
Normalización de datos: conversión de números sin procesar en ingresos
Publicado: 2022-05-13Los datos están en el centro de todas las decisiones comerciales. Nos rodea a cada paso. Desafortunadamente, la información que obtiene directamente de las fuentes de datos a menudo no está estructurada, está fragmentada y es engañosa.
Probablemente esté sentado sobre una pila de datos aburridos que podrían ayudarlo a atraer clientes potenciales, mejorar su ROI y aumentar los ingresos.
La normalización de datos convertirá sus números sin procesar en información procesable que generará valor.
¿Qué es la normalización de datos?
Para usar algunas palabras grandes, la normalización de datos es el proceso de organizar los datos de tal manera que se ajusten a un rango específico o formas estándar. Ayuda a los analistas a adquirir nuevos conocimientos, minimizar la redundancia de datos, deshacerse de los duplicados y hacer que los datos sean fácilmente digeribles para un análisis posterior.
Sin embargo, tal redacción puede ser complicada y confusa, así que resumámoslo en un ejemplo simple e ilustrativo.
Imagina que eres un jardinero cosechando manzanas. Este año, has logrado cosechar 500 manzanas de 20 árboles . Sin embargo, tu vecino se jacta de haber recolectado 1000 manzanas y te llama pésimo jardinero.
Si comparas tus 500 manzanas con las 1000 manzanas de tu vecino, puede parecer que no eres un jardinero muy hábil. Pero tu vecino nunca te dijo que plantó cien manzanos para lograr tal rendimiento.
Si normaliza los datos, se revela que su vecino se encuentra en una situación desagradable. Con 500 manzanas de 20 árboles, cosechas 25 manzanas por árbol , mientras que tu vecino obtiene solo 10 manzanas por árbol. Entonces, ¿quién es un horrible jardinero ahora?
El análisis puede verse enturbiado por una gran cantidad de datos no normalizados, por lo que los árboles no pueden ver el bosque.
Aquí hay otro ejemplo usando datos de control de armas. Nos muestra lo fácil que es ser víctima de un sesgo cognitivo sin la normalización de datos.

Sin conocimientos normalizados, es casi imposible crear una imagen completa y tomar decisiones informadas sobre el tema investigado.
Conclusiones clave:
- La normalización de datos es un proceso de reorganización de datos en un conjunto de datos.
- Este proceso simplifica el análisis posterior y las operaciones de datos.
- La normalización de datos garantiza que obtenga una visión completa del tema investigado.
Ok, pero ¿cuándo necesitas normalizar los datos?
Los usuarios experimentan diferentes problemas como resultado de datos heterogéneos (datos con alta variabilidad de tipos y formatos de datos). Hay otros casos de uso en los que necesita normalizar los datos. Consideremos este tema desde la perspectiva de los analistas de marketing.
Lo primero y más importante es la unificación de las convenciones de nomenclatura. Por ejemplo, al recopilar datos de decenas de canales de marketing, los analistas a menudo encuentran las mismas métricas con diferentes nombres. Como resultado, los analistas enfrentan dificultades al mapear datos.
Por ejemplo, así es como un usuario de Reddit explica sus problemas con datos dispares.
Otro desafío es consolidar datos dispares, como monedas o zonas horarias, en una única fuente de verdad. Simplemente no puede crear un tablero detallado mientras su gasto publicitario se divide en dólares, euros, libras y algunas otras monedas.
Así es como otro vendedor describe este problema en Reddit.
Entonces, ¿cuándo es el momento adecuado para normalizar sus datos?
- Cuando las métricas coincidentes en su conjunto de datos tienen diferentes convenciones de nomenclatura.
- Cuando necesite hacer coincidir datos heterogéneos, como monedas, zonas horarias, formatos de fecha, etc.
- Cuando nota que algunos de sus datos son redundantes y necesita eliminarlos.
Términos que a menudo se confunden: normalización de datos frente a estandarización
En la transformación de datos, la estandarización y la normalización son dos términos diferentes que a menudo se confunden.
La normalización vuelve a escalar los valores de un conjunto de datos para que caigan en un rango de [0,1] . Este proceso es útil cuando necesita que todos los parámetros estén en una escala positiva.
La estandarización ajusta sus datos para que tengan una media de 0 y una desviación estándar de 1 . No tiene que caer en un rango específico y se ve mucho menos afectado por los valores atípicos.
Esta información es más que suficiente para que los analistas de marketing dejen de confundir los términos. No obstante, si quieres profundizar más en este tema, aquí puedes encontrar todas las diferencias entre ambos conceptos.
Cómo normalizar los datos y reunir sus conocimientos
En esencia, la normalización de datos requiere que cree un formato de datos estándar para todos los registros en su conjunto de datos. Su algoritmo debe almacenar todos los datos en un formato unificado sin tener en cuenta la entrada.
Estos son algunos ejemplos de normalización de datos:
- Mister HOLmES debe almacenarse como Mr. Holmes.
- Fifth Avenue Sf debe almacenarse como 5th Ave, San Francisco.
- El CTO debe almacenarse como director técnico.
