
Как создать современный стек данных
Опубликовано: 2022-05-06В современной экономике, основанной на технологиях, хранение данных стало более сложным, чем когда-либо. По данным IDC (International Data Corporation), в 2025 году будет сгенерировано 175 зеттабайт данных, что почти в три раза больше, чем в 2021 году (61 зеттабайт).
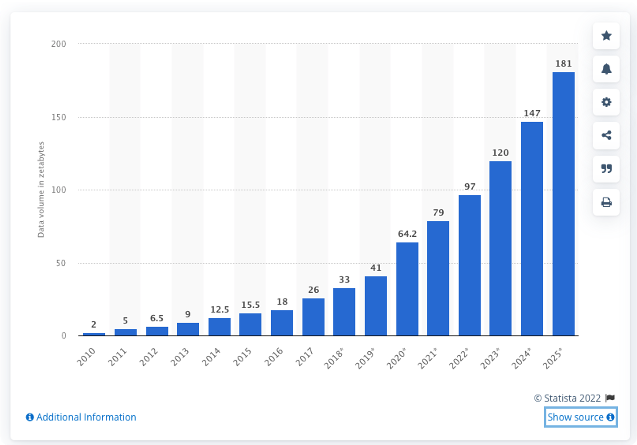
Объем данных, созданных, собранных, скопированных и потребленных по всему миру с 2010 по 2025 год по данным Statista.
Если вы хотите правильно хранить информацию о своей компании и управлять ею, вам необходимо понимать множество доступных опций и то, как их можно интегрировать вместе.
К счастью, это руководство поможет вам создать современный стек данных, который позволит вам собирать, хранить, анализировать и, в конечном счете, использовать ваши данные наиболее эффективным способом. Этот план достаточно гибок, чтобы его могли использовать компании на любом этапе развития, независимо от их размера или типа отрасли.
Зачем вам современный стек данных?
Современный стек данных — это интегрированный набор инструментов для обработки сквозного жизненного цикла данных. Он предназначен для сбора, обработки и активации информации в режиме реального времени. Это важно для любой организации, которая хочет понимать тенденции на детальном уровне (например, внутри организации клиента) и действовать в соответствии с ними до того, как они окончательно закрепятся.
Создать современный стек данных несложно, но это требует некоторого времени и усилий, а также понимания того, что именно вам нужно от ваших данных. Если вы серьезно относитесь к улучшению операций и получению информации о своих клиентах, это будет стоить каждой минуты усилий. Хитрость заключается в том, чтобы знать, с чего начать и как двигаться вперед.
Остальная часть этого руководства предоставит вам всю информацию, необходимую для создания современного стека данных. Вы узнаете, как различные компоненты работают вместе, и как выбрать программное обеспечение для каждой части вашего современного стека данных. Когда вы закончите читать, у вас будет все необходимое, чтобы начать создавать современный стек данных в вашей организации уже сегодня!
«С точки зрения данных устройства для хранения данных — это настоящая золотая жила. Сделать его доступным для вертикально интегрированных решений — основа идеи отраслевого облака».
Ашиш Тусу
Озера данных и хранилища данных: две стороны современной платформы облачных данных
Преимущества современного стека данных
Зачем инвестировать в современный стек данных? Вот некоторые преимущества:
- Легко извлекайте и загружайте данные за считанные минуты в любое место.
- Анализируйте большие объемы неструктурированных данных — документы, результаты поиска, различные метрики и т. д. — не прибегая к написанию пользовательских скриптов или созданию специальных запросов.
- Позвольте любой бизнес-группе самостоятельно обслуживать оперативные, надежные и актуальные данные в своих собственных инструментах.
- Внедряйте инновации в своей организации быстрее, интегрируя инструменты без кода для бизнес-групп.
- Современные стеки данных сокращают накладные расходы на разработку данных, устраняя необходимость создания и обслуживания конвейера данных.
Понять текущую среду
Первым шагом к разработке любого решения является понимание того, что вы пытаетесь исправить. Сделайте шаг назад и посмотрите, какие текущие инструменты, процессы и процедуры использует ваша организация сейчас. Затем спросите себя: насколько они эффективны? Есть ли место для улучшения?
Современный стек данных — это прежде всего эффективность, поэтому, если в вашем текущем процессе есть недостатки (а, поверьте мне, они есть), это область, которую вы можете оптимизировать.
В некоторых случаях это может быть просто расширение сотрудничества между командами или обновление ваших процессов, но иногда это может означать замену устаревшего программного обеспечения или даже внедрение новых технологий в вашу среду.
