
Normalisation des données : conversion des chiffres bruts en revenus
Publié: 2022-05-13Les données sont au cœur de toutes les décisions commerciales. Il nous entoure à chaque tournant. Malheureusement, les informations que vous obtenez directement des sources de données sont souvent non structurées, fragmentées et trompeuses.
Vous êtes probablement assis sur une pile de données ennuyeuses qui pourraient vous aider à attirer des prospects, à améliorer votre retour sur investissement et à augmenter vos revenus.
La normalisation des données transformera vos chiffres bruts en informations exploitables qui génèrent de la valeur.
Qu'est-ce que la normalisation des données ?
Pour utiliser de grands mots, la normalisation des données est le processus d'organisation des données de manière à les intégrer dans une gamme spécifique ou des formes standard. Il aide les analystes à acquérir de nouvelles informations, à minimiser la redondance des données, à éliminer les doublons et à rendre les données facilement assimilables pour une analyse plus approfondie.
Cependant, une telle formulation peut être compliquée et déroutante, alors résumons-la à un exemple simple et illustratif.
Imaginez que vous êtes un jardinier récoltant des pommes. Cette année, vous avez réussi à récolter 500 pommes sur 20 arbres . Cependant, votre voisin se vante d'avoir cueilli 1 000 pommes et vous traite de mauvais jardinier.
Si vous comparez vos 500 pommes aux 1 000 pommes de votre voisin, il peut sembler que vous n'êtes pas un jardinier très doué. Mais votre voisin ne vous a jamais dit qu'il avait planté une centaine de pommiers pour obtenir un tel rendement.
Si vous normalisez les données, il se révèle que votre voisin est dans une situation désagréable. Avec 500 pommes de 20 arbres, vous récoltez 25 pommes par arbre , tandis que votre voisin ne récolte que 10 pommes par arbre. Alors, qui est un mauvais jardinier maintenant ?
L'analyse peut être brouillée par de nombreuses données non normalisées, de sorte que vous ne pouvez pas voir la forêt pour les arbres.
Voici un autre exemple utilisant des données de contrôle des armes à feu. Cela nous montre à quel point il est facile d'être victime d'un biais cognitif sans normalisation des données.

Sans informations normalisées, il est presque impossible de dresser un tableau complet et de prendre des décisions éclairées sur le sujet de recherche.
Points clés à retenir:
- La normalisation des données est un processus de réorganisation des données dans un ensemble de données.
- Ce processus simplifie les analyses ultérieures et les opérations de données.
- La normalisation des données vous garantit une vue complète du sujet recherché.
Ok, mais quand avez-vous besoin de normaliser les données ?
Les utilisateurs rencontrent différents problèmes en raison de données hétérogènes (données avec une grande variabilité de types et de formats de données). Il existe d'autres cas d'utilisation dans lesquels vous devez normaliser des données. Considérons cette question du point de vue des analystes marketing.
D'abord et avant tout, l'unification des conventions de nommage. Par exemple, lors de la collecte de données à partir de dizaines de canaux marketing, les analystes rencontrent souvent les mêmes mesures sous des noms différents. Par conséquent, les analystes rencontrent des difficultés lors de la cartographie des données.
Par exemple, voici comment un utilisateur de Reddit explique ses problèmes avec des données disparates.
Un autre défi consiste à consolider des données disparates, telles que des devises ou des fuseaux horaires, en une seule source de vérité. Vous ne pouvez tout simplement pas créer un tableau de bord perspicace alors que vos dépenses publicitaires sont divisées en dollars, euros, livres et quelques autres devises.
Voici comment un autre spécialiste du marketing décrit ce problème sur Reddit.
Alors, quel est le bon moment pour normaliser vos données ?
- Lorsque les métriques correspondantes de votre ensemble de données ont des conventions de dénomination différentes.
- Lorsque vous devez faire correspondre des données hétérogènes, telles que des devises, des fuseaux horaires, des formats de date, etc.
- Lorsque vous remarquez que certaines de vos données sont redondantes et que vous devez les éliminer.
Termes souvent confondus : normalisation des données vs standardisation
Dans la transformation de données, standardisation et normalisation sont deux termes différents souvent confondus.
La normalisation remet à l'échelle les valeurs d'un ensemble de données pour les faire tomber dans une plage de [0,1] . Ce processus est utile lorsque vous avez besoin que tous les paramètres soient sur une échelle positive.
La standardisation ajuste vos données pour avoir une moyenne de 0 et un écart type de 1 . Il n'a pas à tomber dans une plage spécifique et est beaucoup moins affecté par les valeurs aberrantes.
Ces informations sont plus que suffisantes pour que les analystes marketing cessent de confondre les termes. Cependant, si vous souhaitez approfondir ce sujet, vous pouvez trouver toutes les différences entre les deux concepts ici.
Comment normaliser les données et rassembler vos informations
À la base, la normalisation des données vous oblige à créer un format de données standard pour tous les enregistrements de votre ensemble de données. Votre algorithme doit stocker toutes les données dans un format unifié sans tenir compte de l'entrée.
Voici quelques exemples de normalisation de données :
- Mister HOLmES devrait être stocké sous le nom de M. Holmes.
- La Cinquième Avenue Sf devrait être stockée sous le nom de 5th Ave, San Francisco.
