
Normalizacja danych: zamiana nieprzetworzonych liczb na dochód
Opublikowany: 2022-05-13Dane są podstawą wszystkich decyzji biznesowych. Otacza nas na każdym kroku. Niestety informacje, które otrzymujesz bezpośrednio ze źródeł danych, są często nieustrukturyzowane, fragmentaryczne i wprowadzające w błąd.
Prawdopodobnie siedzisz na stosie nudnych danych, które mogą pomóc Ci przyciągnąć potencjalnych klientów, poprawić ROI i zwiększyć przychody.
Normalizacja danych przekształci Twoje nieprzetworzone liczby w praktyczne informacje, które zwiększą wartość.
Co to jest normalizacja danych?
Używając wielkich słów, normalizacja danych to proces organizowania danych w taki sposób, aby pasowały do określonego zakresu lub standardowych formularzy. Pomaga analitykom uzyskać nowe informacje, zminimalizować nadmiarowość danych, pozbyć się duplikatów i sprawić, że dane będą łatwo przyswajalne do dalszej analizy.
Jednak takie sformułowania mogą być skomplikowane i mylące, więc sprowadźmy to do prostego i ilustracyjnego przykładu.
Wyobraź sobie, że jesteś ogrodnikiem zbierającym jabłka. W tym roku udało Ci się zebrać 500 jabłek z 20 drzew . Jednak twój sąsiad chwali się, że zebrał 1000 jabłek i nazywa cię okropnym ogrodnikiem.
Jeśli porównasz swoje 500 jabłek z 1000 jabłek sąsiada, może się wydawać, że nie jesteś zbyt zręcznym ogrodnikiem. Ale twój sąsiad nigdy ci nie powiedział, że posadził sto jabłoni, aby osiągnąć taki plon.
Jeśli znormalizujesz dane, okaże się, że twój sąsiad jest w nieprzyjemnej sytuacji. Mając 500 jabłek z 20 drzew, zbierasz 25 jabłek z drzewa , podczas gdy twój sąsiad otrzymuje tylko 10 jabłek z drzewa. Więc kto jest teraz okropnym ogrodnikiem?
Analiza może być zagmatwana przez wiele nieznormalizowanych danych, więc nie widać lasu pod kątem drzew.
Oto kolejny przykład z wykorzystaniem danych kontrolnych pistoletu. Pokazuje nam, jak łatwo jest paść ofiarą błędu poznawczego bez normalizacji danych.

Bez znormalizowanych spostrzeżeń prawie niemożliwe jest zbudowanie całościowego obrazu i podejmowanie świadomych decyzji w badanym temacie.
Kluczowe dania na wynos:
- Normalizacja danych to proces reorganizacji danych w zbiorze danych.
- Proces ten upraszcza dalszą analizę i operacje na danych.
- Normalizacja danych zapewnia pełny wgląd w badany temat.
Ok, ale kiedy trzeba znormalizować dane?
Użytkownicy doświadczają różnych problemów w wyniku heterogenicznych danych (dane o dużej zmienności typów i formatów danych). Istnieją inne przypadki użycia, w których musisz znormalizować dane. Rozważmy tę kwestię z perspektywy analityków marketingowych.
Przede wszystkim ujednolicenie konwencji nazewnictwa. Na przykład, zbierając dane z dziesiątek kanałów marketingowych, analitycy często napotykają te same wskaźniki pod różnymi nazwami. W rezultacie analitycy mają trudności z mapowaniem danych.
Na przykład, oto jak jeden użytkownik Reddit wyjaśnia swoje problemy z odmiennymi danymi.
Kolejnym wyzwaniem jest konsolidacja różnych danych, takich jak waluty czy strefy czasowe, w jednym źródle prawdy. Po prostu nie można zbudować wnikliwego pulpitu nawigacyjnego, gdy wydatki na reklamę są podzielone na dolary, euro, funty i kilka innych walut.
Oto jak inny marketer opisuje ten problem na Reddit.
Kiedy więc jest właściwy czas na normalizację danych?
- Podczas dopasowywania metryk w zestawie danych obowiązują różne konwencje nazewnictwa.
- Gdy trzeba dopasować heterogeniczne dane, takie jak waluty, strefy czasowe, formaty dat itp.
- Gdy zauważysz, że niektóre Twoje dane są zbędne i musisz je wyeliminować.
Często mylone terminy: normalizacja danych vs. standaryzacja
W transformacji danych standaryzacja i normalizacja to dwa różne terminy, które często są mylone.
Normalizacja przeskalowuje wartości zestawu danych, aby mieściły się w zakresie [0,1] . Ten proces jest przydatny, gdy potrzebujesz, aby wszystkie parametry były na dodatniej skali.
Standaryzacja dostosowuje dane tak, aby miały średnią 0 i odchylenie standardowe 1 . Nie musi mieścić się w określonym zakresie i jest znacznie mniej zależny od wartości odstających.
Te informacje są więcej niż wystarczające, aby analitycy marketingowi przestali mylić terminy. Jeśli jednak chcesz zagłębić się w ten temat, wszystkie różnice między tymi dwoma pojęciami znajdziesz tutaj.
Jak znormalizować dane i zebrać swoje spostrzeżenia razem
Zasadniczo normalizacja danych wymaga utworzenia standardowego formatu danych dla wszystkich rekordów w zestawie danych. Twój algorytm powinien przechowywać wszystkie dane w ujednoliconym formacie bez względu na dane wejściowe.
Oto kilka przykładów normalizacji danych:
- Mister HOLmES powinien być przechowywany jako Mr. Holmes.
