
Datennormalisierung: Rohe Zahlen in Einnahmen umwandeln
Veröffentlicht: 2022-05-13Daten stehen im Mittelpunkt aller Geschäftsentscheidungen. Es umgibt uns auf Schritt und Tritt. Leider sind die Informationen, die Sie direkt aus Datenquellen erhalten, oft unstrukturiert, fragmentiert und irreführend.
Sie sitzen wahrscheinlich auf einem Haufen langweiliger Daten, die Ihnen helfen könnten, Leads zu gewinnen, Ihren ROI zu verbessern und den Umsatz zu steigern.
Die Datennormalisierung verwandelt Ihre Rohdaten in umsetzbare Erkenntnisse, die den Wert steigern.
Was ist Datennormalisierung?
Um einige große Worte zu verwenden, ist die Datennormalisierung der Prozess, Daten so zu organisieren, dass sie in einen bestimmten Bereich oder in Standardformulare passen. Es hilft Analysten, neue Erkenntnisse zu gewinnen, Datenredundanz zu minimieren, Duplikate zu beseitigen und Daten für die weitere Analyse leicht verdaulich zu machen.
Eine solche Formulierung kann jedoch kompliziert und verwirrend sein, also reduzieren wir sie auf ein einfaches und anschauliches Beispiel.
Stellen Sie sich vor, Sie sind ein Gärtner, der Äpfel erntet. Dieses Jahr hast du es geschafft, 500 Äpfel von 20 Bäumen zu ernten . Ihr Nachbar rühmt sich jedoch damit, 1.000 Äpfel gesammelt zu haben, und nennt Sie einen schrecklichen Gärtner.
Wenn Sie Ihre 500 Äpfel mit den 1.000 Äpfeln Ihres Nachbarn vergleichen, könnte es scheinen, dass Sie kein sehr geschickter Gärtner sind. Aber Ihr Nachbar hat Ihnen nie gesagt, dass er hundert Apfelbäume gepflanzt hat, um einen solchen Ertrag zu erzielen.
Wenn Sie die Daten normalisieren, zeigt sich, dass sich Ihr Nachbar in einer unangenehmen Situation befindet. Bei 500 Äpfeln von 20 Bäumen erntest du 25 Äpfel pro Baum , während dein Nachbar nur 10 Äpfel pro Baum bekommt. Also, wer ist jetzt ein schrecklicher Gärtner?
Die Analyse kann durch viele nicht normalisierte Daten getrübt werden, sodass Sie den Wald vor lauter Bäumen nicht sehen können.
Hier ist ein weiteres Beispiel mit Waffenkontrolldaten. Es zeigt uns, wie einfach es ist, ohne Datennormalisierung Opfer einer kognitiven Verzerrung zu werden.

Ohne normalisierte Erkenntnisse ist es fast unmöglich, sich ein umfassendes Bild zu machen und fundierte Entscheidungen zum untersuchten Thema zu treffen.
Die zentralen Thesen:
- Die Datennormalisierung ist ein Prozess zum Reorganisieren von Daten in einem Dataset.
- Dieser Prozess vereinfacht weitere Analysen und Datenoperationen.
- Die Datennormalisierung stellt sicher, dass Sie einen umfassenden Überblick über das recherchierte Thema erhalten.
Ok, aber wann müssen Sie Daten normalisieren?
Durch heterogene Daten (Daten mit hoher Variabilität der Datentypen und -formate) ergeben sich für Anwender unterschiedliche Probleme. Es gibt andere Anwendungsfälle, in denen Sie Daten normalisieren müssen. Betrachten wir dieses Thema aus der Perspektive von Marketinganalysten.
An erster Stelle steht die Vereinheitlichung der Namenskonventionen. Beim Sammeln von Daten aus Dutzenden von Marketingkanälen stoßen Analysten beispielsweise oft auf dieselben Metriken unter verschiedenen Namen. Infolgedessen haben Analysten Schwierigkeiten bei der Zuordnung von Daten.
Hier ist beispielsweise, wie ein Reddit-Benutzer seine Probleme mit unterschiedlichen Daten erklärt.
Eine weitere Herausforderung besteht darin, unterschiedliche Daten wie Währungen oder Zeitzonen in einer einzigen Quelle der Wahrheit zu konsolidieren. Sie können einfach kein aufschlussreiches Dashboard erstellen, während Ihre Werbeausgaben in Dollar, Euro, Pfund und einige andere Währungen unterteilt sind.
So beschreibt ein anderer Vermarkter dieses Problem auf Reddit.
Wann ist also der richtige Zeitpunkt, um Ihre Daten zu normalisieren?
- Wenn übereinstimmende Metriken in Ihrem Datensatz unterschiedliche Namenskonventionen haben.
- Wenn Sie heterogene Daten wie Währungen, Zeitzonen, Datumsformate usw.
- Wenn Sie feststellen, dass einige Ihrer Daten redundant sind und Sie sie löschen müssen.
Oft verwechselte Begriffe: Datennormalisierung vs. Standardisierung
Bei der Datentransformation sind Standardisierung und Normalisierung zwei verschiedene Begriffe, die oft verwechselt werden.
Die Normalisierung skaliert die Werte eines Datensatzes neu, damit sie in einen Bereich von [0,1] fallen . Dieser Vorgang ist nützlich, wenn Sie alle Parameter auf einer positiven Skala benötigen.
Bei der Standardisierung werden Ihre Daten so angepasst, dass sie einen Mittelwert von 0 und eine Standardabweichung von 1 haben . Es muss nicht in einen bestimmten Bereich fallen und ist viel weniger von Ausreißern betroffen.
Diese Informationen sind mehr als genug für Marketinganalysten, um die Begriffe nicht mehr zu verwechseln. Wenn Sie jedoch tiefer in dieses Thema eintauchen möchten, finden Sie hier alle Unterschiede zwischen den beiden Konzepten.