- Le CTO doit être stocké en tant que directeur technique.
La normalisation de vos données va de pair avec la normalisation de la base de données. Voyons un bref aperçu de ce que c'est.
Normalisation de la base de données : une condition préalable pour des informations purifiées
La normalisation de la base de données est le processus d'organisation des tables et des lignes de données dans une base de données relationnelle.
Le processus comprend la création et la gestion des relations entre les tables. Lors de la normalisation des bases de données, les analystes et les ingénieurs de données s'appuient sur des règles qui aident à protéger les données et à les rendre plus flexibles pour une analyse plus approfondie.
Toutes les règles sont déclarées par des types de normalisation de base de données ou des « formes normales ».
Il existe sept formes normales au total (les trois premières sont les plus fréquemment utilisées) :
- Première forme normale (1 NF)
- Deuxième forme normale (2 NF)
- Troisième forme normale (3 NF)
- Forme normale de Boyce Codd (BCNF)
- Quatrième forme normale (4 NF)
- Cinquième forme normale (5 NF)
- Sixième forme normale (6 NF)
Passons en revue toutes ces formes normales pour savoir comment elles aident à normaliser vos données.
Première forme normale (1NF)
La première forme normale nécessite une table de données pour répondre aux conditions suivantes :
- Chaque cellule du tableau doit avoir une valeur unique.
- Chaque enregistrement doit être unique.
- Aucune des colonnes ne doit contenir de valeurs masquées.
Reprenons un exemple. Ici, nous avons deux enregistrements de la table des employés.

Les cellules Department_Name contiennent plusieurs paramètres dans une cellule. Ainsi, ils violent la première règle de l'1NF.
Vous devez diviser ce tableau en deux parties pour normaliser votre tableau et supprimer les groupes répétés. Les tables normalisées ressembleront à ceci :

Les deuxième et troisième formes normales tournent autour des dépendances entre les colonnes de clé primaire et les colonnes non clés.
Deuxième forme normale (2NF)
La principale exigence de la deuxième forme normale est que tous les attributs de la table doivent dépendre de la clé primaire. En d'autres termes, toutes les valeurs des colonnes secondaires doivent avoir une dépendance sur la colonne principale.
Remarque : Une clé primaire est une valeur de colonne unique qui permet d'identifier un enregistrement de base de données. Il a quelques restrictions et attributs :
- Une valeur de clé primaire ne peut pas être NULL.
- Une valeur de clé primaire doit toujours être unique pour chaque table.
De plus, la table doit déjà être en 1NF avec toutes les dépendances partielles supprimées et placées dans une table séparée.
À ce stade, une clé primaire composite devient le problème le plus problématique.
Remarque : Une clé primaire composite est une clé primaire constituée de deux colonnes de données ou plus.
Imaginons que vous disposiez d'un tableau qui garde une trace des cours suivis par vos employés. Différents employés peuvent s'inscrire au même cours. C'est pourquoi vous aurez besoin d'une clé composite pour identifier l'enregistrement unique. La colonne Date sera le paramètre supplémentaire de votre clé composée. Jetez un oeil à l'exemple:
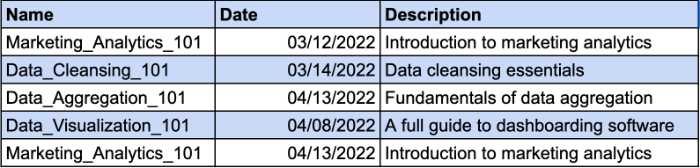
Cependant, la colonne Description dépend fonctionnellement de la colonne Nom. Si vous modifiez le nom du cours, vous devez également modifier la description. Vous devrez donc créer un tableau séparé pour que la description du cours soit conforme aux exigences 2NF.

C'est ainsi que vous pouvez donner à la description du cours une clé distincte et éviter d'utiliser une clé composée.
Troisième forme normale (3NF)
La troisième forme normale nécessite que toutes les colonnes non clés de votre table dépendent directement de la clé primaire. En d'autres termes, si vous supprimez l'une des colonnes non clés, les colonnes restantes doivent toujours fournir un identifiant unique pour chaque enregistrement.
Voici les principales exigences du 3NF :
- Toutes les tables sont conformes aux exigences 2NF.
- Les colonnes de clé non primaire ne doivent dépendre que des colonnes de clé primaire.
- Les tables n'ont pas de dépendance fonctionnelle transitive.
La principale différence entre 2NF et 3NF est que dans 3NF, il n'y a pas de dépendances transitives. Une dépendance transitive existe lorsque la colonne non clé dépend d'une autre colonne non clé.
Remarque : Une dépendance transitive est une relation indirecte entre des valeurs d'une même table qui provoque une dépendance fonctionnelle. Une dépendance fonctionnelle définit des contraintes particulières entre les attributs. Dans cette relation, l'attribut A détermine la valeur de l'attribut B, tandis que B détermine la valeur de A.
Jetez un oeil à l'exemple ci-dessous:

Ici, l'ID de l'employé détermine l'ID du service de notre exemple précédent, tandis que l'ID du service détermine le nom du service. C'est ici qu'une dépendance indirecte entre l'ID de l'employé et le nom du service se produit.