- Fifth Avenue Sf powinna być przechowywana jako 5th Ave w San Francisco.
- CTO powinien być przechowywany jako Chief Technical Officer.
Normalizacja danych idzie w parze z normalizacją bazy danych. Zróbmy krótki przegląd tego, co to jest.
Normalizacja bazy danych: warunek wstępny oczyszczonych spostrzeżeń
Normalizacja bazy danych to proces organizowania tabel i wierszy danych w relacyjnej bazie danych.
Proces obejmuje tworzenie i zarządzanie relacjami między tabelami. Podczas normalizacji baz danych analitycy i inżynierowie danych polegają na regułach, które pomagają chronić dane i czynią je bardziej elastycznymi pod kątem dalszej analizy.
Wszystkie reguły są deklarowane przez typy normalizacji bazy danych lub tzw. „formularze normalne”.
W sumie jest siedem form normalnych (najczęściej używane są trzy pierwsze):
- Pierwsza forma normalna (1 NF)
- Druga forma normalna (2 NF)
- Trzecia forma normalna (3 NF)
- Postać normalna Boyce'a Codda (BCNF)
- Czwarta forma normalna (4 NF)
- Piąta forma normalna (5 NF)
- Szósta forma normalna (6 NF)
Przejrzyjmy wszystkie te formularze normalne, aby dowiedzieć się, jak pomagają normalizować dane.
Pierwsza forma normalna (1NF)
Pierwsza forma normalna wymaga, aby tabela danych spełniała następujące warunki:
- Każda komórka tabeli powinna mieć jedną wartość.
- Każdy rekord powinien być niepowtarzalny.
- Żadna z kolumn nie powinna zawierać ukrytych wartości.
Przyjrzyjmy się przykładowi. Tutaj mamy dwa rekordy z tabeli pracowników.

Komórki Nazwa_działu zawierają więcej niż jeden parametr w komórce. W ten sposób łamią pierwszą zasadę 1NF.
Musisz podzielić tę tabelę na dwie części, aby znormalizować tabelę i usunąć powtarzające się grupy. Znormalizowane tabele będą wyglądać tak:

Druga i trzecia forma normalna obracają się wokół zależności między kolumnami klucza podstawowego i kolumnami bez klucza.
Druga forma normalna (2NF)
Głównym wymaganiem drugiej postaci normalnej jest to, że wszystkie atrybuty tabeli powinny zależeć od klucza podstawowego. Innymi słowy, wszystkie wartości w kolumnach pomocniczych powinny być zależne od kolumny podstawowej.
Uwaga: Klucz podstawowy to unikalna wartość kolumny, która pomaga zidentyfikować rekord bazy danych. Ma pewne ograniczenia i atrybuty:
- Wartość klucza podstawowego nie może mieć wartości NULL.
- Wartość klucza podstawowego powinna być zawsze unikalna dla każdej tabeli.
Dodatkowo tabela musi być już w 1NF z usuniętymi wszystkimi zależnościami częściowymi i umieszczonymi w osobnej tabeli.
Na tym etapie najbardziej problematyczną kwestią staje się złożony klucz podstawowy .
Uwaga: Złożony klucz podstawowy to klucz podstawowy złożony z co najmniej dwóch kolumn danych.
Wyobraźmy sobie, że masz tabelę, na której widnieje lista kursów, które przebyli Twoi pracownicy. Na ten sam kurs mogą zapisać się różni pracownicy. Dlatego do zidentyfikowania unikalnego rekordu potrzebny będzie klucz złożony. Kolumna Data będzie dodatkowym parametrem klucza złożonego. Spójrz na przykład:
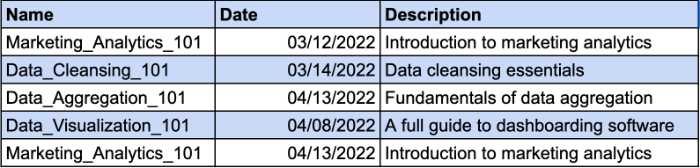
Jednak kolumna Opis jest funkcjonalnie zależna od kolumny Nazwa. Jeśli zmienisz nazwę kursu, powinieneś również zmienić opis. Musisz więc stworzyć osobną tabelę, aby opis kursu był zgodny z wymaganiami 2NF.

W ten sposób możesz nadać opisowi kursu osobny klucz i uniknąć używania klucza złożonego.
Trzecia forma normalna (3NF)
Trzecia forma normalna wymaga, aby wszystkie kolumny w tabeli, które nie są kluczami, były bezpośrednio zależne od klucza podstawowego. Innymi słowy, jeśli usuniesz jakąkolwiek kolumnę bez klucza, pozostałe kolumny powinny nadal zapewniać unikalny identyfikator dla każdego rekordu.
Oto główne wymagania 3NF:
- Wszystkie stoły spełniają wymagania 2NF.
- Kolumny klucza innego niż podstawowy powinny zależeć tylko od kolumn klucza podstawowego.
- Tabele nie mają przechodniej zależności funkcjonalnej.
Główna różnica między 2NF a 3NF polega na tym, że w 3NF nie ma zależności przechodnich. Zależność przechodnia istnieje, gdy kolumna bez klucza zależy od innej kolumny bez klucza.
Uwaga: Zależność przechodnia to pośrednia relacja między wartościami w tej samej tabeli, która powoduje zależność funkcjonalną. Zależność funkcjonalna ustala określone ograniczenia między atrybutami. W tej relacji atrybut A określa wartość atrybutu B, podczas gdy B określa wartość A.