Wie Sie Daten normalisieren und Ihre Erkenntnisse zusammenführen
Im Kern erfordert die Datennormalisierung, dass Sie ein Standarddatenformat für alle Datensätze in Ihrem Datensatz erstellen. Ihr Algorithmus sollte alle Daten unabhängig von der Eingabe in einem einheitlichen Format speichern.
Hier sind einige Beispiele für die Datennormalisierung:
- Mister HOLmES sollte als Mr. Holmes gespeichert werden.
- Fifth Avenue Sf sollte als 5th Ave, San Francisco gespeichert werden.
- CTO sollte als Chief Technical Officer gespeichert werden.
Die Normalisierung Ihrer Daten geht Hand in Hand mit der Datenbanknormalisierung. Verschaffen wir uns einen kurzen Überblick darüber, was das ist.
Datenbanknormalisierung: eine Voraussetzung für gereinigte Erkenntnisse
Datenbanknormalisierung ist der Prozess der Organisation von Tabellen und Datenzeilen in einer relationalen Datenbank.
Der Prozess umfasst das Erstellen und Verwalten von Beziehungen zwischen Tabellen. Bei der Normalisierung von Datenbanken verlassen sich Analysten und Dateningenieure auf Regeln, die zum Schutz der Daten beitragen und sie für weitere Analysen flexibler machen.
Alle Regeln werden durch Datenbanknormalisierungstypen oder sogenannte „Normalformen“ deklariert.
Es gibt insgesamt sieben Normalformen (die ersten drei werden am häufigsten verwendet):
- Erste Normalform (1 NF)
- Zweite Normalform (2 NF)
- Dritte Normalform (3 NF)
- Boyce Codd Normalform (BCNF)
- Vierte Normalform (4 NF)
- Fünfte Normalform (5 NF)
- Sechste Normalform (6 NF)
Lassen Sie uns all diese Normalformen durchgehen, um zu erfahren, wie sie zur Normalisierung Ihrer Daten beitragen.
Erste Normalform (1NF)
Die erste Normalform erfordert, dass eine Datentabelle die folgenden Bedingungen erfüllt:
- Jede Tabellenzelle sollte einen einzelnen Wert haben.
- Jeder Datensatz sollte einzigartig sein.
- Keine der Spalten sollte verborgene Werte enthalten.
Sehen wir uns ein Beispiel an. Hier haben wir zwei Datensätze aus der Mitarbeitertabelle.

Die Department_Name-Zellen enthalten mehr als einen Parameter in einer Zelle. Damit verletzen sie die erste Regel der 1NF.
Sie müssen diese Tabelle in zwei Teile aufteilen, um Ihre Tabelle zu normalisieren und sich wiederholende Gruppen zu entfernen. Die normalisierten Tabellen sehen folgendermaßen aus:

Die zweite und dritte Normalform drehen sich um Abhängigkeiten zwischen Primärschlüsselspalten und Nichtschlüsselspalten.
Zweite Normalform (2NF)
Die Hauptanforderung der zweiten Normalform ist, dass alle Attribute der Tabelle vom Primärschlüssel abhängen sollten. Mit anderen Worten, alle Werte in den sekundären Spalten sollten eine Abhängigkeit von der primären Spalte haben.
Hinweis: Ein Primärschlüssel ist ein eindeutiger Spaltenwert, der hilft, einen Datenbankeintrag zu identifizieren. Es hat einige Einschränkungen und Attribute:
- Ein Primärschlüsselwert darf nicht NULL sein.
- Ein Primärschlüsselwert sollte für jede Tabelle immer eindeutig sein.
Darüber hinaus muss sich die Tabelle bereits in 1NF befinden, wobei alle teilweisen Abhängigkeiten entfernt und in einer separaten Tabelle abgelegt wurden.
In diesem Stadium wird ein zusammengesetzter Primärschlüssel zum problematischsten Problem.
Hinweis: Ein zusammengesetzter Primärschlüssel ist ein Primärschlüssel, der aus zwei oder mehr Datenspalten besteht.
Stellen Sie sich vor, Sie haben eine Tabelle, in der die Kurse aufgeführt sind, die Ihre Mitarbeiter besucht haben. Verschiedene Mitarbeiter können sich für denselben Kurs anmelden. Aus diesem Grund benötigen Sie einen zusammengesetzten Schlüssel, um den eindeutigen Datensatz zu identifizieren. Die Datumsspalte ist der zusätzliche Parameter für Ihren zusammengesetzten Schlüssel. Schauen Sie sich das Beispiel an:
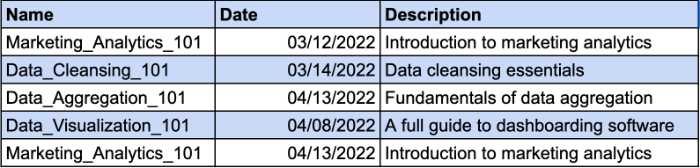
Die Spalte „Beschreibung“ ist jedoch funktional von der Spalte „Name“ abhängig. Wenn Sie den Kursnamen ändern, sollten Sie auch die Beschreibung ändern. Sie müssen also eine separate Tabelle für die Kursbeschreibung erstellen, um die 2NF-Anforderungen zu erfüllen.

So können Sie der Kursbeschreibung einen separaten Schlüssel geben und auf die Verwendung eines zusammengesetzten Schlüssels verzichten.
Dritte Normalform (3NF)
Die dritte Normalform erfordert, dass alle Nichtschlüsselspalten in Ihrer Tabelle direkt vom Primärschlüssel abhängen. Mit anderen Worten, wenn Sie eine der Nicht-Schlüsselspalten entfernen, sollten die verbleibenden Spalten immer noch eine eindeutige Kennung für jeden Datensatz bereitstellen.
Hier sind die wichtigsten Anforderungen des 3NF:
- Alle Tische erfüllen die 2NF-Anforderungen.
- Nicht-Primärschlüsselspalten sollten nur von Primärschlüsselspalten abhängen.