Pour se conformer aux exigences 3NF, nous devons diviser la table en plusieurs parties.
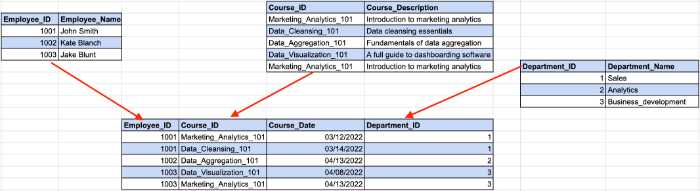
Avec cette structure, toutes les colonnes sans clé dépendent uniquement de la clé primaire.
Même s'il existe sept formes normales, la base de données est considérée comme normalisée après s'être conformée aux exigences 3NF. Nous ferons un bref aperçu des formes normales restantes pour couvrir le sujet jusqu'à la fin.
Forme normale de Boyce-Codd (BCNF)
C'est une version plus robuste du 3NF. Une table BCNF doit être conforme à toutes les règles 3NF et ne pas avoir plusieurs clés candidates qui se chevauchent.
Quatrième forme normale (4NF)
La base de données est considérée comme un 4NF si l'une de ses instances contient au moins deux entrées de données indépendantes et à valeurs multiples.
Cinquième forme normale (5NF)
Une table tombe dans la cinquième forme normale si elle est conforme aux exigences 4NF, et elle ne peut pas être divisée en tables plus petites sans perdre de données.
Sixième forme normale (6NF)
La sixième forme normale est destinée à décomposer les variables de relation en composantes irréductibles. Cela peut être important lorsqu'il s'agit de variables temporelles ou d'autres données d'intervalle.
C'est tout pour la normalisation des bases de données 101. Maintenant que vous savez comment tout fonctionne, vous pouvez mieux comprendre les avantages que la normalisation des données apporte à vos informations.
Pourquoi est-il important de normaliser les données ?
Comme nous l'avons déjà mentionné, le principal objectif et avantage de la normalisation des données est de réduire la redondance des données et les incohérences dans les bases de données. Moins vous avez de doublons, moins il y a d'erreurs et de problèmes qui peuvent survenir lors de la récupération des données.
Cependant, il existe des avantages moins évidents qui aident les analystes de données dans leur flux de travail.
Le mappage des données n'est plus une perte de temps
Si vous avez déjà eu à gérer des données non normalisées, vous savez que le processus de mappage des données de plusieurs tables en une seule est assez fastidieux.
Cela nécessite de joindre plusieurs tables, de gérer les doublons et de nettoyer de nombreuses entrées de données vides.
Bien sûr, vous pouvez normaliser les données manuellement en écrivant des requêtes SQL ou des scripts Python. Cependant, les outils de cartographie des données avec des capacités de normalisation automatisée des données accéléreront le processus.
Par exemple, Oracle Integration Cloud propose des fonctionnalités de mappage de données. Après avoir normalisé les données dans le cloud, l'outil crée ensuite des métadonnées pour les schémas source et crée un enregistrement un à un pour chaque objet de données dans le schéma cible.
Les analystes travaillant avec des informations marketing ont leurs propres trésors cachés. Le MCDM (Marketing Common Data Model) d'Improvado est un couteau suisse pour la normalisation des données marketing et commerciales. L'outil unifie les conventions de dénomination disparates, normalise vos informations et comble le fossé entre les sources de données et votre destination sans aucune action manuelle requise.
️ Trouvez les bons outils de cartographie de données pour vos besoins grâce à notre liste complète ️
Utiliser le stockage de données plus efficacement
Chaque jour qui passe, les entreprises collectent de plus en plus de données qui occupent de l'espace de stockage. Que vous utilisiez le stockage dans le cloud ou un entrepôt de données sur site, vous devez l'utiliser efficacement.
Par exemple, 100 To de données stockées dans AWS S3 vous coûteront 2 580 $ par mois. De plus, Amazon vous facturera pour chaque requête que vous effectuez sur vos données. Des dizaines de gigaoctets de données redondantes augmenteront non seulement votre facture pour les services de stockage, mais vous feront également payer pour l'analyse d'informations dénuées de sens.