La normalización de sus datos va de la mano con la normalización de la base de datos. Vamos a obtener una breve descripción de lo que es.
Normalización de la base de datos: una condición previa para obtener información depurada
La normalización de la base de datos es el proceso de organizar tablas y filas de datos dentro de una base de datos relacional.
El proceso incluye la creación y gestión de relaciones entre tablas. Mientras normalizan las bases de datos, los analistas y los ingenieros de datos confían en las reglas que ayudan a proteger los datos y los hacen más flexibles para un análisis posterior.
Todas las reglas se declaran mediante tipos de normalización de bases de datos o las denominadas "Formas normales".
Hay siete Formas Normales en total (las tres primeras son las más utilizadas):
- Primera forma normal (1 NF)
- Segunda forma normal (2 NF)
- Tercera Forma Normal (3 NF)
- Forma normal de Boyce Codd (BCNF)
- Cuarta Forma Normal (4 NF)
- Quinta forma normal (5 NF)
- Sexta Forma Normal (6 NF)
Repasemos todos estos formularios normales para aprender cómo ayudan a normalizar sus datos.
Primera Forma Normal (1FN)
La primera Forma Normal requiere una tabla de datos para cumplir con las siguientes condiciones:
- Cada celda de la tabla debe tener un solo valor.
- Cada registro debe ser único.
- Ninguna de las columnas debe contener valores ocultos.
Repasemos un ejemplo. Aquí tenemos dos registros de la tabla de empleados.

Las celdas Department_Name contienen más de un parámetro en una celda. Por lo tanto, violan la primera regla de la 1NF.
Debe dividir esta tabla en dos partes para normalizar su tabla y eliminar los grupos repetidos. Las tablas normalizadas se verán así:

Las formas normales segunda y tercera giran en torno a las dependencias entre las columnas de clave principal y las columnas que no son clave.
Segunda forma normal (2NF)
El requisito principal de la Segunda Forma Normal es que todos los atributos de la tabla dependan de la clave primaria. En otras palabras, todos los valores de las columnas secundarias deben depender de la columna principal.
Nota: una clave principal es un valor de columna único que ayuda a identificar un registro de la base de datos. Tiene algunas restricciones y atributos:
- Un valor de clave principal no puede ser NULL.
- Un valor de clave principal siempre debe ser único para cada tabla.
Además, la tabla ya debe estar en 1NF con todas las dependencias parciales eliminadas y colocadas en una tabla separada.
En esta etapa, una clave primaria compuesta se convierte en el problema más problemático.
Nota: una clave principal compuesta es una clave principal formada por dos o más columnas de datos.
Imaginemos que tiene una tabla que lleva un registro de los cursos que han tomado sus empleados. Diferentes empleados pueden matricularse en el mismo curso. Es por eso que necesitará una clave compuesta para identificar el registro único. La columna Fecha será el parámetro adicional para su clave compuesta. Echa un vistazo al ejemplo:
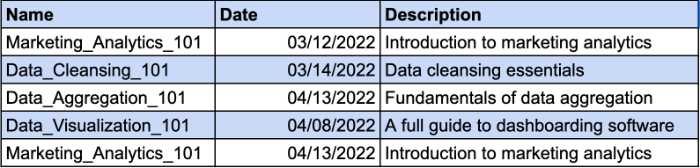
Sin embargo, la columna Descripción depende funcionalmente de la columna Nombre. Si modifica el nombre del curso, también debe cambiar la descripción. Por lo tanto, deberá crear una tabla separada para que la descripción del curso cumpla con los requisitos de 2NF.

Así es como puede darle a la descripción del curso una clave separada y dejar de usar una clave compuesta.
Tercera Forma Normal (3NF)
La tercera forma normal requiere que todas las columnas sin clave en su tabla dependan directamente de la clave principal. En otras palabras, si elimina alguna de las columnas que no son clave, las columnas restantes aún deberían proporcionar un identificador único para cada registro.
Estos son los principales requisitos de la 3NF:
- Todas las tablas cumplen con los requisitos de 2NF.
- Las columnas de clave no principal solo deben depender de las columnas de clave principal.
- Las tablas no tienen dependencia funcional transitiva.
La principal diferencia entre 2NF y 3NF es que en 3NF no hay dependencias transitivas. Existe una dependencia transitiva cuando la columna sin clave depende de otra columna sin clave.
Nota: Una dependencia transitiva es una relación indirecta entre valores dentro de la misma tabla que provoca una dependencia funcional. Una dependencia funcional establece restricciones particulares entre atributos. En esta relación, el atributo A determina el valor del atributo B, mientras que B determina el valor de A.
Eche un vistazo al siguiente ejemplo:

Aquí, la identificación del empleado determina la identificación del departamento de nuestro ejemplo anterior, mientras que la identificación del departamento determina el nombre del departamento. Aquí es donde ocurre una dependencia indirecta entre la identificación del empleado y el nombre del departamento.
Para cumplir con los requisitos de 3NF, debemos dividir la tabla en varias piezas.