- Tabellen haben keine transitive funktionale Abhängigkeit.
Der Hauptunterschied zwischen 2NF und 3NF besteht darin, dass es in 3NF keine transitiven Abhängigkeiten gibt. Eine transitive Abhängigkeit liegt vor, wenn die Nichtschlüsselspalte von einer anderen Nichtschlüsselspalte abhängt.
Hinweis: Eine transitive Abhängigkeit ist eine indirekte Beziehung zwischen Werten innerhalb derselben Tabelle, die eine funktionale Abhängigkeit verursacht. Eine funktionale Abhängigkeit legt bestimmte Einschränkungen zwischen Attributen fest. In dieser Beziehung bestimmt Attribut A den Wert von Attribut B, während B den Wert von A bestimmt.
Schauen Sie sich das folgende Beispiel an:

Hier bestimmt die Mitarbeiter-ID die Abteilungs-ID aus unserem vorherigen Beispiel, während die Abteilungs-ID den Abteilungsnamen bestimmt. Hier tritt eine indirekte Abhängigkeit zwischen Mitarbeiter-ID und Abteilungsname auf.
Um die 3NF-Anforderungen zu erfüllen, müssen wir die Tabelle in mehrere Teile aufteilen.
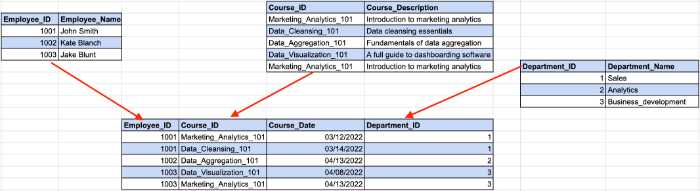
Bei dieser Struktur hängen alle Nichtschlüsselspalten ausschließlich vom Primärschlüssel ab.
Obwohl es sieben Normalformen gibt, gilt die Datenbank nach Erfüllung der 3NF-Anforderungen als normalisiert. Wir werden einen kurzen Überblick über die verbleibenden Normalformen geben, um das Thema bis zum Ende abzudecken.
Boyce-Codd-Normalform (BCNF)
Es ist eine robustere Version des 3NF. Eine BCNF-Tabelle sollte alle 3NF-Regeln erfüllen und keine mehrfach überlappenden Kandidatenschlüssel haben.
Vierte Normalform (4NF)
Die Datenbank wird als 4NF betrachtet, wenn eine ihrer Instanzen zwei oder mehr unabhängige und mehrwertige Dateneinträge enthält.
Fünfte Normalform (5NF)
Eine Tabelle fällt in die fünfte Normalform, wenn sie den 4NF-Anforderungen entspricht, und sie kann nicht ohne Datenverlust in kleinere Tabellen aufgeteilt werden.
Sechste Normalform (6NF)
Die sechste Normalform soll Beziehungsvariablen in irreduzible Komponenten zerlegen. Dies kann wichtig sein, wenn es um zeitliche Variablen oder andere Intervalldaten geht.
Das ist alles für Datenbanknormalisierung 101. Jetzt, da Sie wissen, wie alles funktioniert, können Sie die Vorteile besser verstehen, die die Datennormalisierung zu Ihren Erkenntnissen bringt.
Warum ist es wichtig, Daten zu normalisieren?
Wie wir bereits erwähnt haben, besteht das Hauptziel und der Hauptvorteil der Datennormalisierung darin, Datenredundanz und Inkonsistenzen in Datenbanken zu reduzieren. Je weniger Duplikate Sie haben, desto weniger Fehler und Probleme können während des Datenabrufs auftreten.
Es gibt jedoch weniger offensichtliche Vorteile, die Datenanalysten bei ihrem Arbeitsablauf unterstützen.
Die Datenzuordnung ist kein Zeitvertreib mehr
Wenn Sie schon einmal mit nicht normalisierten Daten zu tun hatten, wissen Sie, dass das Zuordnen von Daten aus mehreren Tabellen zu einer ziemlich mühsam ist.
Es erfordert das Verbinden mehrerer Tabellen, den Umgang mit Duplikaten und das Bereinigen vieler leerer Dateneinträge.
Natürlich können Sie Daten manuell normalisieren, indem Sie SQL-Abfragen oder Python-Skripte schreiben. Datenzuordnungstools mit automatisierten Datennormalisierungsfunktionen beschleunigen den Prozess jedoch.
Beispielsweise bietet die Oracle Integration Cloud Datenzuordnungsfunktionen. Nach der Normalisierung von Daten in der Cloud erstellt das Tool Metadaten für Quellschemata und erstellt einen Eins-zu-eins-Datensatz für jedes Datenobjekt im Zielschema.
Analysten, die mit Marketingeinblicken arbeiten, haben ihre eigenen verborgenen Schätze. MCDM (Marketing Common Data Model) von Improvado ist ein Schweizer Taschenmesser für die Normalisierung von Marketing- und Verkaufsdaten. Das Tool vereinheitlicht unterschiedliche Namenskonventionen, normalisiert Ihre Erkenntnisse und überbrückt die Lücke zwischen Datenquellen und Ihrem Ziel, ohne dass manuelle Maßnahmen erforderlich sind.
️ Finden Sie die richtigen Datenmapping-Tools für Ihre Bedürfnisse mit unserer umfangreichen Liste ️
Datenspeicherung effizienter nutzen
Mit jedem Tag sammeln Unternehmen mehr und mehr Daten, die Speicherplatz beanspruchen. Ob Sie Cloud-Speicher oder ein lokales Data Warehouse verwenden, Sie müssen es effektiv nutzen.
Beispielsweise kosten Sie 100 TB an Daten, die in AWS S3 gespeichert sind, 2.580 $ pro Monat. Darüber hinaus berechnet Amazon Ihnen jede Abfrage, die Sie an Ihren Daten durchführen. Dutzende von Gigabyte an redundanten Daten erhöhen nicht nur Ihre Rechnung für Speicherdienste, sondern führen auch dazu, dass Sie für die Analyse bedeutungsloser Erkenntnisse bezahlen.