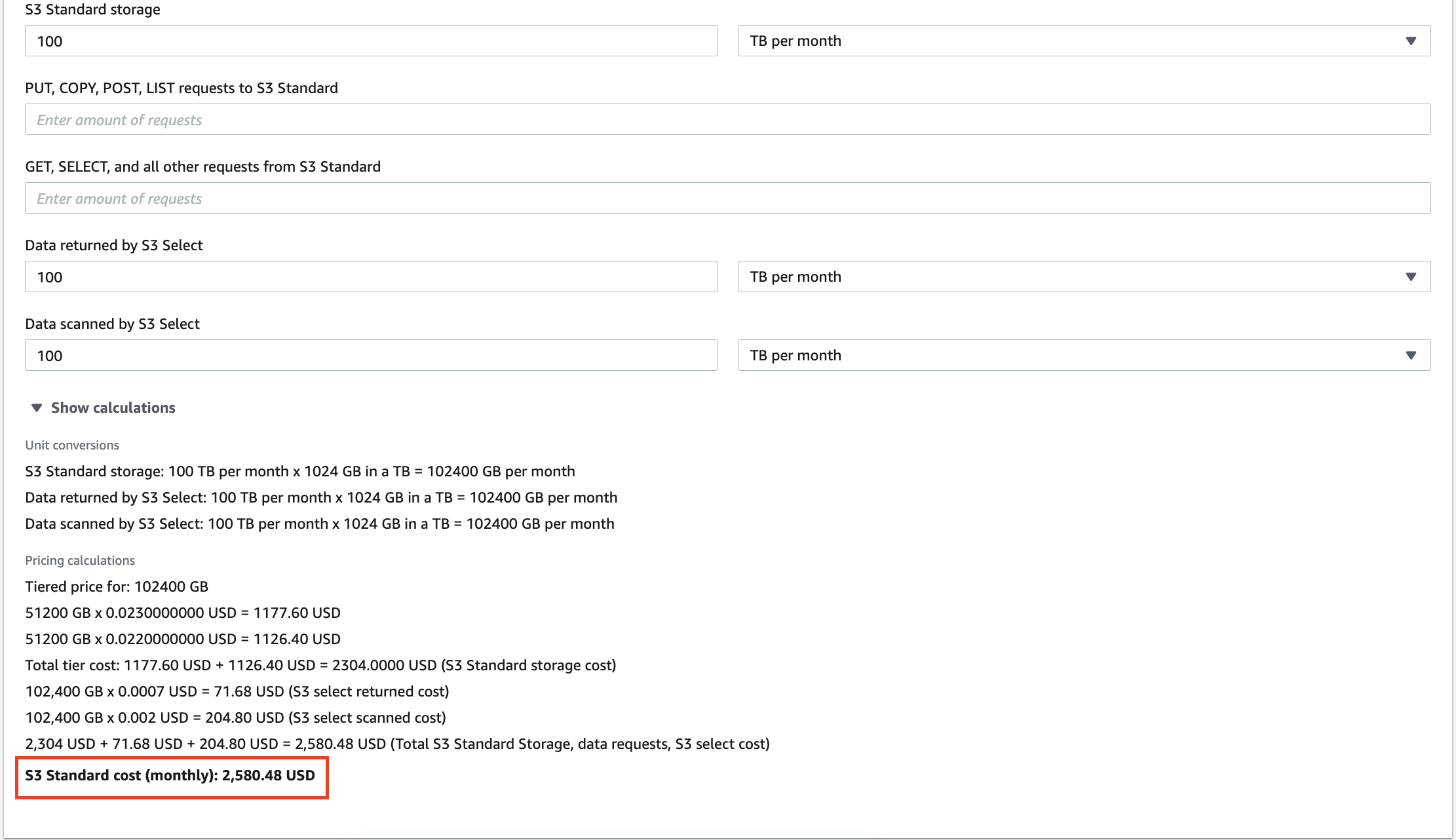
La mise à l'échelle des entrepôts de données sur site est également coûteuse, donc la suppression des informations inutiles peut vous aider à réduire les coûts opérationnels et le TCO (coût total de possession).

Réduisez vos délais d'obtention d'insights
Outre la réduction des coûts, les analystes peuvent également augmenter leur productivité d'analyse.
L'exécution de requêtes sur des téraoctets de données prend du temps. Pendant que votre système traite la requête, vous pouvez vous sentir libre de boire une tasse de café et de discuter de politique avec vos collègues. Mais c'est dommage lorsque la sortie de la requête est inutile car vous aviez des incohérences dans votre ensemble de données.
Avec des données normalisées, vous obtenez toujours la sortie attendue, mais sans surprises telles que "N/A", "NaN", "NULL", etc. De plus, le système exécute vos requêtes plus rapidement lorsque vous analysez uniquement les données pertinentes. Qui sait, peut-être que la prochaine fois vous obtiendrez la sortie avant que votre machine à café ne prépare votre cappuccino !
Créez des tableaux de bord auxquels vous pouvez faire confiance
La visualisation des données est le meilleur moyen de créer une image complète de vos efforts d'analyse. Cependant, les tableaux de bord manquent de valeur si vous les construisez sur des données difficiles. Le tableau de bord ne reflétera pas le véritable état des choses si vous l'alimentez en doublons.
C'est pourquoi la normalisation des données est une priorité absolue si vous souhaitez expliquer des concepts complexes ou des indicateurs de performance à travers le prisme de graphiques et de barres colorés.
Comment normaliser les données dans différents environnements
Étant donné que les analystes de données travaillent avec différents outils, nous expliquerons comment normaliser les données dans les environnements les plus demandés du marché actuel.
Comment normaliser des données en Python
Les data scientists et les analystes travaillant avec Python utilisent plusieurs bibliothèques pour manipuler les données et les ranger. Voici les plus populaires d'entre eux :
- Pandas
- Numpy
- TensorFlow
Nous passerons en revue certaines des fonctionnalités de ces bibliothèques qui pourraient vous aider à accélérer votre processus de normalisation des données.
Suppression de colonnes dans votre ensemble de données
Les données brutes contiennent souvent des catégories excessives ou inutiles. Par exemple, vous travaillez avec un ensemble de données de mesures marketing qui incluent les impressions, le CPC, le CTR, le ROAS et les conversions, mais vous n'avez besoin que des conversions de ce tableau.