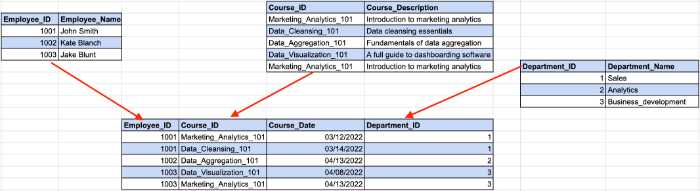
Con esta estructura, todas las columnas sin clave dependen únicamente de la clave principal.
Aunque hay siete Formas Normales, la base de datos se considera normalizada después de cumplir con los requisitos de 3NF. Haremos una descripción general rápida de las formas normales restantes para cubrir el tema hasta el final.
Forma normal de Boyce-Codd (BCNF)
Es una versión más robusta del 3NF. Una tabla BCNF debe cumplir con todas las reglas de 3NF y no tener múltiples claves candidatas superpuestas.
Cuarta Forma Normal (4NF)
La base de datos se considera una 4NF si alguna de sus instancias contiene dos o más entradas de datos independientes y de varios valores.
Quinta Forma Normal (5NF)
Una tabla cae en la quinta forma normal si cumple con los requisitos de 4NF y no se puede dividir en tablas más pequeñas sin perder datos.
Sexta Forma Normal (6NF)
La sexta forma normal tiene por objeto descomponer las variables de relación en componentes irreducibles. Puede ser importante cuando se trata de variables temporales u otros datos de intervalo.
Eso es todo para la normalización 101 de la base de datos. Ahora que sabe cómo funciona todo, puede comprender mejor los beneficios que la normalización de datos aporta a sus conocimientos.
¿Por qué es importante normalizar los datos?
Como ya mencionamos, el principal objetivo y beneficio de la normalización de datos es reducir la redundancia de datos y las inconsistencias en las bases de datos. Cuanta menos duplicación tenga, menos errores y problemas pueden ocurrir durante la recuperación de datos.
Sin embargo, existen beneficios menos obvios que ayudan a los analistas de datos en su flujo de trabajo.
El mapeo de datos ya no es una pérdida de tiempo
Si alguna vez ha tenido que lidiar con datos no normalizados, sabe que el proceso de mapear datos de varias tablas en una sola es bastante tedioso.
Requiere unir varias tablas, lidiar con duplicados y limpiar muchas entradas de datos vacías.
Por supuesto, puede normalizar los datos manualmente escribiendo consultas SQL o scripts de Python. Sin embargo, las herramientas de mapeo de datos con capacidades de normalización de datos automatizadas acelerarán el proceso.
Por ejemplo, Oracle Integration Cloud ofrece funcionalidades de mapeo de datos. Después de normalizar los datos en la nube, la herramienta crea metadatos para los esquemas de origen y crea un registro uno a uno para cada objeto de datos en el esquema de destino.
Los analistas que trabajan con conocimientos de marketing tienen sus propias gemas ocultas. El MCDM (Marketing Common Data Model) de Improvado es una navaja suiza para la normalización de datos de marketing y ventas. La herramienta unifica convenciones de nomenclatura dispares, normaliza sus conocimientos y cierra la brecha entre las fuentes de datos y su destino sin necesidad de acciones manuales.
️ Encuentre las herramientas de mapeo de datos adecuadas para sus necesidades con nuestra extensa lista ️
Use el almacenamiento de datos de manera más eficiente
Cada día que pasa, las empresas recopilan más y más datos que ocupan espacio de almacenamiento. Ya sea que use almacenamiento en la nube o un almacén de datos local, debe usarlo de manera efectiva.
Por ejemplo, 100 TB de datos almacenados en AWS S3 le costarán $2580 por mes. Además, Amazon te cobrará por cada consulta que realices sobre tus datos. Decenas de gigabytes de datos redundantes no solo aumentarán su factura por los servicios de almacenamiento, sino que también harán que pague por el análisis de información sin sentido.