Spójrz na poniższy przykład:

W tym przypadku identyfikator pracownika określa identyfikator działu z naszego poprzedniego przykładu, podczas gdy identyfikator działu określa nazwę działu. W tym miejscu występuje pośrednia zależność między identyfikatorem pracownika a nazwą działu.
Aby spełnić wymagania 3NF, musimy podzielić stół na kilka części.
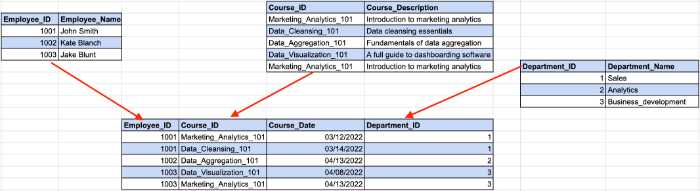
Dzięki tej strukturze wszystkie kolumny bez klucza zależą wyłącznie od klucza podstawowego.
Mimo że istnieje siedem form normalnych, baza danych jest uważana za znormalizowaną po spełnieniu wymagań 3NF. Zrobimy szybki przegląd pozostałych formularzy normalnych, aby omówić temat do końca.
Postać normalna Boyce-Codda (BCNF)
To bardziej wytrzymała wersja 3NF. Tabela BCNF powinna być zgodna ze wszystkimi regułami 3NF i nie zawierać wielu nakładających się kluczy kandydujących.
Czwarta forma normalna (4NF)
Baza danych jest uważana za 4NF, jeśli którakolwiek z jej instancji zawiera co najmniej dwa niezależne i wielowartościowe wpisy danych.
Piąta forma normalna (5NF)
Tabela mieści się w piątej formie normalnej, jeśli spełnia wymagania 4NF i nie można jej podzielić na mniejsze tabele bez utraty danych.
Szósta forma normalna (6NF)
Szósta Postać Normalna ma na celu rozłożenie zmiennych relacji na nieredukowalne składniki. Może to być ważne, gdy mamy do czynienia ze zmiennymi czasowymi lub innymi danymi interwałowymi.
To wszystko w przypadku normalizacji bazy danych 101. Teraz, gdy wiesz, jak wszystko działa, możesz lepiej zrozumieć korzyści, jakie normalizacja danych wnosi do Twoich spostrzeżeń.
Dlaczego normalizacja danych jest ważna?
Jak już wspomnieliśmy, głównym celem i korzyścią normalizacji danych jest zmniejszenie nadmiarowości i niespójności danych w bazach danych. Im mniej masz duplikatów, tym mniej błędów i problemów, które mogą wystąpić podczas pobierania danych.
Istnieją jednak mniej oczywiste korzyści, które pomagają analitykom danych w ich przepływie pracy.
Mapowanie danych nie jest już czasochłonne
Jeśli kiedykolwiek miałeś do czynienia z nieznormalizowanymi danymi, wiesz, że proces mapowania danych z wielu tabel w jedną jest dość żmudny.
Wymaga łączenia wielu tabel, radzenia sobie z duplikatami i czyszczenia wielu pustych wpisów danych.
Oczywiście możesz ręcznie normalizować dane, pisząc zapytania SQL lub skrypty Pythona. Jednak narzędzia do mapowania danych z funkcjami zautomatyzowanej normalizacji danych przyspieszą ten proces.
Na przykład Oracle Integration Cloud oferuje funkcje mapowania danych. Po znormalizowaniu danych w chmurze narzędzie buduje metadane dla schematów źródłowych i tworzy rekord jeden do jednego dla każdego obiektu danych w schemacie docelowym.
Analitycy pracujący nad spostrzeżeniami marketingowymi mają swoje ukryte skarby. MCDM (Marketing Common Data Model) firmy Improvado to szwajcarski scyzoryk służący do normalizacji danych marketingowych i sprzedażowych. Narzędzie ujednolica odmienne konwencje nazewnictwa, normalizuje Twoje spostrzeżenia i wypełnia lukę między źródłami danych a miejscem docelowym bez konieczności wykonywania ręcznych działań.
️ Znajdź odpowiednie narzędzia do mapowania danych dla swoich potrzeb dzięki naszej obszernej liście ️
Efektywniej wykorzystuj przechowywanie danych
Z każdym mijającym dniem firmy gromadzą coraz więcej danych, które zajmują przestrzeń dyskową. Niezależnie od tego, czy korzystasz z magazynu w chmurze, czy z lokalnej hurtowni danych, musisz z niej efektywnie korzystać.
Na przykład 100 TB danych przechowywanych w AWS S3 będzie kosztować 2,580 USD miesięcznie. Co więcej, Amazon naliczy opłatę za każde zapytanie, które wykonasz na swoich danych. Dziesiątki gigabajtów nadmiarowych danych nie tylko zwiększą Twoją fakturę za usługi pamięci masowej, ale także spowodują, że zapłacisz za analizę bezsensownych spostrzeżeń.