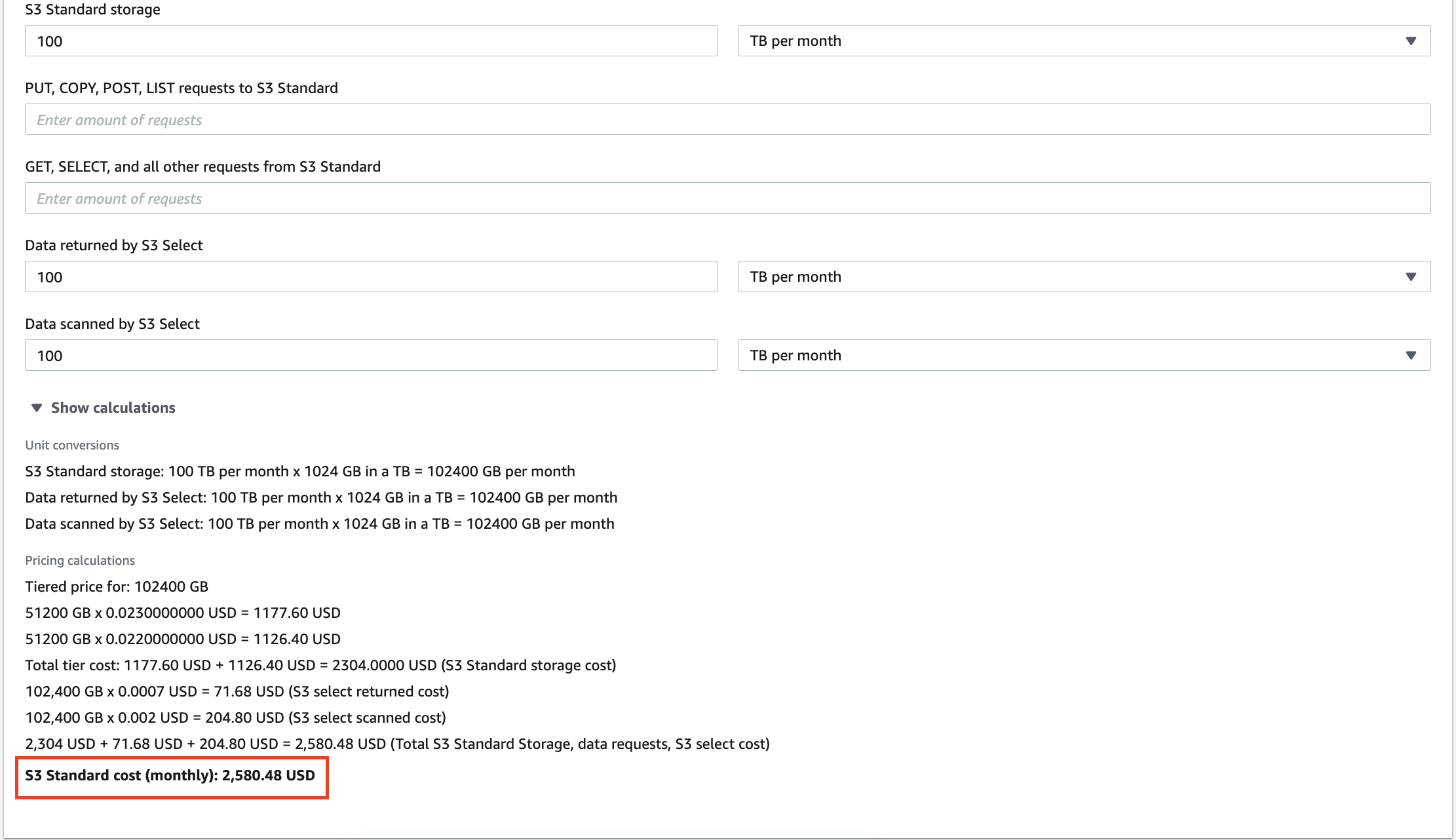
Die Skalierung von lokalen Data Warehouses ist ebenfalls teuer, daher kann das Löschen unnötiger Informationen Ihnen helfen, die Betriebskosten und die TCO (Total Cost of Ownership) zu senken.

Reduzieren Sie Ihre Zeit bis zu Erkenntnissen
Neben der Kostensenkung können Analysten auch ihre Analyseproduktivität steigern.
Das Ausführen von Abfragen auf Terabytes von Daten nimmt Zeit in Anspruch. Während Ihr System die Anfrage verarbeitet, können Sie ruhig eine Tasse Kaffee trinken und mit Ihren Kollegen über Politik diskutieren. Aber es ist schade, wenn die Abfrageausgabe sinnlos ist, weil Sie einige Inkonsistenzen in Ihrem Datensatz hatten.
Mit normalisierten Daten erhalten Sie immer die erwartete Ausgabe, aber ohne Überraschungen wie "N/A", "NaN", "NULL" usw. Außerdem führt das System Ihre Abfragen schneller aus, wenn Sie nur die relevanten Daten parsen. Wer weiß, vielleicht bekommen Sie beim nächsten Mal die Ausgabe, bevor Ihre Kaffeemaschine Ihren Cappuccino macht!
Erstellen Sie Dashboards, denen Sie vertrauen können
Die Datenvisualisierung ist der beste Weg, um sich ein umfassendes Bild Ihrer Analysebemühungen zu machen. Dashboards haben jedoch keinen Wert, wenn Sie sie auf harten Daten aufbauen. Das Dashboard spiegelt nicht den wahren Stand der Dinge wider, wenn Sie es mit Duplikaten füttern.
Aus diesem Grund hat die Datennormalisierung oberste Priorität, wenn Sie komplexe Konzepte oder Leistungsindikatoren durch das Prisma bunter Diagramme und Balken erklären möchten.