Si tout, à part les conversions, n'est pas important pour l'analyse, vous devez supprimer les colonnes excessives. Pandas offre un moyen simple de supprimer des colonnes d'un ensemble de données avec la fonction drop().
Tout d'abord, vous devez définir la liste des colonnes que vous souhaitez supprimer. Dans notre cas, cela ressemblera à ceci :
column_drop_list = ['Impressions, 'CPC', 'CTR', 'ROAS']
Ensuite, vous devez exécuter la fonction :
dataframe_name.drop(column_drop_list, inplace=True, axis=1)
Dans cette ligne de code, le premier paramètre représente le nom de notre liste de colonnes. Définir le paramètre inplace sur True signifie que Pandas appliquera les modifications directement à votre objet. Le troisième paramètre indique s'il faut supprimer des étiquettes ou des colonnes du bloc de données ("0" pour les étiquettes, "1" pour les colonnes).
Après avoir vérifié à nouveau l'ensemble de données, vous verrez que toutes les colonnes redondantes ont été supprimées avec succès.
Nettoyer les champs de données
Une autre étape consiste à ranger les champs de données. Cela aide à augmenter la cohérence des données et à obtenir des données dans un format standardisé.
Le principal problème ici est que vous ne pouvez pas être sûr que l'API d'une plateforme marketing transférera des données précises à 100 %. Vous pourriez toujours rencontrer des caractères mal placés ou des données trompeuses sur toute la ligne.
Une seule campagne marketing ne peut avoir qu'un seul nombre d'impressions. C'est pourquoi nous devons séparer les nombres précieux des autres caractères.
Les expressions régulières (regex) peuvent vous aider à identifier tous les chiffres de votre ensemble de données. Ce générateur de regex vous aidera à créer une expression régulière pour vos besoins et à la tester immédiatement.
Ensuite, à l'aide de la fonction str.extract(), nous pouvons extraire les données requises de l'ensemble de données sous forme de colonnes.
true_impressions = dataframe_name.str.extract(your_regex) , expand = False)
Enfin, vous devrez peut-être convertir votre colonne en une version numérique. Étant donné que toutes les colonnes du bloc de données ont le type d'objet, sa conversion en une valeur numérique simplifiera les calculs ultérieurs. Vous pouvez le faire à l'aide de la fonction pd.to_numeric().
Renommer les colonnes dans le bloc de données
Les sources de données transfèrent souvent des colonnes avec des noms que les analystes ne peuvent pas comprendre. Par exemple, CTR peut être appelé C_T_R_final pour une raison quelconque.
Un autre problème se révèle lorsque vous fusionnez des données provenant de différentes sources et que vous les analysez dans leur ensemble. Alors que la première source de données fait référence aux impressions en tant qu'imps, une autre l'appelle vues. Il est donc difficile de calculer et de créer une image globale de toutes les sources de données.
C'est pourquoi vous devez renommer vos colonnes pour que tout soit structuré.
Tout d'abord, créez un dictionnaire avec les futurs noms de vos colonnes. Supposons que nous ayons des impressions de Google Ads et de Facebook Ads avec des conventions de dénomination différentes. Dans ce cas, notre dictionnaire se présentera comme suit :
new_clmn_names = {'Imps' : 'Impressions Google Ads',
'Vues' : 'Impressions des publicités Facebook'}
Ensuite, vous devez utiliser la fonction rename() sur votre data frame :
dataframe_name.rename(columns=new_clmn_names, inplace=True)
Maintenant, vos colonnes auront des noms attribués dans le dictionnaire.
Pandas a beaucoup plus de fonctions différentes qui peuvent vous aider à normaliser les données. Nous vous recommandons de lire la documentation officielle pour mieux comprendre les autres fonctionnalités.
Comment normaliser les données dans Excel
Excel ou Google Sheets est un outil puissant apprécié par de nombreux analystes en raison de sa facilité d'utilisation et de ses fonctionnalités étendues. Il ne fait aucun doute que les langages de programmation, tels que R ou Python, ont plus de fonctionnalités à offrir, mais les feuilles de calcul font un excellent travail d'analyse des données.
Cependant, vos tables peuvent contenir des données hétérogènes et Excel fournit un ensemble d'outils pour normaliser les informations.
Couper les espaces supplémentaires
L'identification des espaces excessifs dans une grande table est une perte de temps lorsqu'elle est effectuée manuellement. Heureusement, Excel et Google Sheets ont une fonction TRIM qui permet aux analystes de supprimer les espaces supplémentaires dans un ensemble de données avec une seule fonction. Jetez un oeil à l'exemple ci-dessous.

Comme vous pouvez le voir, les données d'entrée ont un grand espace blanc entre les mots. Avec la fonction TRIM, les données sont mises au bon format.

Suppression des lignes de données vides dans l'ensemble de données
Les cellules vides peuvent dégénérer en un véritable cauchemar pendant l'analyse. C'est pourquoi vous devez toujours les traiter au préalable. Voici comment procéder.
- Choisissez toutes les cellules et cliquez sur l'onglet "Données" dans la barre d'outils.

- Cliquez sur le bouton "Trier la plage par colonne (Z à A)" dans le menu de la plage de tri.