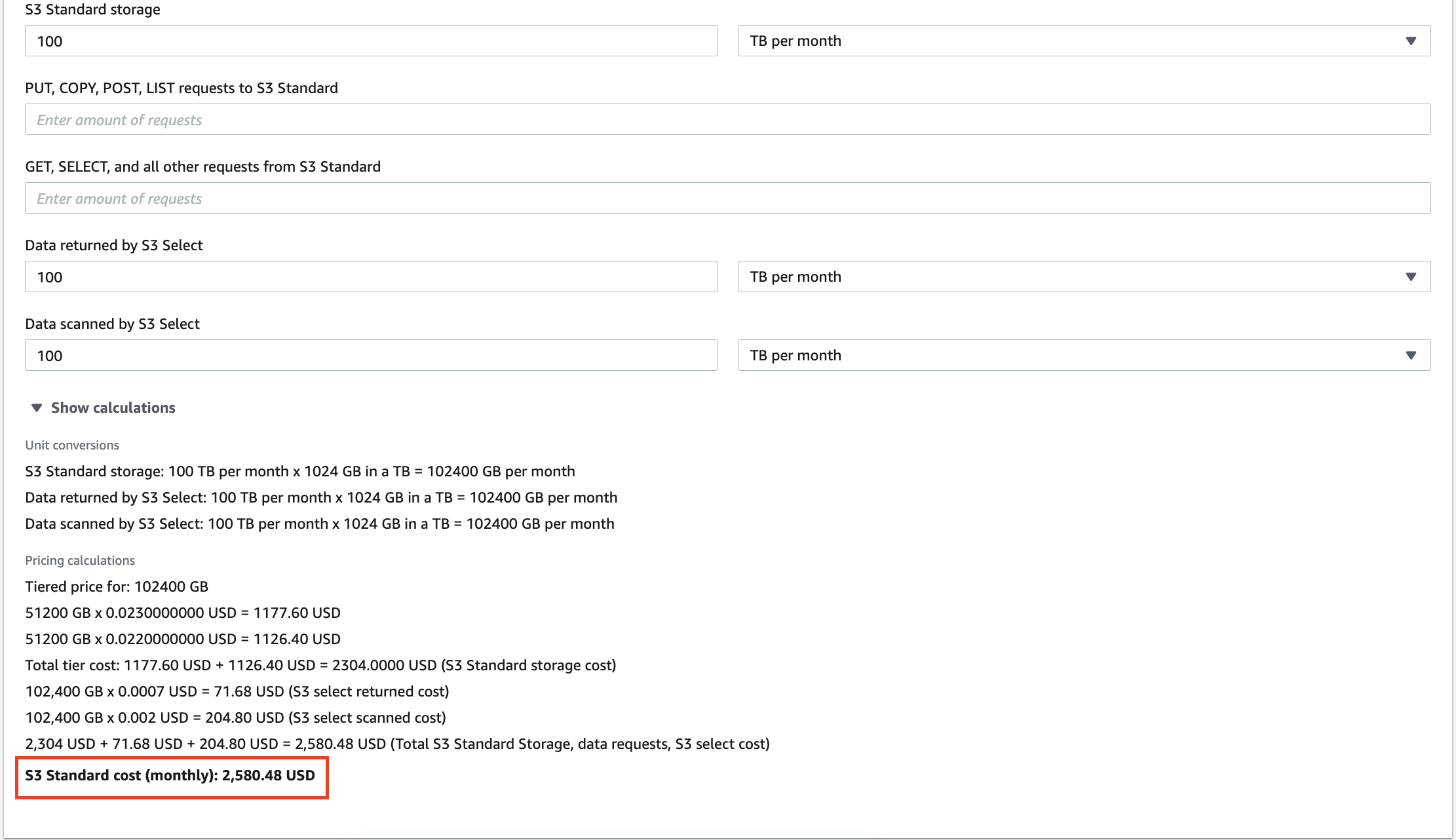
Skalowanie lokalnych hurtowni danych jest również kosztowne, więc usunięcie niepotrzebnych informacji może pomóc w obniżeniu kosztów operacyjnych i całkowitego kosztu posiadania (TCO).

Skróć czas uzyskiwania wglądu
Oprócz redukcji kosztów analitycy mogą również zwiększyć wydajność analiz.
Wykonywanie zapytań na terabajtach danych zajmuje trochę czasu. Podczas gdy Twój system przetwarza zapytanie, możesz wypić filiżankę kawy i porozmawiać o polityce z kolegami. Szkoda jednak, gdy wynik zapytania jest bezcelowy, ponieważ w zestawie danych wystąpiły pewne niespójności.
Przy znormalizowanych danych zawsze otrzymujesz oczekiwany wynik, ale bez niespodzianek, takich jak „N/A”, „NaN”, „NULL” itp. Co więcej, system szybciej wykonuje Twoje zapytania, gdy parsujesz tylko odpowiednie dane. Kto wie, może następnym razem uzyskasz efekt, zanim ekspres zrobi cappuccino!
Twórz pulpity nawigacyjne, którym możesz zaufać
Wizualizacja danych to najlepszy sposób na zbudowanie kompleksowego obrazu działań analitycznych. Jednak pulpity nawigacyjne nie mają wartości, jeśli budujesz je na surowych danych. Pulpit nawigacyjny nie będzie odzwierciedlał prawdziwego stanu rzeczy, jeśli nadasz mu duplikaty.
Dlatego normalizacja danych ma najwyższy priorytet, jeśli chcesz wyjaśnić złożone koncepcje lub wskaźniki wydajności przez pryzmat kolorowych wykresów i słupków.
Jak znormalizować dane w różnych środowiskach
Ponieważ analitycy danych pracują z różnymi narzędziami, wyjaśnimy, jak normalizować dane w najbardziej pożądanych środowiskach na dzisiejszym rynku.
Jak znormalizować dane w Pythonie
Analitycy i analitycy danych pracujący z Pythonem używają kilku bibliotek do manipulowania danymi i porządkowania ich. Oto najpopularniejsze z nich:
- Pandy
- Numpy
- Przepływ Tensora
Przyjrzymy się niektórym funkcjom tych bibliotek, które mogą pomóc przyspieszyć proces normalizacji danych.