So normalisieren Sie Daten in verschiedenen Umgebungen
Da Datenanalysten mit unterschiedlichen Tools arbeiten, erklären wir, wie Daten in den gefragtesten Umgebungen auf dem heutigen Markt normalisiert werden.
So normalisieren Sie Daten in Python
Data Scientists und Analysten, die mit Python arbeiten, verwenden mehrere Bibliotheken, um Daten zu manipulieren und zu bereinigen. Hier sind die beliebtesten unter ihnen:
- Pandas
- Nüppig
- TensorFlow
Wir werden einige der Funktionalitäten dieser Bibliotheken überprüfen, die Ihnen helfen könnten, Ihren Datennormalisierungsprozess zu beschleunigen.
Löschen von Spalten in Ihrem Datensatz
Rohdaten enthalten oft übermäßige oder unnötige Kategorien. Sie arbeiten beispielsweise mit einem Datensatz von Marketingmetriken, die Impressionen, CPC, CTR, ROAS und Conversions umfassen, aber Sie benötigen nur Conversions aus dieser Tabelle.
Wenn alles andere als Conversions für die Analyse nicht wichtig ist, müssen Sie überflüssige Spalten entfernen. Pandas bietet mit der Funktion drop() eine einfache Möglichkeit, Spalten aus einem Datensatz zu entfernen.
Zuerst müssen Sie die Liste der Spalten definieren, die Sie löschen möchten. In unserem Fall sieht das so aus:
column_drop_list = ['Impressionen, 'CPC', 'CTR', 'ROAS']
Dann müssen Sie die Funktion ausführen:
dataframe_name.drop(column_drop_list, inplace=True, Achse=1)
In dieser Codezeile steht der erste Parameter für den Namen unserer Spaltenliste. Wenn Sie den Inplace- Parameter auf True setzen, bedeutet das, dass Pandas Änderungen direkt auf Ihr Objekt anwendet. Der dritte Parameter gibt an, ob Beschriftungen oder Spalten aus dem Datenrahmen gelöscht werden sollen („0“ steht für Beschriftungen, „1“ steht für Spalten).
Nachdem Sie den Datensatz erneut überprüft haben, sehen Sie, dass alle redundanten Spalten erfolgreich entfernt wurden.
Datenfelder bereinigen
Ein weiterer Schritt ist das Aufräumen von Datenfeldern. Es hilft, die Datenkonsistenz zu erhöhen und Daten in ein standardisiertes Format zu bringen.
Das Hauptproblem dabei ist, dass Sie nicht sicher sein können, dass die API einer Marketingplattform 100% genaue Daten überträgt. Sie könnten später immer noch auf falsch platzierte Zeichen oder irreführende Daten stoßen.
Eine einzelne Marketingkampagne kann nur eine Anzahl von Impressionen haben. Deshalb müssen wir wertvolle Zahlen von anderen Zeichen trennen.
Reguläre Ausdrücke (Regex) können Ihnen helfen, alle Ziffern in Ihrem Datensatz zu identifizieren. Dieser Regex-Generator hilft Ihnen, einen regulären Ausdruck für Ihre Bedürfnisse zu erstellen und ihn sofort zu testen.
Dann können wir mit Hilfe der Funktion str.extract() die benötigten Daten als Spalten aus dem Datensatz extrahieren.
true_impressions = dataframe_name.str.extract(your_regex) , expand = False)
Schließlich müssen Sie Ihre Spalte möglicherweise in eine numerische Version konvertieren. Da alle Spalten im Datenrahmen den Objekttyp haben, vereinfacht die Umwandlung in einen numerischen Wert weitere Berechnungen. Sie können dies mit Hilfe der Funktion pd.to_numeric() tun.
Spalten im Datenrahmen umbenennen
Datenquellen übertragen häufig Spalten mit Namen, die Analysten nicht verstehen können. Beispielsweise könnte CTR aus irgendeinem Grund C_T_R_final heißen.
Ein weiteres Problem zeigt sich, wenn man Daten aus verschiedenen Quellen zusammenführt und als Ganzes analysiert. Während die erste Datenquelle Impressionen als Imps bezeichnet, nennt sie eine andere Views. Das erschwert die Berechnung und den Aufbau eines ganzheitlichen Bildes über alle Datenquellen hinweg.
Deshalb müssen Sie Ihre Spalten umbenennen, um alles zu strukturieren.
Erstellen Sie zunächst ein Wörterbuch mit den zukünftigen Namen Ihrer Spalten. Nehmen wir an, wir haben Impressionen von Google Ads und Facebook Ads mit unterschiedlichen Namenskonventionen. In diesem Fall sieht unser Wörterbuch folgendermaßen aus:
new_clmn_names = {'Imps' : 'Google Ads-Impressionen',
'Aufrufe': 'Facebook Ads Impressions'}
Dann sollten Sie die Funktion rename() für Ihren Datenrahmen verwenden:
dataframe_name.rename(columns=new_clmn_names, inplace=True)
Jetzt werden Ihren Spalten im Wörterbuch Namen zugewiesen.
Pandas hat viel mehr verschiedene Funktionen, die Ihnen helfen können, Daten zu normalisieren. Wir empfehlen, die offizielle Dokumentation zu lesen, um andere Funktionen besser zu verstehen.
So normalisieren Sie Daten in Excel
Excel oder Google Sheets ist ein leistungsstarkes Tool, das von vielen Analysten aufgrund seiner Benutzerfreundlichkeit und seiner umfassenden Funktionen geliebt wird. Es besteht kein Zweifel, dass Programmiersprachen wie R oder Python mehr Funktionen zu bieten haben, aber Tabellenkalkulationen leisten hervorragende Arbeit bei der Analyse von Daten.
Ihre Tabellen können jedoch heterogene Daten enthalten, und Excel bietet ein Toolset zum Normalisieren von Erkenntnissen.