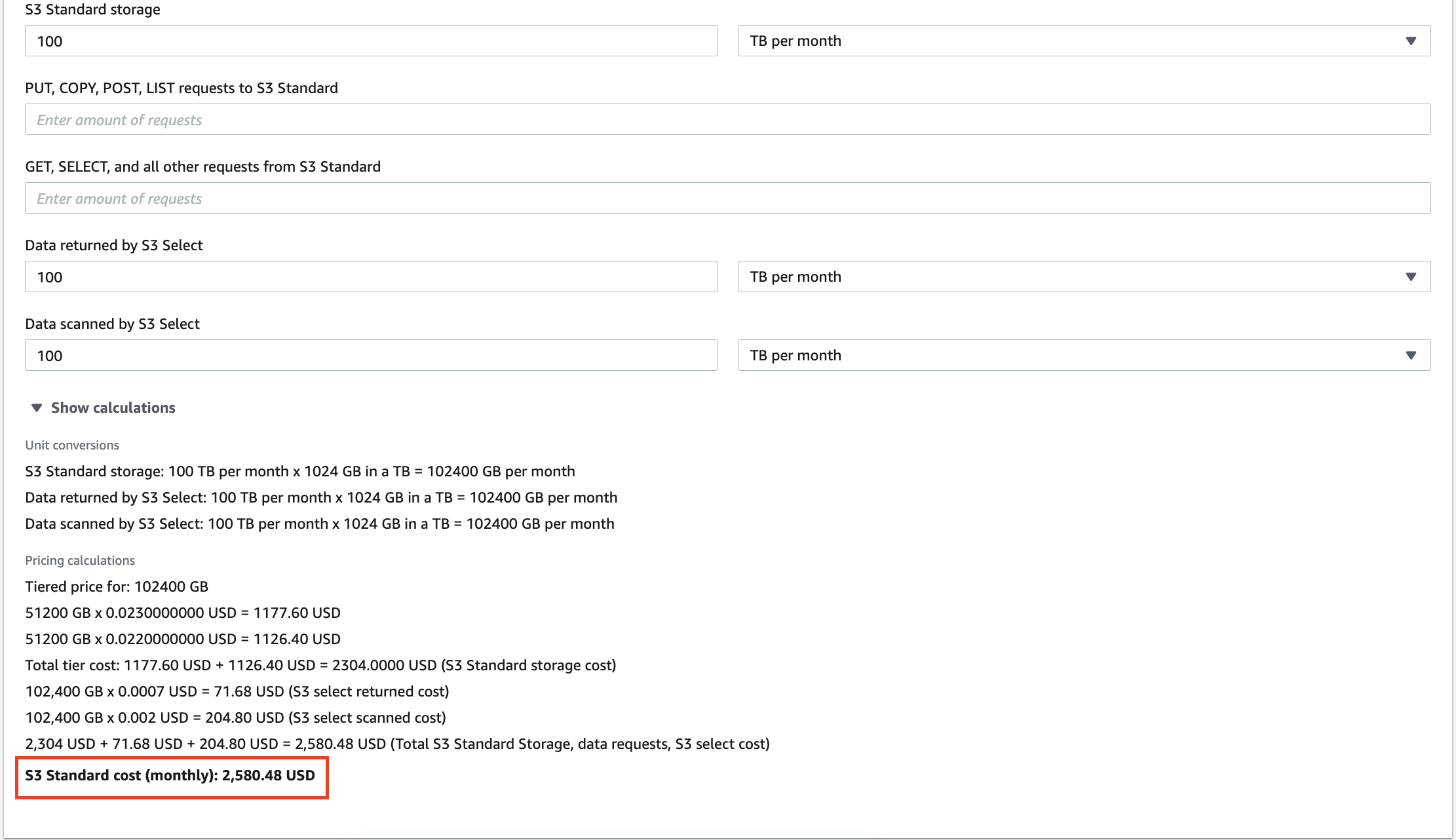
Escalar los almacenes de datos locales también es costoso, por lo que eliminar la información innecesaria puede ayudarlo a reducir los costos operativos y el TCO (costo total de propiedad).

Reduzca el tiempo de obtención de conocimientos
Además de la reducción de costes, los analistas también pueden aumentar la productividad de sus análisis.
Ejecutar consultas en terabytes de datos lleva tiempo. Mientras su sistema procesa la consulta, puede tomar una taza de café y hablar de política con sus colegas. Pero es una pena cuando el resultado de la consulta no tiene sentido porque tenía algunas inconsistencias en su conjunto de datos.
Con datos normalizados, siempre obtiene el resultado esperado, pero sin sorpresas como "N/A", "NaN", "NULL", etc. Además, el sistema realiza sus consultas más rápido cuando analiza solo los datos relevantes. Quién sabe, tal vez la próxima vez obtenga la salida antes de que su máquina de café haga su capuchino.
Cree tableros en los que pueda confiar
La visualización de datos es la mejor manera de crear una imagen completa de sus esfuerzos de análisis. Sin embargo, los tableros carecen de valor si los crea a partir de datos rigurosos. El tablero no reflejará el estado real de las cosas si lo alimenta con duplicados.
Es por eso que la normalización de datos es una prioridad máxima si desea explicar conceptos complejos o indicadores de rendimiento a través del prisma de gráficos y barras coloridos.
Cómo normalizar los datos en diferentes entornos
Dado que los analistas de datos trabajan con diferentes herramientas, explicaremos cómo normalizar los datos en los entornos más demandados del mercado actual.
Cómo normalizar datos en Python
Los científicos y analistas de datos que trabajan con Python usan varias bibliotecas para manipular datos y ordenarlos. Aquí están los más populares entre ellos:
- pandas
- entumecido
- TensorFlow
Revisaremos algunas de las funcionalidades de estas bibliotecas que pueden ayudarlo a acelerar su proceso de normalización de datos.
Eliminación de columnas en su conjunto de datos
Los datos sin procesar a menudo contienen categorías excesivas o innecesarias. Por ejemplo, está trabajando con un conjunto de datos de métricas de marketing que incluyen impresiones, CPC, CTR, ROAS y conversiones, pero solo necesita conversiones de esta tabla.
Si todo, además de las conversiones, no es importante para el análisis, debe eliminar las columnas excesivas. Pandas ofrece una manera fácil de eliminar columnas de un conjunto de datos con la función drop().