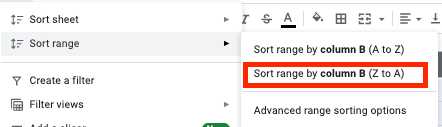
- Vous avez maintenant toutes les lignes vides au bas de votre tableau, vous pouvez donc simplement les sélectionner et les supprimer.
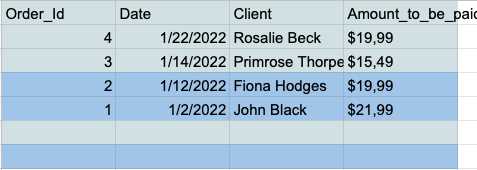
Suppression des doublons
Les entrées de données en double sont un problème courant pour les analystes travaillant dans Excel ou Google Sheets. C'est pourquoi ces outils disposent d'une fonctionnalité dédiée pour supprimer les doublons de manière simple et rapide.
Google Sheets a une fonction UNIQUE qui vous permet de ne conserver que des données uniques dans votre tableau.
Supposons que vous disposiez de cette table simple avec des colonnes Nom et Âge contenant plusieurs doublons.

Vous pouvez obtenir une table propre sans aucune entrée en double en alimentant votre ensemble de données avec la fonction UNIQUE.

Normalisation de la casse du texte
Après avoir importé des données à partir de fichiers texte, vous trouverez souvent des cas de texte incohérents dans les noms ou les titres. Vous pouvez facilement corriger vos données dans Excel ou Google Sheets en utilisant les fonctionnalités suivantes :
- LOWER() - Convertit tout le texte en minuscules.
- UPPER() - Convertit tout le texte en majuscules.
- PROPER() - Convertit tout le texte en cas approprié.

Selon votre cas d'utilisation particulier, il existe de nombreuses façons de normaliser les données Excel ou Google Sheets. Ces guides éclairent davantage la normalisation des données Excel :
- Techniques de nettoyage des données Excel
- Conseils de normalisation des données Excel de Microsoft
Outils automatisés de normalisation des données
Les langages de programmation offrent un large éventail d'outils pour normaliser vos données. Cependant, la normalisation manuelle des données a ses limites.
Tout d'abord, les analystes ont besoin de solides connaissances en ingénierie et d'une expérience pratique des bibliothèques requises. Les data scientists et les ingénieurs sont des talents hautement recherchés, et leurs salaires sont souvent astronomiques.
De plus, le codage prend du temps et est souvent sujet à des erreurs. Ainsi, un examen de suivi de l'ensemble de données analysé est indispensable. Finalement, le processus d'analyse peut prendre beaucoup plus de temps que prévu.
Les outils automatisés font gagner du temps aux analystes et offrent des résultats plus précis. Vous pouvez rationaliser vos données vers l'outil de normalisation et obtenir des informations purifiées en quelques minutes, et non en quelques jours.
Prenons l'exemple d'Improvado. Improvado est une plate-forme ETL de revenus qui aide les analystes marketing et les vendeurs à aligner leurs données disparates et à stocker des informations en un seul endroit.
La plate-forme rassemble des données provenant de plus de 300 sources et aide les analystes à les normaliser sans effort. Le marché actuel des outils de marketing et de vente est fragmenté et différentes plates-formes utilisent différentes conventions de dénomination pour des métriques similaires.
Le Marketing Common Data Model (MCDM) d'Improvado est un modèle de données unifié qui fournit un mappage, une déduplication et un UNIONing cross-canal automatisés des sources de données populaires. En outre, il assemble et standardise les sources de médias payants ensemble, transférant automatiquement des informations prêtes pour l'analyse vers votre entrepôt de données.
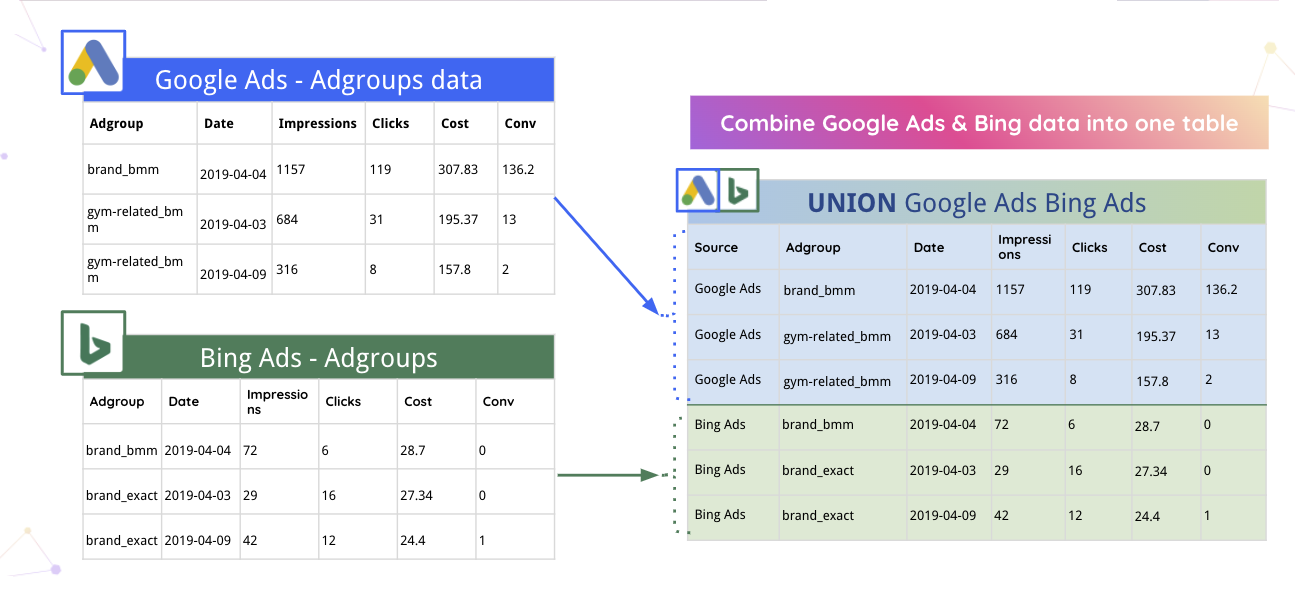
Par exemple, Improvado peut automatiquement fusionner les données Google Ads et Bing dans un seul tableau.