Trimmen von zusätzlichen Leerzeichen
Das Identifizieren übermäßiger Leerzeichen in einer großen Tabelle ist Zeitverschwendung, wenn Sie dies manuell tun. Glücklicherweise verfügen Excel und Google Sheets über eine TRIM-Funktion, die es Analysten ermöglicht, zusätzliche Leerzeichen in einem Datensatz mit nur einer Funktion zu entfernen. Sehen Sie sich das Beispiel unten an.

Wie Sie sehen können, haben die Eingabedaten große Leerzeichen zwischen den Wörtern. Mit der TRIM-Funktion werden Daten in das richtige Format gebracht.

Entfernen leerer Datenzeilen im Datensatz
Leere Zellen können während der Analyse zu einem wahren Albtraum eskalieren. Deshalb sollten Sie sich vorher immer damit auseinandersetzen. Hier ist, wie das geht.
- Wählen Sie alle Zellen aus und klicken Sie in der Symbolleiste auf die Registerkarte "Daten".

- Klicken Sie im Sortierbereichsmenü auf die Schaltfläche "Bereich nach Spalte sortieren (Z bis A)".
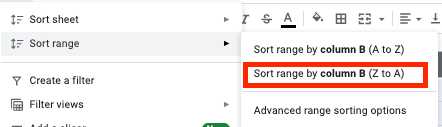
- Jetzt haben Sie alle leeren Zeilen am Ende Ihrer Tabelle, sodass Sie sie einfach auswählen und löschen können.
Entfernen von Duplikaten
Doppelte Dateneinträge sind ein häufiges Problem für Analysten, die mit Excel oder Google Sheets arbeiten. Aus diesem Grund verfügen diese Tools über eine spezielle Funktion zum schnellen und einfachen Entfernen von Duplikaten.
Google Sheets verfügt über eine EINZIGARTIGE Funktion, mit der Sie nur eindeutige Daten in Ihrer Tabelle behalten können.
Angenommen, Sie haben diese einfache Tabelle mit den Spalten „Name“ und „Alter“, die mehrere Duplikate enthalten.

Sie können eine saubere Tabelle ohne doppelte Einträge erhalten, indem Sie Ihren Datensatz in die UNIQUE-Funktion einspeisen.

Normalisierung von Groß- und Kleinschreibung
Nach dem Importieren von Daten aus Textdateien finden Sie häufig inkonsistente Schreibweisen in Namen oder Titeln. Mit den folgenden Funktionen können Sie Ihre Daten in Excel oder Google Sheets ganz einfach korrigieren:
- LOWER() - Wandelt den gesamten Text in Kleinbuchstaben um.
- UPPER() - Wandelt den gesamten Text in Großbuchstaben um.
- PROPER() - Wandelt den gesamten Text in die richtige Groß-/Kleinschreibung um.

Abhängig von Ihrem speziellen Anwendungsfall gibt es viele Möglichkeiten, Excel- oder Google Sheets-Daten zu normalisieren. Diese Leitfäden werfen mehr Licht auf die Normalisierung von Excel-Daten:
- Excel-Datenbereinigungstechniken
- Tipps zur Normalisierung von Excel-Daten von Microsoft
Automatisierte Datennormalisierungstools
Programmiersprachen bieten ein breites Toolset zur Normalisierung Ihrer Daten. Die manuelle Datennormalisierung hat jedoch ihre Grenzen.
Zuallererst benötigen Analysten fundiertes technisches Wissen und praktische Erfahrung mit den erforderlichen Bibliotheken. Datenwissenschaftler und -ingenieure sind äußerst begehrte Talente, und ihre Gehaltsschecks sind oft astronomisch.
Außerdem braucht die Codierung Zeit und ist oft fehleranfällig. Daher ist eine nachträgliche Überprüfung des analysierten Datensatzes ein Muss. Letztendlich kann der Analyseprozess viel länger dauern als beabsichtigt.
Automatisierte Tools sparen Analysten Zeit und liefern präzisere Ergebnisse. Sie können Ihre Daten für das Normalisierungstool rationalisieren und innerhalb von Minuten statt Tagen aufbereitete Einblicke erhalten.
Betrachten wir das Beispiel Improvado. Improvado ist eine Umsatz-ETL-Plattform, die Marketinganalysten und Vertriebsmitarbeitern hilft, ihre unterschiedlichen Daten abzugleichen und Erkenntnisse an einem Ort zu speichern.
Die Plattform sammelt Daten aus über 300 Quellen und hilft Analysten, diese ohne Aufwand zu normalisieren. Der heutige Markt für Marketing- und Vertriebstools ist fragmentiert, und verschiedene Plattformen verwenden unterschiedliche Namenskonventionen für ähnliche Metriken.
Das Marketing Common Data Model (MCDM) von Improvado ist ein einheitliches Datenmodell, das eine automatisierte kanalübergreifende Zuordnung, Deduplizierung und UNIONing beliebter Datenquellen ermöglicht. Außerdem näht und standardisiert es bezahlte Medienquellen zusammen und überträgt automatisch analysebereite Erkenntnisse in Ihr Data Warehouse.