Primero, debe definir la lista de columnas que desea eliminar. En nuestro caso, se verá así:
column_drop_list = ['Impresiones, 'CPC', 'CTR', 'ROAS']
Entonces, necesitas ejecutar la función:
dataframe_name.drop(column_drop_list, inplace=True, axis=1)
En esta línea de código, el primer parámetro representa el nombre de nuestra lista de columnas. Establecer el parámetro inplace en True significa que Pandas aplicará los cambios directamente a su objeto. El tercer parámetro indica si eliminar etiquetas o columnas del marco de datos ('0' representa etiquetas, '1' representa columnas).
Después de verificar el conjunto de datos nuevamente, verá que todas las columnas redundantes se eliminaron correctamente.
Limpieza de campos de datos
Otro paso es ordenar los campos de datos. Ayuda a aumentar la coherencia de los datos y obtener datos en un formato estandarizado.
El principal problema aquí es que no puede estar seguro de que la API de una plataforma de marketing transfiera datos 100% precisos. Aún podría encontrar caracteres fuera de lugar o datos engañosos en el futuro.
Una sola campaña de marketing solo puede tener una cantidad de impresiones. Es por eso que necesitamos separar los números valiosos de otros caracteres.
Las expresiones regulares (regex) pueden ayudarlo a identificar todos los dígitos dentro de su conjunto de datos. Este generador de expresiones regulares lo ayudará a crear una expresión regular para sus necesidades y probarla de inmediato.
Luego, con la ayuda de la función str.extract(), podemos extraer los datos requeridos del conjunto de datos como columnas.
true_impressions = dataframe_name.str.extract(your_regex), expandir = False)
Finalmente, es posible que deba convertir su columna a una versión numérica. Dado que todas las columnas del marco de datos tienen el tipo de objeto, convertirlo en un valor numérico simplificará los cálculos posteriores. Puede hacer esto con la ayuda de la función pd.to_numeric().
Cambiar el nombre de las columnas en el marco de datos
Las fuentes de datos a menudo transfieren columnas con nombres que los analistas no pueden entender. Por ejemplo, CTR podría llamarse C_T_R_final por alguna razón.
Otro problema se revela cuando combina datos de diferentes fuentes y los analiza como un todo. Mientras que la primera fuente de datos se refiere a las impresiones como diablillos, otra lo llama vistas. Esto dificulta el cálculo y la creación de una imagen holística en todas las fuentes de datos.
Es por eso que necesita cambiar el nombre de sus columnas para estructurar todo.
Primero, cree un diccionario con los nombres futuros de sus columnas. Supongamos que tenemos impresiones de Google Ads y Facebook Ads con diferentes convenciones de nomenclatura. En este caso, nuestro diccionario se verá de la siguiente manera:
new_clmn_names = {'Imps' : 'Impresiones de Google Ads',
'Vistas': 'Impresiones de anuncios de Facebook'}
Luego, debe usar la función de cambio de nombre () en su marco de datos:
dataframe_name.rename(columns=new_clmn_names, inplace=True)
Ahora, sus columnas tendrán nombres asignados en el diccionario.
Pandas tiene muchas más funciones diferentes que pueden ayudarlo a normalizar los datos. Recomendamos leer la documentación oficial para comprender mejor otras funcionalidades.
Cómo normalizar datos en Excel
Excel o Google Sheets es una poderosa herramienta amada por muchos analistas debido a su facilidad de uso y amplias capacidades. No hay duda de que los lenguajes de programación, como R o Python, tienen más funciones que ofrecer, pero las hojas de cálculo hacen un gran trabajo al analizar datos.
Sin embargo, sus tablas pueden contener datos heterogéneos y Excel proporciona un conjunto de herramientas para normalizar la información.
Recortar espacios adicionales
Identificar espacios excesivos en una tabla grande es una pérdida de tiempo cuando se hace manualmente. Afortunadamente, Excel y Google Sheets tienen una función TRIM que permite a los analistas eliminar espacios adicionales en un conjunto de datos con una sola función. Eche un vistazo al ejemplo a continuación.

Como puede ver, los datos de entrada tienen un gran espacio en blanco entre las palabras. Con la función TRIM, los datos se colocan en el formato correcto.

Eliminar filas de datos vacías en el conjunto de datos
Las celdas vacías pueden convertirse en una verdadera pesadilla durante el análisis. Es por eso que siempre debes tratar con ellos de antemano. Así es como se hace.
- Elija todas las celdas y haga clic en la pestaña "Datos" en la barra de herramientas.

- Haga clic en el botón "Ordenar rango por columna (Z a A)" en el menú Ordenar rango.
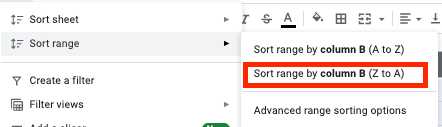
- Ahora tiene todas las filas vacías en la parte inferior de su tabla, por lo que simplemente puede seleccionarlas y eliminarlas.