Upuszczanie kolumn w zestawie danych
Surowe dane często zawierają nadmierne lub niepotrzebne kategorie. Na przykład pracujesz z zestawem danych marketingowych, który obejmuje wyświetlenia, CPC, CTR, ROAS i konwersje, ale potrzebujesz tylko konwersji z tej tabeli.
Jeśli wszystko poza konwersjami nie jest ważne dla analizy, musisz usunąć nadmiarowe kolumny. Pandas oferuje łatwy sposób usuwania kolumn z zestawu danych za pomocą funkcji drop().
Najpierw musisz zdefiniować listę kolumn, które chcesz usunąć. W naszym przypadku będzie to wyglądać tak:
column_drop_list = ['Wyświetlenia, 'CPC', 'CTR', 'ROAS']
Następnie musisz wykonać funkcję:
dataframe_name.drop(column_drop_list, inplace=True, axis=1)
W tej linii kodu pierwszy parametr oznacza nazwę naszej listy kolumn. Ustawienie parametru inplace na True oznacza, że Pandy zastosują zmiany bezpośrednio do Twojego obiektu. Trzeci parametr wskazuje, czy usunąć etykiety lub kolumny z ramki danych („0” oznacza etykiety, „1” oznacza kolumny).
Po ponownym sprawdzeniu zestawu danych zobaczysz, że wszystkie nadmiarowe kolumny zostały pomyślnie usunięte.
Czyszczenie pól danych
Kolejnym krokiem jest uporządkowanie pól danych. Pomaga zwiększyć spójność danych i uzyskać dane w ustandaryzowanym formacie.
Głównym problemem jest to, że nie możesz być pewien, że API platformy marketingowej przekaże 100% dokładnych danych. Nadal możesz napotkać niewłaściwie umieszczone znaki lub wprowadzające w błąd dane.
Pojedyncza kampania marketingowa może mieć tylko jedną liczbę wyświetleń. Dlatego musimy oddzielić wartościowe liczby od innych znaków.
Wyrażenia regularne (regex) mogą pomóc w identyfikacji wszystkich cyfr w zbiorze danych. Ten generator wyrażeń regularnych pomoże Ci stworzyć wyrażenie regularne dla Twoich potrzeb i od razu je przetestować.
Następnie za pomocą funkcji str.extract() możemy wyodrębnić wymagane dane ze zbioru danych jako kolumny.
true_impressions = dataframe_name.str.extract(your_regex) , expand = False)
Na koniec może być konieczne przekonwertowanie kolumny na wersję numeryczną. Ponieważ wszystkie kolumny w ramce danych mają typ obiektu, przekształcenie go na wartość liczbową uprości dalsze obliczenia. Możesz to zrobić za pomocą funkcji pd.to_numeric().
Zmiana nazw kolumn w ramce danych
Źródła danych często przesyłają kolumny z nazwami, których analitycy nie mogą zrozumieć. Na przykład CTR może z jakiegoś powodu nazywać się C_T_R_final.
Kolejny problem ujawnia się, gdy łączysz dane z różnych źródeł i analizujesz je jako całość. Podczas gdy pierwsze źródło danych określa wyświetlenia jako wyświetlenia, drugie nazywa je wyświetleniami. Utrudnia to obliczenie i zbudowanie całościowego obrazu we wszystkich źródłach danych.
Dlatego musisz zmienić nazwy swoich kolumn, aby wszystko uporządkować.
Najpierw utwórz słownik z przyszłymi nazwami swoich kolumn. Załóżmy, że mamy wyświetlenia z reklam Google Ads i Facebook Ads o różnych konwencjach nazewnictwa. W takim przypadku nasz słownik będzie wyglądał następująco:
new_clmn_names = {'Wyświetlenia' : 'Wyświetlenia Google Ads',
„Wyświetlenia”: „Wyświetlenia reklam na Facebooku”}
Następnie powinieneś użyć funkcji rename() w swojej ramce danych:
dataframe_name.rename(columns=new_clmn_names, inplace=True)
Teraz Twoje kolumny będą miały przypisane nazwy w słowniku.
Pandas ma o wiele więcej różnych funkcji, które mogą pomóc w normalizacji danych. Zalecamy przeczytanie oficjalnej dokumentacji, aby lepiej zrozumieć inne funkcje.
Jak znormalizować dane w Excelu
Excel czy Arkusze Google to potężne narzędzie uwielbiane przez wielu analityków ze względu na łatwość obsługi i szerokie możliwości. Nie ma wątpliwości, że języki programowania, takie jak R czy Python, oferują więcej funkcji, ale arkusze kalkulacyjne świetnie sprawdzają się podczas analizowania danych.
Jednak tabele mogą zawierać heterogeniczne dane, a program Excel zapewnia zestaw narzędzi do normalizacji wglądu.
Przycinanie dodatkowych spacji
Identyfikowanie nadmiernych przestrzeni w dużym stole to strata czasu, gdy odbywa się to ręcznie. Na szczęście Excel i Arkusze Google mają funkcję TRIM, która pozwala analitykom usuwać dodatkowe spacje w zestawie danych za pomocą tylko jednej funkcji. Spójrz na poniższy przykład.

Jak widać, dane wejściowe mają duże odstępy między słowami. Dzięki funkcji TRIM dane są umieszczane we właściwym formacie.

Usuwanie pustych wierszy danych w zestawie danych
Podczas analizy puste komórki mogą przerodzić się w prawdziwy koszmar. Dlatego zawsze powinieneś sobie z nimi radzić wcześniej. Oto jak to zrobić.