Что бы это ни было, начните с определения конкретных проблем, которые вы решаете, прежде чем переходить к какой-либо проектной работе. Это значительно облегчит реализацию в будущем.
Определить потребности и цели бизнеса
Прежде чем выбрать базу данных для своего бизнеса, вам необходимо понять ее модель данных, какие запросы и отчеты ей потребуются и кто будет ее использовать. Получение ответов на эти вопросы также поможет вашему бизнесу начать предварительное планирование (вместо того, чтобы вносить изменения в будущем).
Один из ключевых вопросов здесь заключается в том, насколько большим должно быть ваше хранилище данных. Например, в сценарии OLAP (онлайн-аналитическая обработка) у вас будет много строк, но мало данных в каждой, но в сценарии онлайн-обработки транзакций (OLTP) у вас будет много строк с огромными объемами данных. в каждом ряду требуется гораздо больше места для хранения. Кроме того, существуют потребности в отчетах бизнес-аналитики (BI), которые требуют еще больше места. Для таких случаев BigQuery — идеальное хранилище, которое действительно хорошо справляется со всеми тремя сценариями.
Еще одна вещь, о которой следует подумать, — хотите ли вы использовать облачное или локальное хранилище. Следовательно, если вы уже вложили средства в локальную инфраструктуру, Google Cloud Platform может вам не подойти.
Рассчитать масштабируемость и производительность
При выборе поставщика облачных услуг важно учитывать, будет ли ваше приложение масштабироваться и работать должным образом с течением времени.
Еще одним важным моментом является понимание того, как ваши данные будут защищены в каждой среде (например, центры обработки данных могут столкнуться со стихийными бедствиями, перебоями в подаче электроэнергии или отказом оборудования).
Как и во всех этих шагах, необходимо проводить исследования и задавать вопросы. Такие компании, как New Relic, предлагают инструменты, которые помогут вам отслеживать производительность и трафик приложений.
Кроме того, такие организации, как Netflix, создали технологии с открытым исходным кодом, разработанные специально для современных приложений, работающих в общедоступных облаках. Например, компания Netflix разработала Security Monkey — программное обеспечение, помогающее отслеживать и защищать большие среды на базе AWS.
Эти технологии стоит изучить при оценке поставщиков облачных услуг — такие знания можно получить, пообщавшись с инженерами из разных компаний и поняв их опыт.
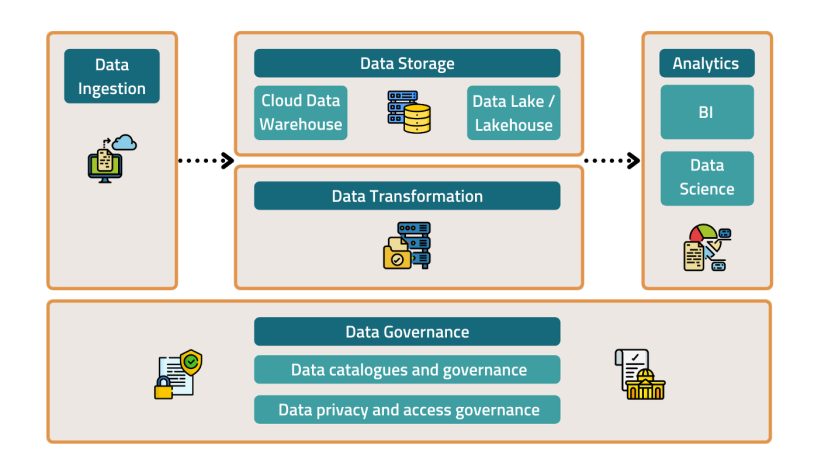
Компоненты современного стека данных
Данные — это стратегический актив. Чтобы максимально использовать его, вам необходимо понимать различные компоненты, составляющие стек данных, и то, как они работают вместе.
Вот ключевые компоненты стека данных, которые следует включить при разработке собственной инфраструктуры данных для вашего продукта:
- Прием данных
- Хранилище данных
- Преобразование данных
- Аналитика данных
- Управление данными
1. Прием данных
Прием данных — это импорт данных из одного места в новое место назначения, например в хранилище данных или озеро данных, для дальнейшего хранения и анализа.
Первым шагом в создании современного стека данных является определение источников данных. Благодаря инструментам приема данных вы сможете импортировать все свои данные за считанные минуты.