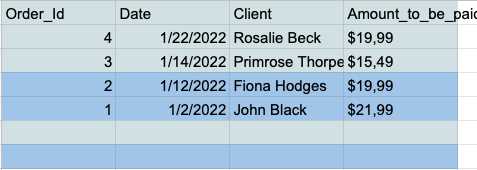
Eliminar duplicados
Las entradas de datos duplicadas son un problema común para los analistas que trabajan en Excel o Google Sheets. Es por eso que estas herramientas tienen una función dedicada para eliminar duplicados de una manera rápida y sencilla.
Google Sheets tiene una función ÚNICA que le permite mantener solo datos únicos en su tabla.
Suponga que tiene esta tabla simple con las columnas Nombre y Edad que contienen varios duplicados.

Puede obtener una tabla limpia sin entradas duplicadas alimentando su conjunto de datos a la función ÚNICA.

Normalización de mayúsculas y minúsculas
Después de importar datos de archivos de texto, a menudo encontrará mayúsculas y minúsculas inconsistentes en nombres o títulos. Puede corregir fácilmente sus datos en Excel o Google Sheets utilizando las siguientes funciones:
- LOWER() - Convierte todo el texto en minúsculas.
- UPPER() - Convierte todo el texto en mayúsculas.
- PROPER() - Convierte todo el texto en mayúsculas y minúsculas.

Dependiendo de su caso de uso particular, hay muchas formas de normalizar los datos de Excel o Google Sheets. Estas guías arrojan más luz sobre la normalización de datos de Excel:
- Técnicas de limpieza de datos de Excel
- Consejos de normalización de datos de Excel de Microsoft
Herramientas de normalización de datos automatizadas
Los lenguajes de programación ofrecen un amplio conjunto de herramientas para normalizar sus datos. Sin embargo, la normalización manual de datos tiene sus limitaciones.
En primer lugar, los analistas necesitan sólidos conocimientos de ingeniería y experiencia práctica con las bibliotecas requeridas. Los ingenieros y científicos de datos son talentos muy deseables, y sus cheques de pago suelen ser astronómicos.
Además, la codificación lleva tiempo y, a menudo, es propensa a errores. Por lo tanto, una revisión de seguimiento del conjunto de datos analizado es imprescindible. Eventualmente, el proceso de análisis puede llevar mucho más tiempo del previsto.
Las herramientas automatizadas ahorran tiempo a los analistas y ofrecen resultados más precisos. Puede optimizar sus datos con la herramienta de normalización y obtener información detallada en minutos, no en días.
Consideremos el ejemplo de Improvado. Improvado es una plataforma ETL de ingresos que ayuda a los analistas de marketing y vendedores a alinear sus datos dispares y almacenar información en un solo lugar.
La plataforma recopila datos de más de 300 fuentes y ayuda a los analistas a normalizarlos sin esfuerzo. El mercado actual de herramientas de marketing y ventas está fragmentado y las diferentes plataformas usan diferentes convenciones de nomenclatura para métricas similares.
El modelo de datos comunes de marketing (MCDM) de Improvado es un modelo de datos unificado que proporciona mapeo, deduplicación y unión automatizados entre canales de fuentes de datos populares. Además, une y estandariza las fuentes de medios pagados, transfiriendo automáticamente información lista para el análisis a su almacén de datos.
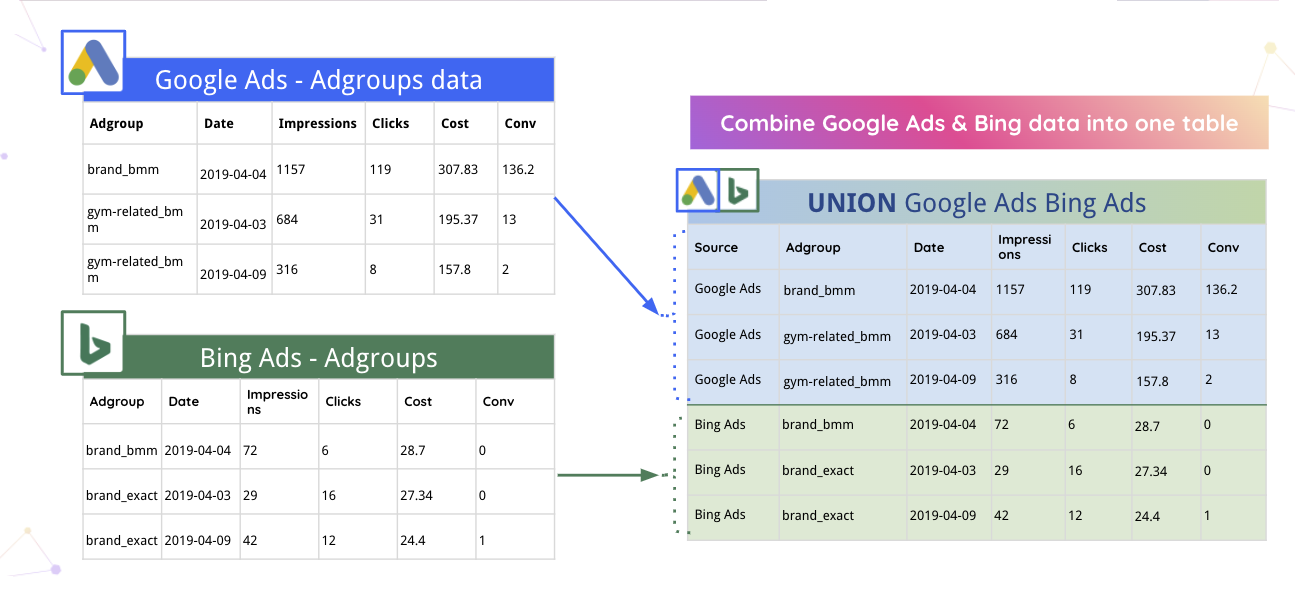
Por ejemplo, Improvado puede fusionar automáticamente los datos de Google Ads y Bing en una tabla.