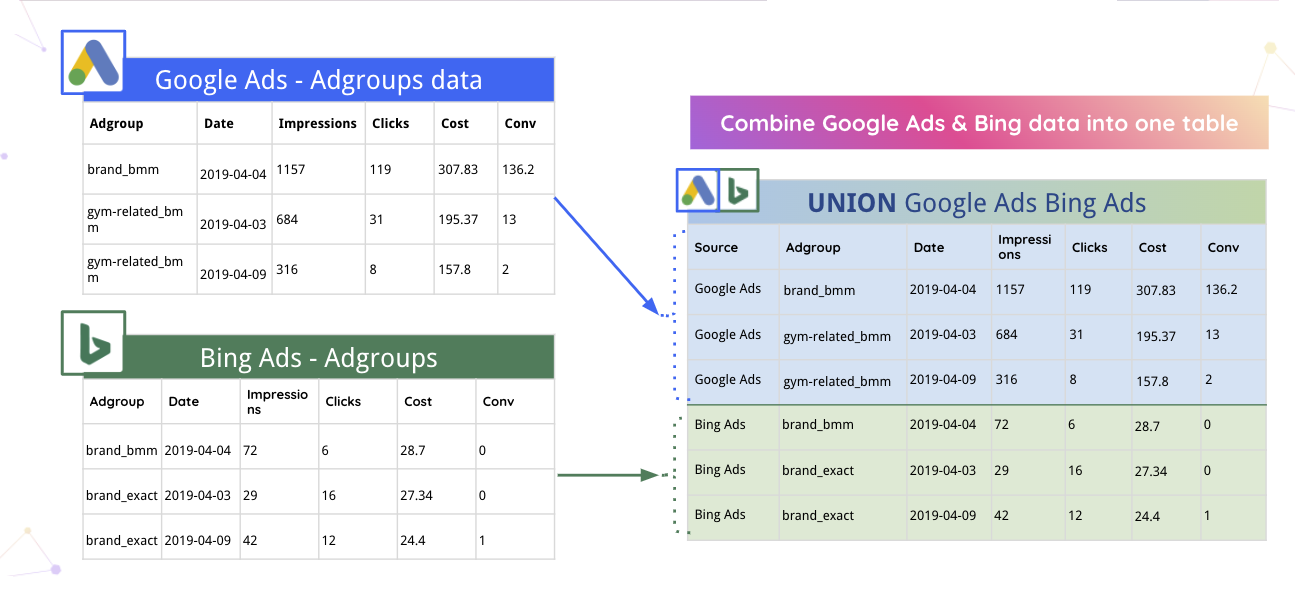
Beispielsweise kann Improvado Google Ads- und Bing-Daten automatisch in einer Tabelle zusammenführen.
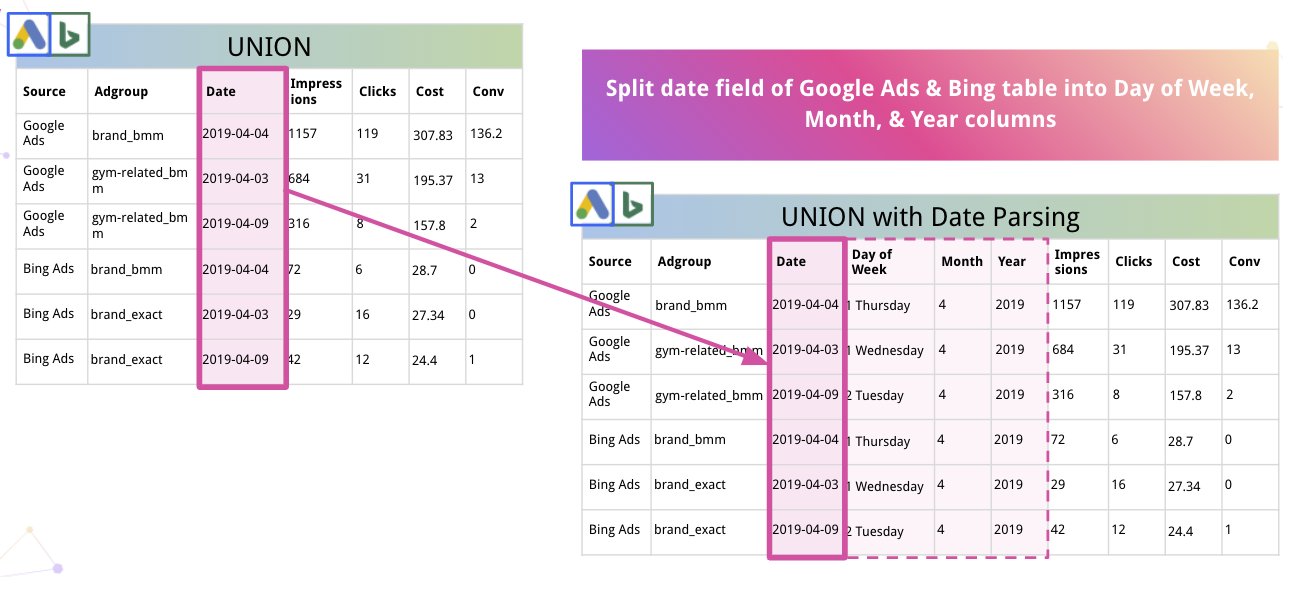
Darüber hinaus kann die Plattform Daten automatisch parsen und in ein geeignetes Format konvertieren. So teilt Improvado zum Beispiel Datum in die Spalten Wochentag, Monat und Jahr auf.