- Wybierz wszystkie komórki i kliknij zakładkę "Dane" na pasku narzędzi.

- Kliknij przycisk „Sortuj zakres według kolumny (Z do A)” w menu sortowania zakresu.
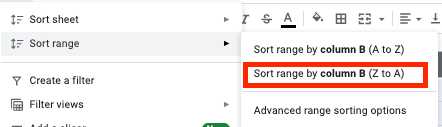
- Teraz masz wszystkie puste wiersze na dole tabeli, więc możesz je po prostu zaznaczyć i usunąć.
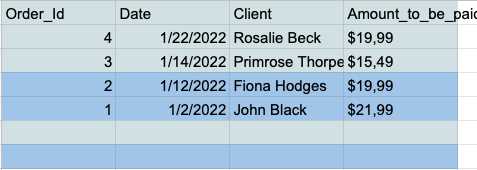
Usuwanie duplikatów
Zduplikowane wpisy danych to częsty problem dla analityków pracujących w Excelu lub Arkuszach Google. Dlatego te narzędzia mają dedykowaną funkcję usuwania duplikatów w szybki i łatwy sposób.
Arkusze Google mają UNIKALNĄ funkcję, która pozwala zachować w tabeli tylko unikalne dane.
Załóżmy, że masz tę prostą tabelę z kolumnami Nazwa i Wiek, które zawierają wiele duplikatów.

Możesz uzyskać czystą tabelę bez zduplikowanych wpisów, wprowadzając zestaw danych do funkcji UNIQUE.

Normalizacja wielkości liter
Po zaimportowaniu danych z plików tekstowych często znajdziesz niespójne przypadki tekstowe w nazwach lub tytułach. Możesz łatwo poprawić swoje dane w programie Excel lub Arkuszach Google, korzystając z następujących funkcji:
- LOWER() — konwertuje cały tekst na małe litery.
- UPPER() — konwertuje cały tekst na wielkie litery.
- PROPER() — Konwertuje cały tekst na poprawną wielkość liter.

W zależności od konkretnego przypadku użycia istnieje wiele sposobów normalizacji danych programu Excel lub Arkuszy Google. Te przewodniki rzucają więcej światła na normalizację danych w programie Excel:
- Techniki czyszczenia danych Excel
- Wskazówki dotyczące normalizacji danych w programie Excel firmy Microsoft
Zautomatyzowane narzędzia do normalizacji danych
Języki programowania oferują szeroki zestaw narzędzi do normalizacji danych. Jednak ręczna normalizacja danych ma swoje ograniczenia.
Przede wszystkim analitycy potrzebują silnej wiedzy inżynierskiej i praktycznego doświadczenia z wymaganymi bibliotekami. Naukowcy i inżynierowie danych są wysoce pożądanymi talentami, a ich zarobki są często astronomiczne.
Co więcej, kodowanie wymaga czasu i często jest podatne na błędy. Konieczna jest więc kontynuacja przeglądu analizowanego zbioru danych. Ostatecznie proces analizy może zająć dużo więcej czasu niż planowano.
Zautomatyzowane narzędzia oszczędzają czas analityków i oferują bardziej precyzyjne wyniki. Możesz usprawnić swoje dane do narzędzia normalizacji i uzyskać bardziej przejrzysty wgląd w ciągu kilku minut, a nie dni.
Rozważmy przykład Impprovado. Impprovado to przychodowa platforma ETL, która pomaga analitykom marketingowym i sprzedawcom łączyć różne dane i przechowywać informacje w jednym miejscu.
Platforma zbiera dane z ponad 300 źródeł i pomaga analitykom w ich normalizacji bez wysiłku. Dzisiejszy rynek narzędzi marketingowych i sprzedażowych jest rozdrobniony, a różne platformy stosują różne konwencje nazewnictwa dla podobnych wskaźników.
Marketing Common Data Model (MCDM) firmy Impprovado to ujednolicony model danych, który zapewnia automatyczne mapowanie między kanałami, deduplikację i łączenie popularnych źródeł danych. Poza tym łączy i standaryzuje źródła płatnych mediów, automatycznie przesyłając gotowe do analizy spostrzeżenia do hurtowni danych.
Na przykład Impprovado może automatycznie łączyć dane Google Ads i Bing w jedną tabelę.