Допустим, вы занимаетесь электронной коммерцией, запросы должны быть ограничены продуктами, которые вы продаете, и их вариациями. Вы не хотите, чтобы сотни запросов в день попадали в вашу базу данных, потому что кто-то запросил предмет, который он даже не покупает. Ранжируйте и фильтруйте свои продукты по группам клиентов, SKU или другим фильтрам и предоставляйте удобный доступ с помощью кнопки «Посетить мой магазин», чтобы клиенты могли легко получить историю своих заказов для продаж, совершенных через ваш сайт.
Примеры инструментов: Improvado, Fivetran, Stitch, Airflow.
️Наш список из 16 лучших инструментов для сбора данных поможет вам выбрать лучший для вашего стека данных️
2. Хранение данных
С появлением облачных приложений и микросервисов большинство предприятий генерируют огромные объемы данных, которые необходимо хранить и управлять ими. Это сложная задача для традиционных реляционных баз данных, которые были разработаны для структурированных данных.
Базы данных NoSQL идеально подходят для неструктурированных данных, но их сложно развернуть в масштабе, особенно в гибридных средах.
Облачные провайдеры предлагают свои собственные управляемые решения, чтобы помочь с этим шагом. Например, AWS предлагает решение под названием Amazon Simple Storage Service (S3) для хранения объектов. Google предлагает BigQuery как часть облачной платформы. Обе службы предоставляют платформу с малой задержкой для хранения больших объемов данных в нужном масштабе.
Примеры инструментов: Snowflake, Databricks, AWS, GCP.
Прочтите наш список из 15 лучших инструментов для хранения данных, чтобы найти тот, который отвечает потребностям вашего бизнеса.
3. Преобразование данных
Преобразование данных — это процесс преобразования данных из одного формата или структуры в другой формат или структуру. Обычно преобразование данных выполняется с использованием методов извлечения, преобразования и загрузки (ETL).
Узнайте, как процесс ETL ускоряет ручные операции с данными
Преобразование данных имеет решающее значение в процессе интеграции данных, поскольку оно подготавливает и нормализует данные для дальнейшего анализа, составления отчетов и визуализации. Преобразование данных может быть выполнено для любого типа набора данных, независимо от его исходного формата или назначения.
Примеры инструментов: Improvado DataPrep, Dbt,MCDM, Matillon, Alteryx, RestApp.

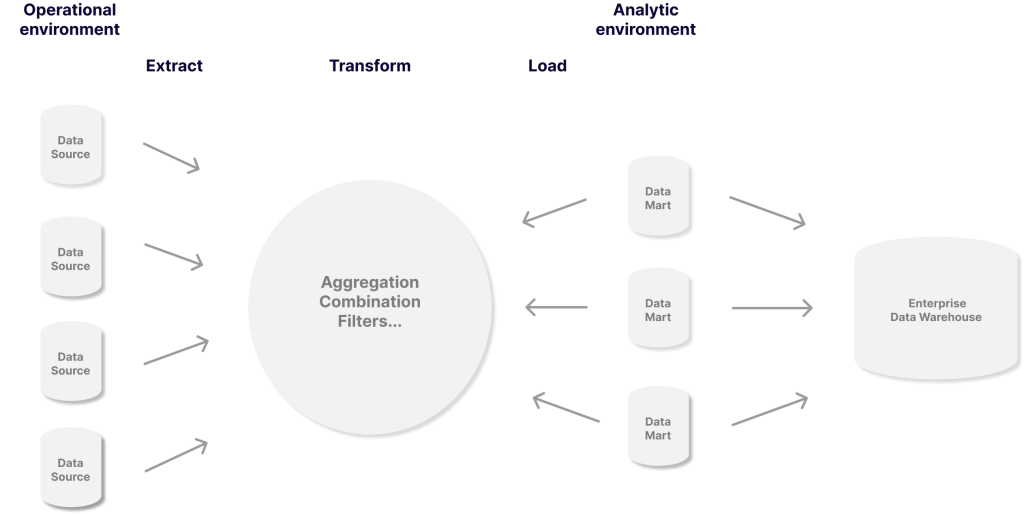
4. Аналитика данных
Уровень аналитики отвечает за агрегирование, анализ и представление данных пользователям. Уровень аналитики должен отвечать на такие вопросы, как:
- Каковы ключевые показатели для моего бизнеса?
- Как эти показатели меняются со временем?
- Как одна метрика влияет на другую?
В большинстве случаев это означает, что ваши данные будут преобразованы в графики, диаграммы, таблицы и другие визуальные представления, которые вы сможете сразу понять.