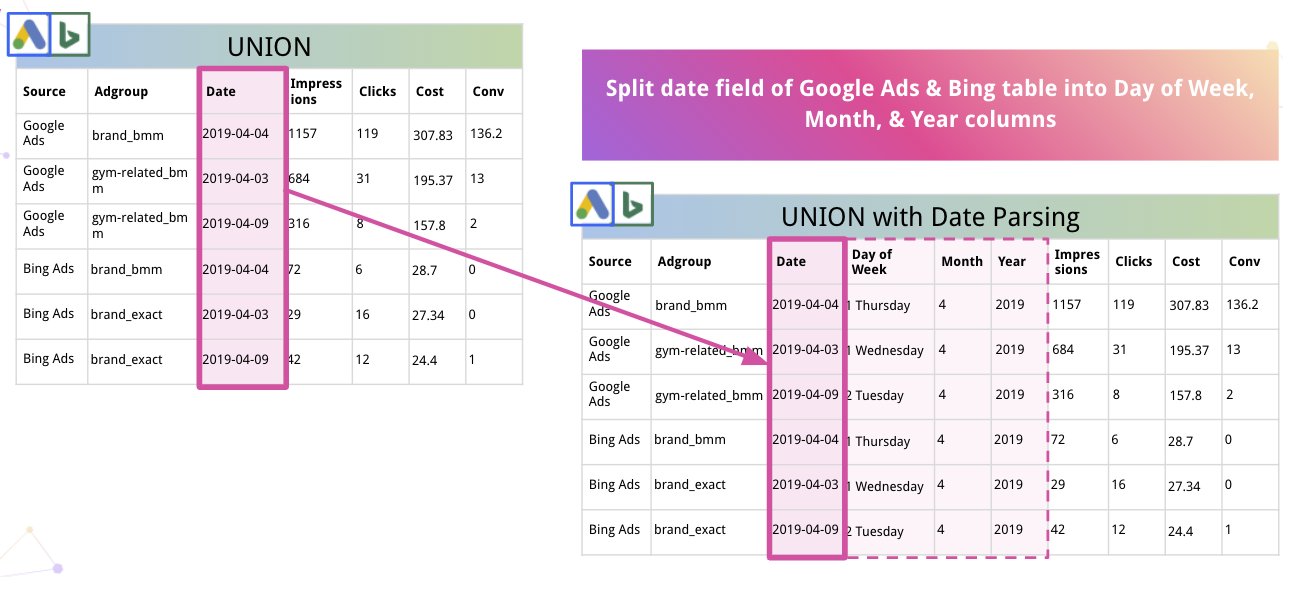
Además, la plataforma puede analizar automáticamente los datos y convertirlos a un formato adecuado. Por ejemplo, así es como Improvado divide la fecha en columnas de día de la semana, mes y año.
Improvado va aún más allá y permite a los analistas analizar automáticamente los códigos de seguimiento de Adobe Analytics en su sitio web. Puede extraer el ID de grupo de anuncios incrustado del código de seguimiento sin manipulaciones manuales.
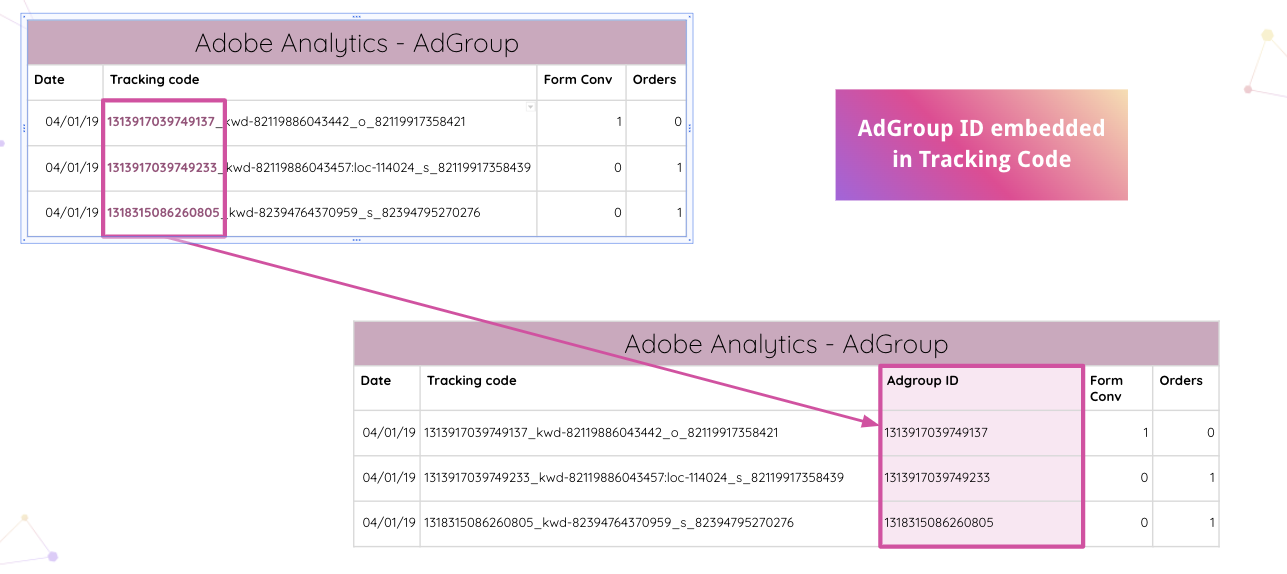
Luego, los analistas pueden combinar hojas de cálculo internas con clasificaciones y compararlas según la identificación de la red.