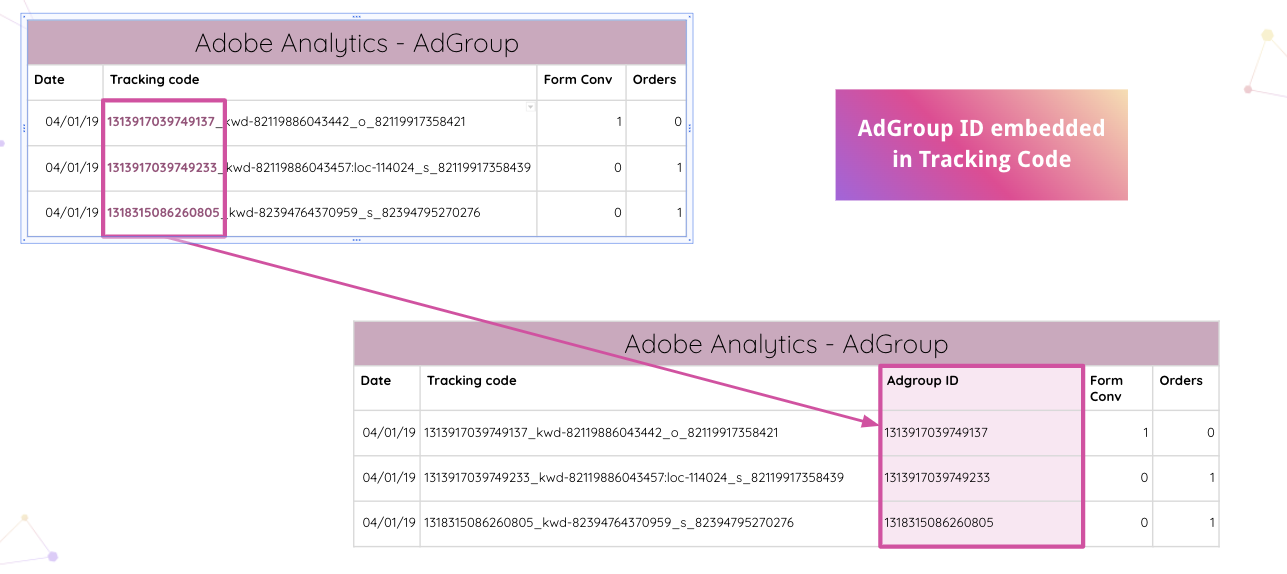
Improvado geht sogar noch weiter und ermöglicht es Analysten, Tracking-Codes von Adobe Analytics auf Ihrer Website automatisch zu parsen. Sie können die eingebettete Anzeigengruppen-ID ohne manuelle Eingriffe aus dem Tracking-Code extrahieren.
Anschließend können Analysten interne Tabellenkalkulationen mit Klassifizierungen kombinieren und sie basierend auf der Netzwerk-ID abgleichen.
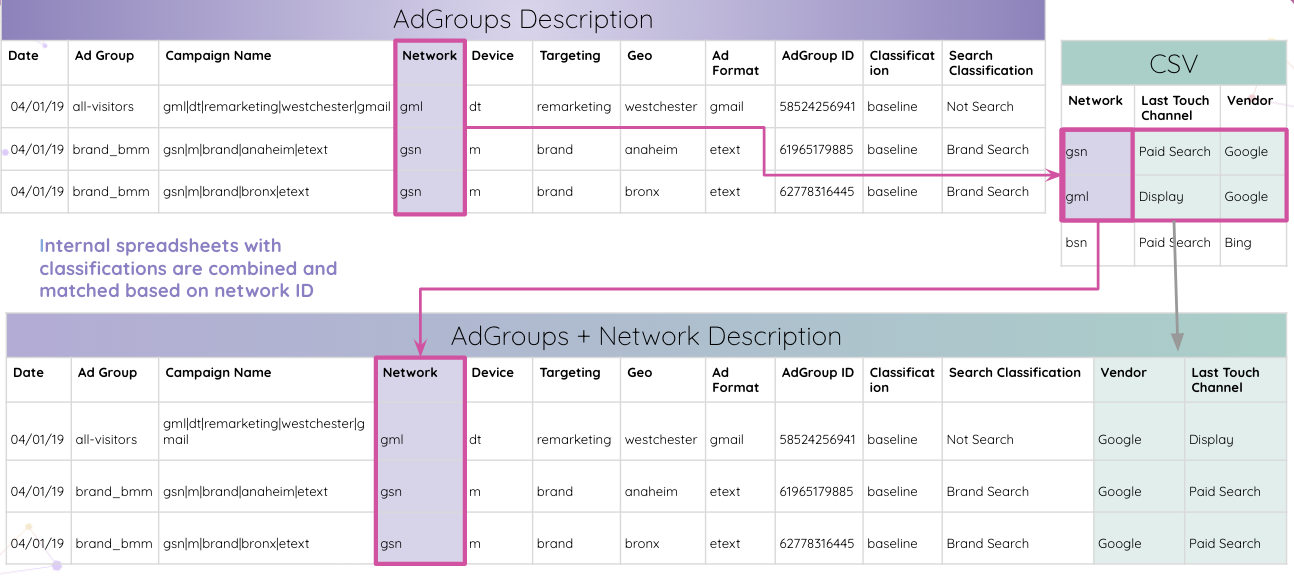
Letztendlich erhalten Analysten alle Tabellen, die mit der Anzeigengruppen-ID abgeglichen und in der endgültigen Ergebnistabelle kombiniert werden.

Das war nur einer von vielen Anwendungsfällen, in denen Improvado Daten normalisieren und Erkenntnisse für die weitere Forschung auf leicht verdauliche Weise liefern kann.
Mit allen Erkenntnissen an einem Ort kann die Plattform sie für jedes Visualisierungstool Ihrer Wahl optimieren. Aufbereitete und strukturierte Daten erleichtern den Aufbau eines umfassenden kanalübergreifenden Dashboards erheblich. Hier ist beispielsweise ein Data Studio-Dashboard, das auf den Erkenntnissen von Improvado basiert:
Normalisieren Sie Marketing- und Vertriebsdaten mit Improvado
Die Datennormalisierung braucht Zeit, aber klare Erkenntnisse sind die Mühe immer wert. Warum Ihre Zeit mit der Datennormalisierung verschwenden, wenn Sie direkt in die Analyse einsteigen und Ihre Zeit bis zur Erkenntnis drastisch verkürzen können?
Improvado entwirrt Ihr Netz aus Umsatzdaten, reduziert den Zeitaufwand für manuelle Datenmanipulationen und gewährleistet die höchste Granularität der Erkenntnisse. Mit diesem ETL-System können Sie vertrauenswürdige Daten analysieren und Echtzeit-Dashboards erstellen, die die Effektivität Ihrer Marketingausgaben demonstrieren. Planen Sie einen Anruf, um mehr zu erfahren.
Erfahren Sie, wie eine Umsatz-ETL-Plattform Ihnen dabei helfen kann, Ihre Marketingziele zu übertreffen und die Zeit Ihrer Analysten zu sparen.