Некоторые современные платформы анализа данных имеют возможности, которые позволяют нетехническим людям изучать данные, не зная SQL.
Примеры инструментов: Looker, Tableau, Power BI.
«Без аналитики больших данных компании слепы и глухи, блуждая по сети, как олени по автостраде».
Джеффри Мур, автор и консультант.
5. Управление данными
Важно обеспечить четкое владение и процесс для каждого шага в конвейере данных. Это включает в себя установление стандартов для типов собираемых данных, способов их хранения и доступа к ним, а также процессов, обеспечивающих соблюдение и соблюдение этих стандартов.
Предположим, ваша цель — использовать данные для повышения операционной эффективности. Вы можете решить, что все ваши системы инвентаризации должны использовать одну и ту же систему штрих-кодов, чтобы вы могли получить полное представление о своей цепочке поставок без необходимости согласовывать различные коды или системы вручную.
Примеры инструментов: Atlan, Каталог данных Microsoft Azure, Informatica.
Обратная альтернатива ETL
Многие предприятия построили свои стеки данных с использованием технологий ETL. Эти технологии полезны для обработки больших объемов данных из нескольких источников и их перемещения в централизованное хранилище данных. Однако такой подход увеличивает сложность вашей инфраструктуры и замедляет время доставки.
В современном мире бизнес-решения все чаще принимаются на основе данных в режиме реального времени, будь то финансы, управление цепочками поставок или отношения с клиентами. Современный стек данных позволяет предоставлять информацию в режиме реального времени по всей организации, сохраняя ваши данные свежими, доступными и безопасными.
Именно здесь Reverse ETL может помочь вам создать современный стек данных, который обеспечивает ценность для бизнеса в реальном времени и устраняет риск сбоя из-за устаревшей информации.
Обратный ETL — это набор методов или процессов, которые синхронизируют данные из хранилища данных с операционными инструментами, такими как CRM, CMS, продукт или любой бизнес-инструмент (Slack, Google Sheet и т. д.).
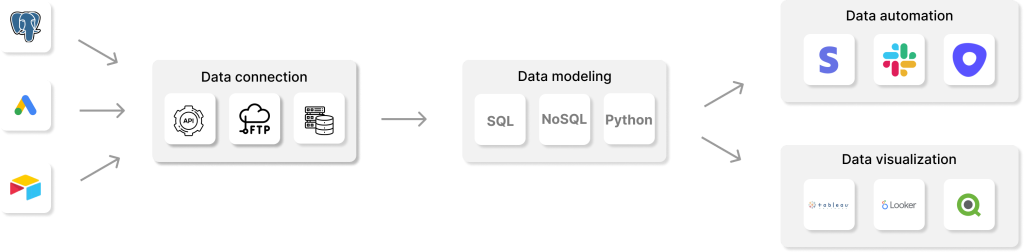
Идея, лежащая в основе этого процесса, заключается в создании единого комплексного источника данных, обеспечивающего целостное и надежное представление корпоративных данных. Обратные процессы ETL обычно используются для расширения существующих процессов ETL и выполняются через определенные промежутки времени. Кроме того, Reverse ETL позволяет использовать операционную аналитику.
Операционная аналитика против бизнес-аналитики
Операционная аналитика — это использование данных, прогнозной аналитики и инструментов бизнес-аналитики для получения информации о бизнес-операциях и создания действий в реальном времени благодаря активированным данным.
Бизнес-аналитика (BI) определяется Investopedia как процедурная и техническая инфраструктура, которая собирает, хранит и анализирует данные, полученные в результате деятельности компании.
Бизнес-аналитика фокусируется на анализе исторических данных.
Это поможет вам понять, что произошло и почему. Он используется для поддержки принятия бизнес-решений путем выявления закономерностей и тенденций посредством сравнения данных, эталонных показателей и других статистических методов.
Например, имеет смысл создать отчет, показывающий количество заказов, размещенных за определенный период времени, среднюю стоимость заказа и общее количество заказов.
Оперативная аналитика — это понятие, ориентированное на реальное время и будущее. Он фокусируется на том, что происходит сейчас, и на прогнозировании того, что произойдет дальше, чтобы помочь максимально использовать будущие шансы.
Подводя итог, Операционная аналитика показывает, где нам нужно действовать сейчас, а Бизнес-аналитика показывает, что было сделано неправильно и что нужно улучшить.