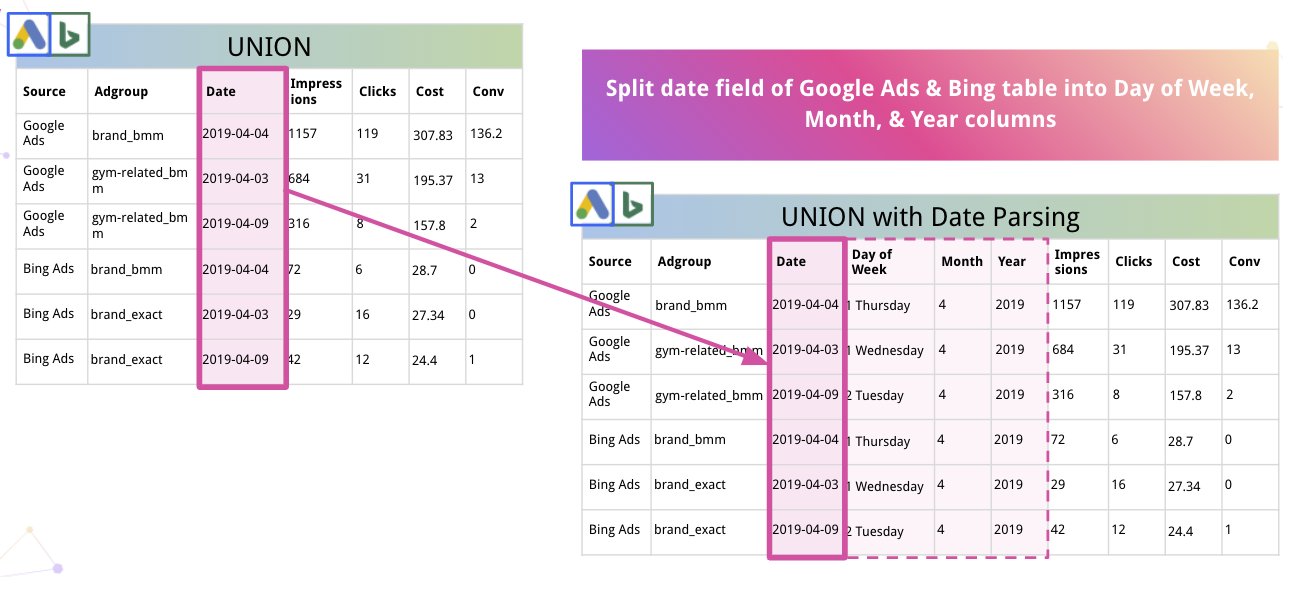
De plus, la plate-forme peut automatiquement analyser les données et les convertir dans un format approprié. Par exemple, voici comment Improvado divise la date en colonnes Jour de la semaine, Mois et Année.
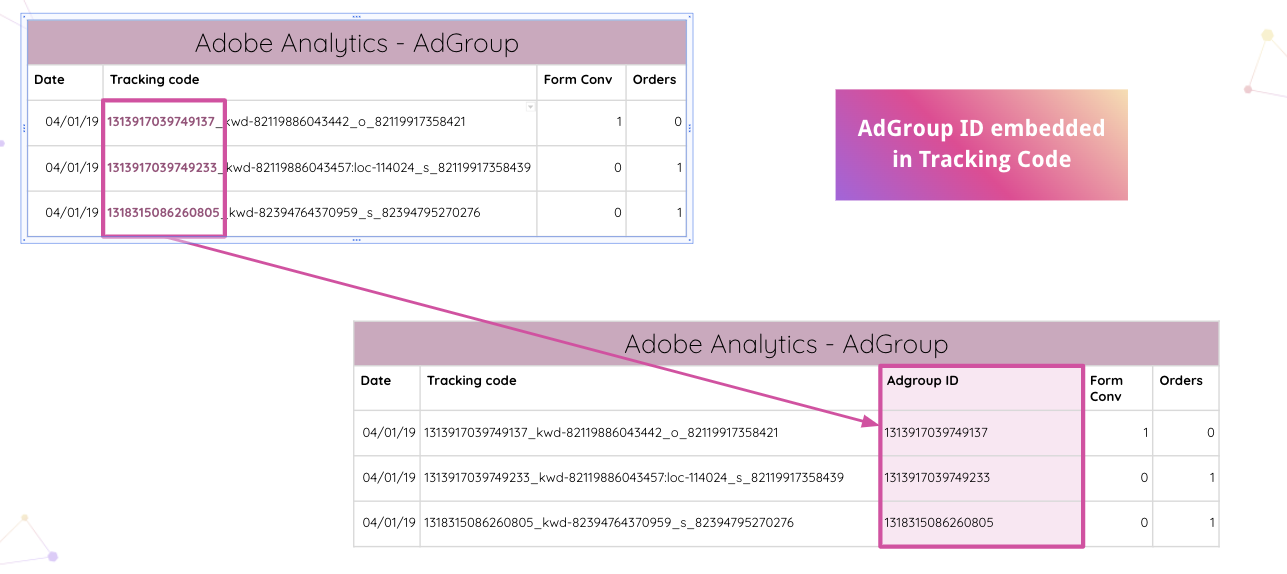
Improvado va encore plus loin en permettant aux analystes d'analyser automatiquement les codes de suivi Adobe Analytics sur votre site Web. Vous pouvez extraire l'ID AdGroup intégré du code de suivi sans manipulations manuelles.