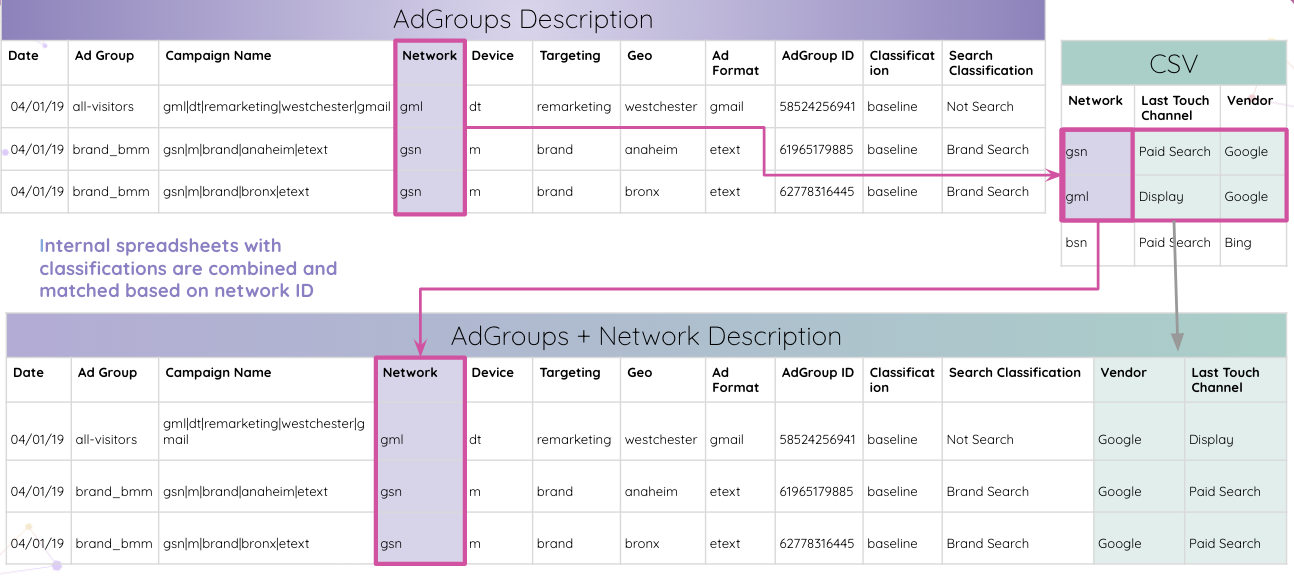
Eventualmente, los analistas obtienen todas las tablas que coinciden con el ID de grupo de anuncios y las combinan en la tabla de resultados final.

Ese fue solo uno de los muchos casos de uso en los que Improvado puede normalizar los datos y brindar información de manera digerible para futuras investigaciones.
Con todos los conocimientos en un solo lugar, la plataforma puede simplificarlos a cualquier herramienta de visualización de su elección. Los datos depurados y estructurados facilitan mucho la creación de un panel completo de canales cruzados. Por ejemplo, aquí hay un tablero de Data Studio basado en los conocimientos de Improvado:
Normalice los datos de marketing y ventas con Improvado
La normalización de datos lleva tiempo, pero siempre vale la pena obtener información clara. ¿Por qué perder el tiempo en la normalización de datos si puede sumergirse directamente en el análisis y reducir drásticamente su tiempo de conocimiento?
Improvado desenreda su red de datos de ingresos, reduce el tiempo dedicado a la manipulación manual de datos y garantiza la mayor granularidad de los conocimientos. Con este sistema ETL, puede analizar datos confiables y crear paneles en tiempo real que demuestren la efectividad de su inversión en marketing. Programe una llamada para obtener más información.
Descubra cómo una plataforma ETL de ingresos puede ayudarlo a superar sus objetivos de marketing y ahorrar tiempo a sus analistas.