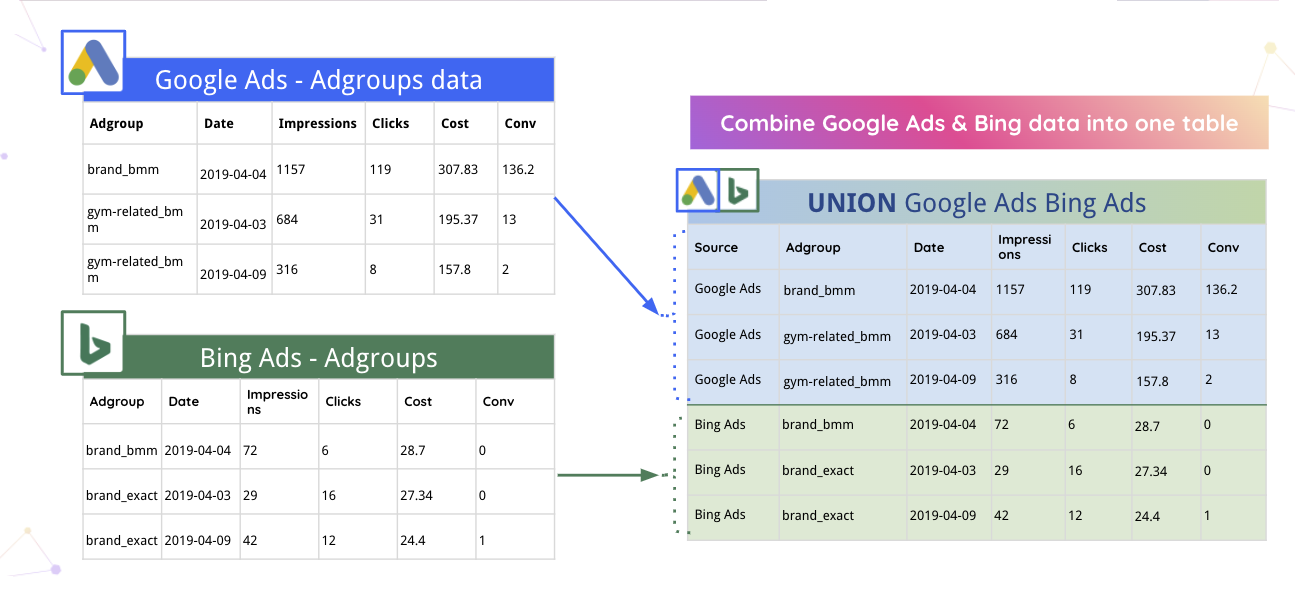
Ponadto platforma może automatycznie analizować dane i konwertować je do odpowiedniego formatu. Na przykład, oto jak Impprovado dzieli Data na kolumny Dzień tygodnia, Miesiąc i Rok.
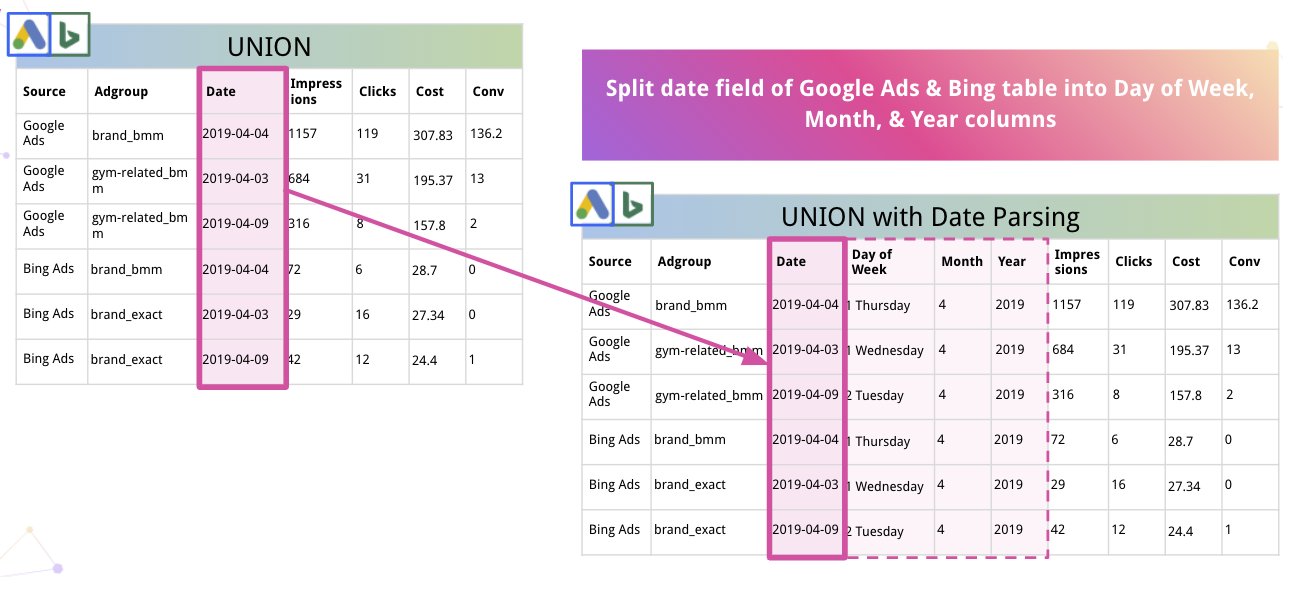
Impprovado idzie jeszcze dalej, umożliwiając analitykom automatyczne analizowanie kodów śledzenia Adobe Analytics w Twojej witrynie. Osadzony identyfikator grupy reklam można wyodrębnić z kodu śledzenia bez ręcznych manipulacji.
