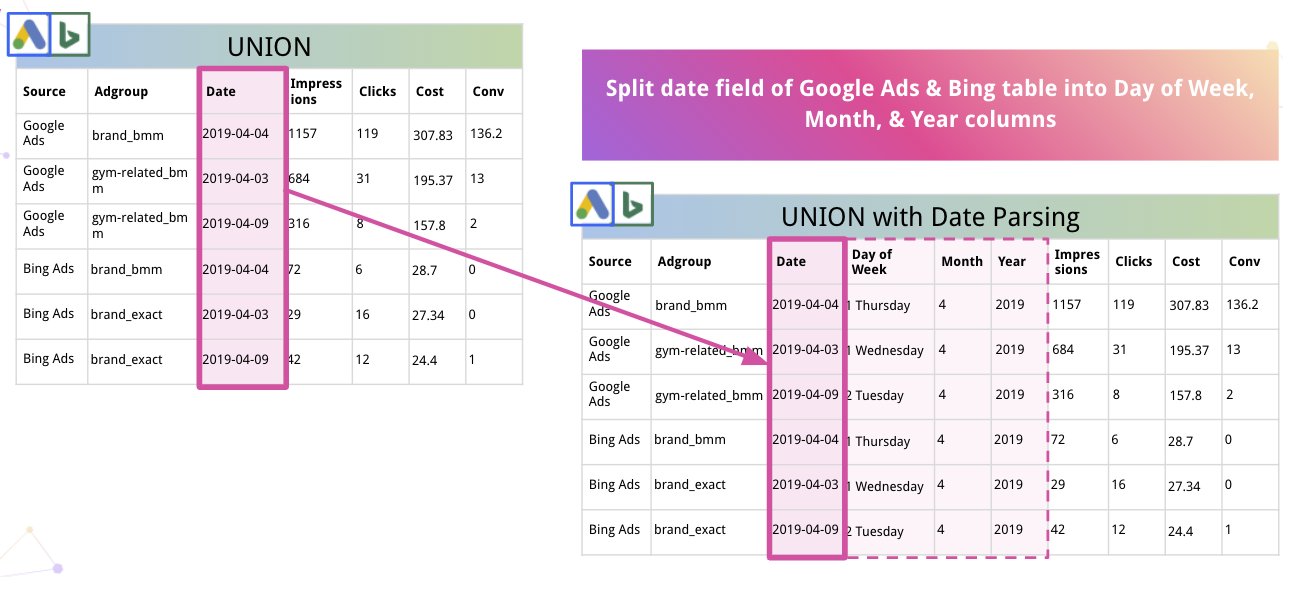
Ayrıca platform, verileri otomatik olarak ayrıştırabilir ve uygun bir biçime dönüştürebilir. Örneğin, Improvado'nun Tarih'i Haftanın Günü, Ay ve Yıl sütunlarına nasıl böldüğü aşağıda açıklanmıştır.
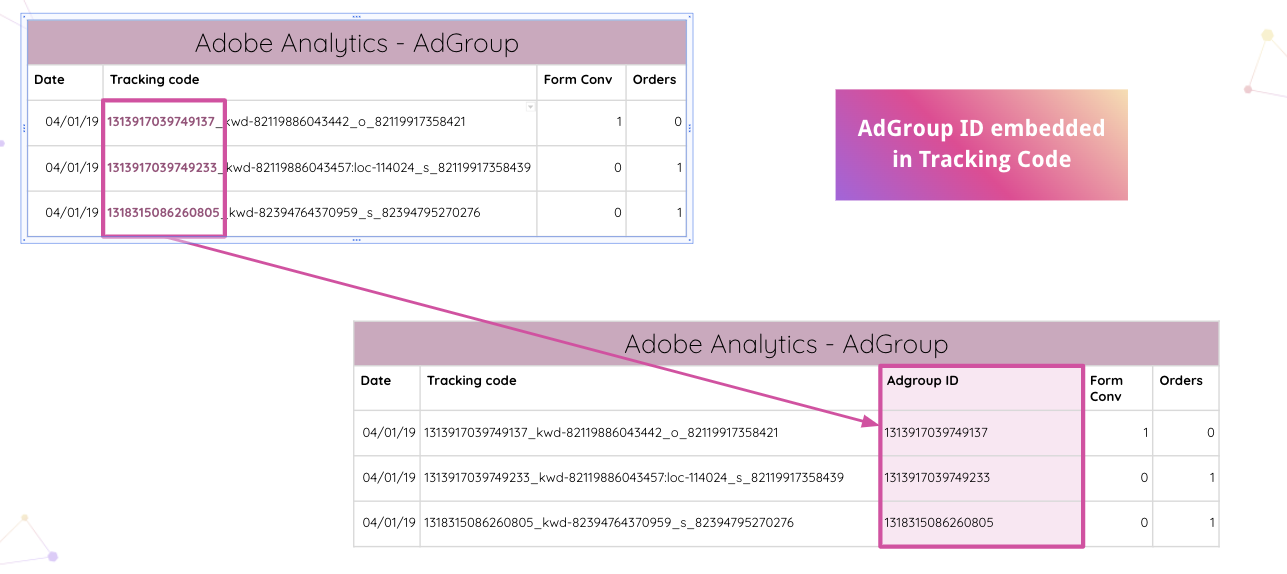
Improvado daha da ileri giderek analistlerin web sitenizdeki Adobe Analytics izleme kodlarını otomatik olarak ayrıştırmasına olanak tanır. Gömülü Reklam Grubu Kimliğini, manuel manipülasyonlar olmadan izleme kodundan çıkarabilirsiniz.