Оперативная аналитика больше не ограничивается цифровыми гигантами, такими как Google, Facebook и Netflix. Благодаря данным в режиме реального времени любая фирма, использующая современный стек данных, принимает больше решений, основанных на данных.
Требуется организационная эволюция
Когда компания внедряет современный стек данных, в способах управления данными происходят три основных изменения:
Переход от ИТ к бизнес-пользователям
В прошлом ИТ-отдел обрабатывал запросы данных от отделов и аналитиков. Разработка аналитических инструментов самообслуживания, таких как Tableau и Looker, позволила бизнес-пользователям напрямую получать доступ к данным и анализировать их.
Этот сдвиг имеет огромное значение для того, как компании организуют свои ресурсы вокруг данных.
От пакетной обработки к обработке данных в реальном времени
. По мере того, как конвейеры данных становятся более оптимизированными, а данные становятся более доступными в организации, время задержки между моментом возникновения события и моментом его анализа должно сокращаться.
Это означает, что все больше компаний обращают внимание на обработку своих данных в режиме реального времени, а не на агрегирование данных за более длительные периоды времени.
От разрозненных баз данных к федеративному владению (домены)
Традиционные архитектуры данных строятся на разрозненных базах данных и федеративном владении, что привело к распространению озер данных, киосков данных и хранилищ данных.
Эти архитектуры ориентированы на централизованные вычисления и инфраструктуру хранения. По мере развития и модернизации облачных сервисов должен меняться и подход к архитектуре стеков данных.
Современные архитектуры данных должны быть в состоянии справиться с масштабом и сложностью современных приложений, распределенных по целому ряду технологий. Именно здесь вступает в действие концепция сетки данных — новая архитектура, которая обеспечивает безопасный доступ ко всем типам данных, легкое управление и использование любым приложением в любом месте.
Положитесь на своих стейкхолдеров
Когда речь идет о современном стеке данных, есть три основных типа заинтересованных сторон.
Внутренние заинтересованные стороны
Это люди в вашей организации, которые будут использовать данные в своей повседневной работе.
Например, отдел продаж может быть заинтересован в том, какой доход приносит каждый клиент и как увеличить этот доход. Или, может быть, маркетинговая команда заинтересована в том, какие типы контента привлекают больше всего трафика на сайт.
Внутренние заинтересованные стороны должны иметь право голоса в том, какие данные вы собираете, как вы их структурируете и какие инструменты используете для их анализа.
Внешние заинтересованные стороны
Это люди не из вашей компании, но они все равно заинтересованы в вашем успехе.
Например, если ваш бизнес — это компания, предлагающая программное обеспечение как услугу (SaaS), то пользователи вашего продукта — это внешние заинтересованные стороны. Если ваш бизнес продает товары через Интернет и отправляет их по стране или миру, то клиенты и поставщики являются внешними заинтересованными сторонами.
Важно понимать, что им нужно от вас, чтобы вы могли предоставить эти данные правильно и эффективно.
Сторонние заинтересованные стороны
Это люди за пределами вашей организации, которые также предоставляют услуги вашей компании. Например, поставщиков сырья или ИТ-консультантов, помогающих настроить вашу технологическую инфраструктуру. Если вы хотите избежать слепых мух с точки зрения данных, вам необходимо освоить анализ данных. Это все больше потребует разработки данных за пределами ваших четырех стен.
Современный стек данных укрепляет отношения между компанией и ее заинтересованными сторонами за счет более эффективного обмена данными благодаря определенным доменам для каждой команды и возможности использовать их в среде без кода.
Домены данных укрепляют отношения между командами, поскольку все они работают в одной и той же области.
Например, маркетинговая команда хочет знать, сколько людей подписывается на их новый продукт или услугу и какой доход они получают после регистрации. Данные, сгенерированные продуктовой командой, важны для маркетинговой команды, потому что обе они работают в одном пространстве.
Вывод
Как видите, при настройке стека данных необходимо учитывать множество факторов. Учитывая все различные задействованные компоненты, это большое мероприятие, и может быть трудно обхватить руками все движущиеся части.
Понимание того, зачем вам нужен стек данных и какую пользу он принесет вашему бизнесу, позволит вам планировать на долгосрочную перспективу, установив четкие процессы и сроки реализации. Преимущества использования современного стека данных заключаются в том, что они перевешивают любые трудности, возникающие на этом пути, не только с точки зрения отдельных проектов и инициатив, но и с точки зрения создания прочной основы, которая поможет вам принимать более правильные решения в целом.