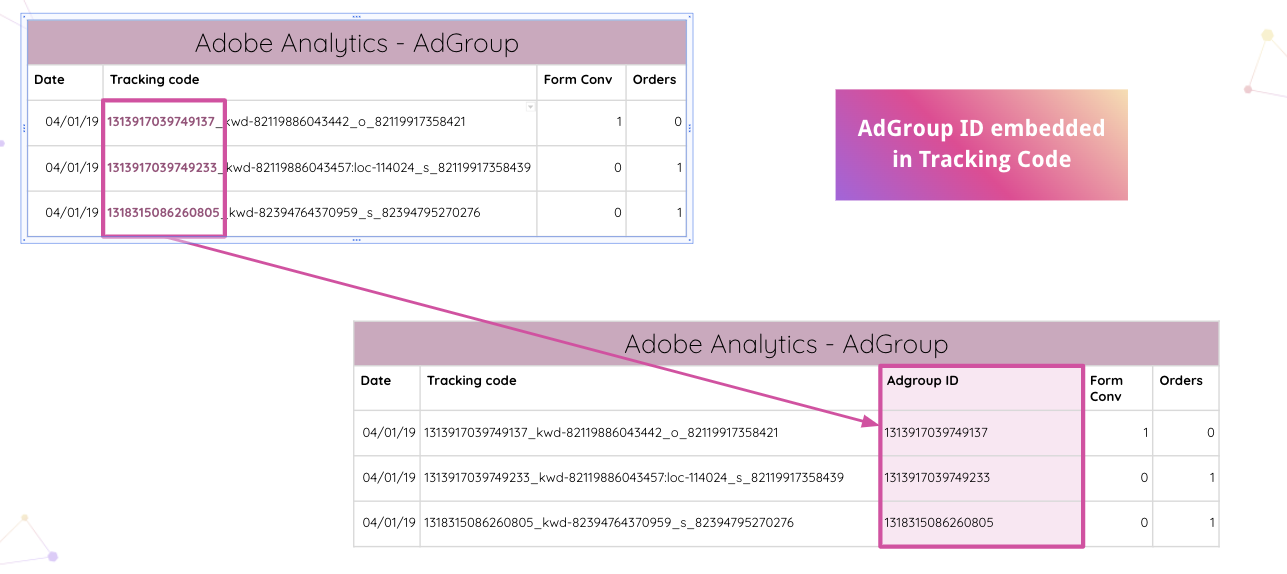
Następnie analitycy mogą łączyć wewnętrzne arkusze kalkulacyjne z klasyfikacjami i dopasowywać je na podstawie identyfikatora sieci.
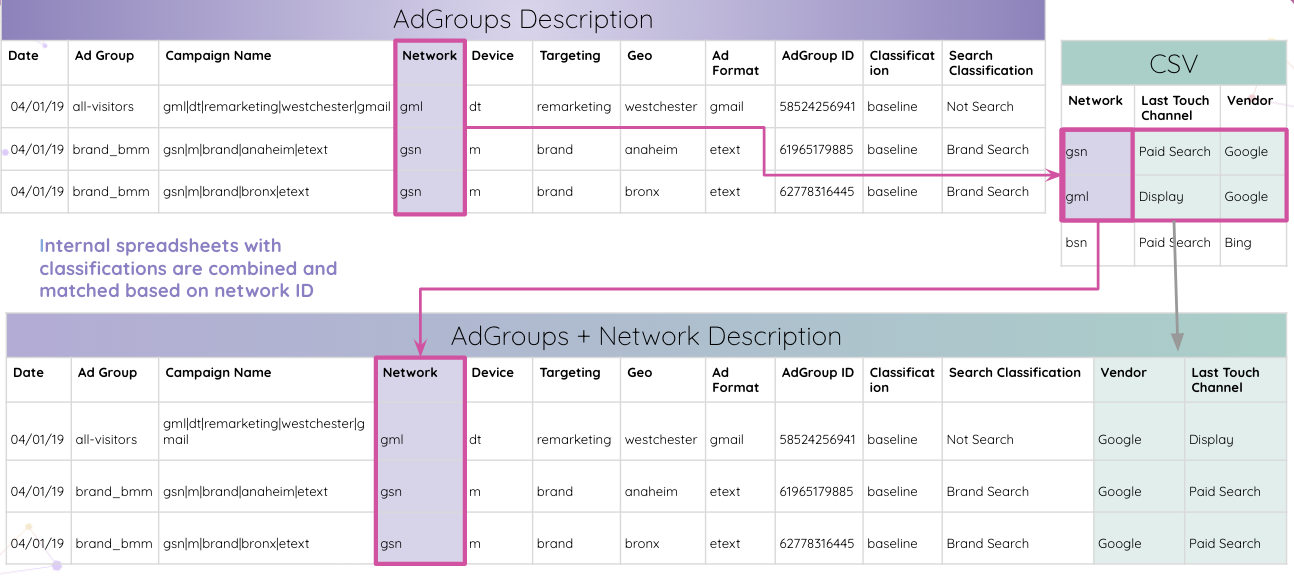
Ostatecznie analitycy otrzymują wszystkie tabele dopasowane według identyfikatora grupy reklam i łączone w tabelę wyników końcowych.

To był tylko jeden z wielu przypadków użycia, w których Impprovado może normalizować dane i dostarczać spostrzeżenia w przystępny sposób do dalszych badań.
Mając wszystkie spostrzeżenia w jednym miejscu, platforma może je usprawnić do dowolnego wybranego przez Ciebie narzędzia do wizualizacji. Oczyszczone i ustrukturyzowane dane znacznie ułatwiają budowanie kompleksowego, wielokanałowego pulpitu nawigacyjnego. Na przykład, oto pulpit nawigacyjny Studia danych oparty na spostrzeżeniach Improvado:
Normalizuj dane marketingowe i sprzedażowe z Impprovado
Normalizacja danych wymaga czasu, ale jasne informacje są zawsze warte wysiłku. Po co marnować czas na normalizację danych, jeśli możesz od razu zagłębić się w analizę i radykalnie skrócić czas uzyskiwania wglądu?
Impprovado rozplątuje sieć danych o przychodach, skraca czas poświęcany na ręczną manipulację danymi i zapewnia najwyższą szczegółowość spostrzeżeń. Dzięki temu systemowi ETL możesz analizować wiarygodne dane i budować pulpity nawigacyjne w czasie rzeczywistym, które pokazują efektywność Twoich pieniędzy marketingowych. Umów się na rozmowę, aby dowiedzieć się więcej.
Dowiedz się, jak dochodowa platforma ETL może pomóc przekroczyć cele marketingowe i zaoszczędzić czas analityków.