Ardından analistler, dahili elektronik tabloları sınıflandırmalarla birleştirebilir ve bunları ağ kimliğine göre eşleştirebilir.
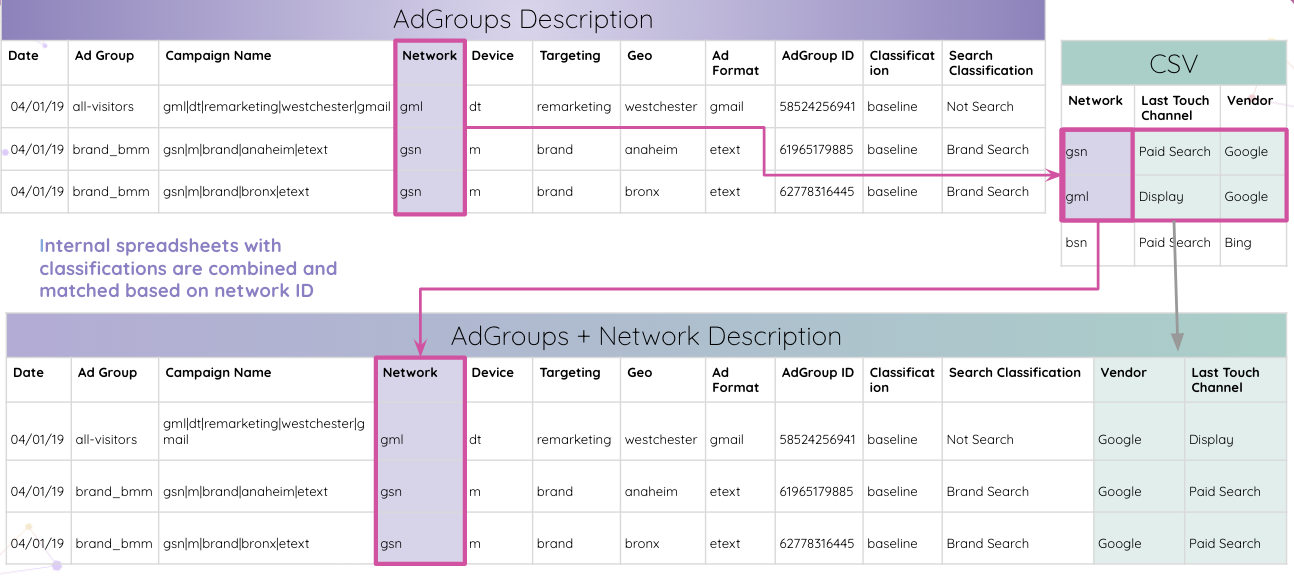
Sonunda analistler, AdGroup ID ile eşleşen tüm tabloları alır ve nihai sonuçlar tablosunda birleştirir.

Bu, Improvado'nun verileri normalleştirebileceği ve daha fazla araştırma için sindirilebilir bir şekilde içgörüler sunabileceği birçok kullanım örneğinden sadece biriydi.
Tüm öngörüleri tek bir yerde toplayan platform, bunları istediğiniz herhangi bir görselleştirme aracına uygun hale getirebilir. Arıtılmış ve yapılandırılmış veriler, kapsamlı bir çapraz kanal panosu oluşturmayı çok daha kolay hale getirir. Örneğin, Improvado'nun içgörülerine dayalı bir Data Studio panosu aşağıda verilmiştir:
Improvado ile pazarlama ve satış verilerini normalleştirin
Veri normalleştirme zaman alır, ancak net bilgiler her zaman çabaya değer. Doğrudan analize dalıp içgörüye ulaşma sürenizi önemli ölçüde azaltabiliyorsanız, neden veri normalleştirmeyle zamanınızı boşa harcayasınız ki?
Improvado, gelir verileri ağınızı çözer, manuel veri manipülasyonları için harcanan süreyi azaltır ve en yüksek düzeyde içgörü sağlar. Bu ETL sistemiyle, güvenilir verileri analiz edebilir ve pazarlama bütçenizin etkinliğini gösteren gerçek zamanlı gösterge tabloları oluşturabilirsiniz. Daha fazla bilgi edinmek için bir arama planlayın.
Bir gelir ETL platformunun pazarlama hedeflerinizi aşmanıza ve analistlerinizin zamanından tasarruf etmenize nasıl yardımcı olabileceğini öğrenin.