Ensuite, les analystes peuvent combiner des feuilles de calcul internes avec des classifications et les faire correspondre en fonction de l'ID du réseau.
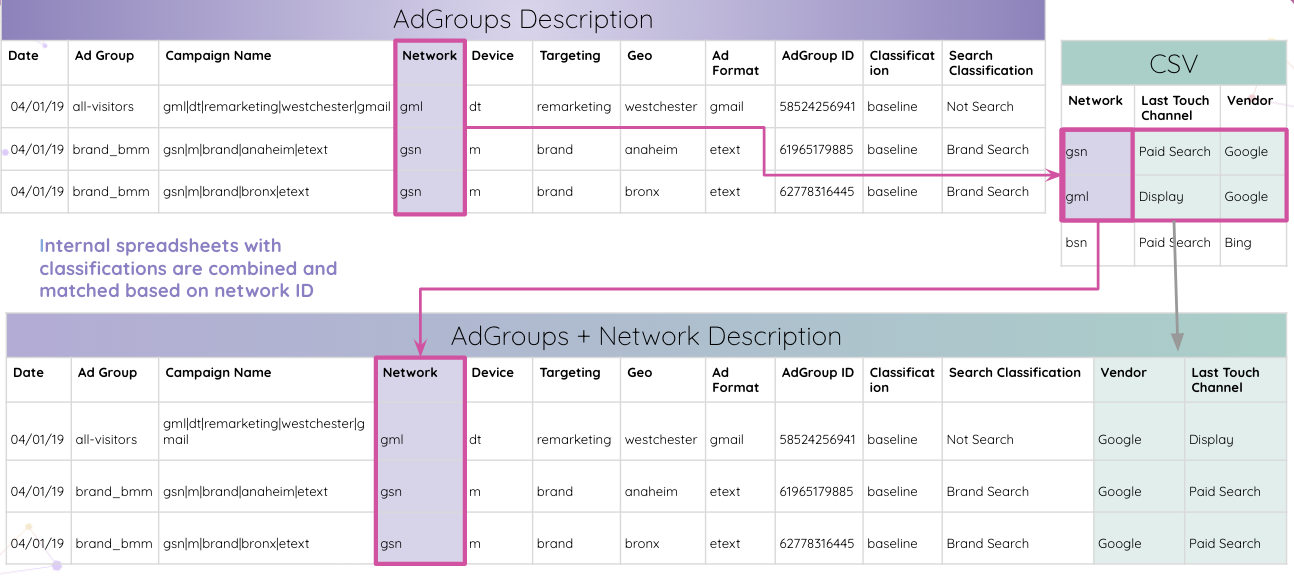
Finalement, les analystes obtiennent tous les tableaux correspondant à l'ID de groupe d'annonces et combinés dans le tableau des résultats finaux.

Ce n'était qu'un des nombreux cas d'utilisation où Improvado peut normaliser les données et fournir des informations de manière digeste pour des recherches ultérieures.
Avec toutes les informations en un seul endroit, la plate-forme peut les rationaliser vers n'importe quel outil de visualisation de votre choix. Des données épurées et structurées facilitent grandement la création d'un tableau de bord cross-canal complet. Par exemple, voici un tableau de bord Data Studio basé sur les informations d'Improvado :
Normalisez les données de marketing et de vente avec Improvado
La normalisation des données prend du temps, mais des informations claires en valent toujours la peine. Pourquoi perdre votre temps sur la normalisation des données si vous pouvez plonger directement dans l'analyse et réduire considérablement votre temps d'analyse ?
Improvado démêle votre réseau de données sur les revenus, réduit le temps consacré aux manipulations manuelles des données et garantit la plus grande granularité des informations. Avec ce système ETL, vous pouvez analyser des données fiables et créer des tableaux de bord en temps réel qui démontrent l'efficacité de vos investissements marketing. Planifiez un appel pour en savoir plus.
Découvrez comment une plate-forme ETL de revenus peut vous aider à dépasser vos objectifs marketing et à faire gagner du temps à vos analystes.
